用编码器做PCA
- 隐层的特点:线性激活函数
代码:
预先声明的函数和包
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# Common imports
import numpy as np
import os
import sys
# to make this notebook's output stable across runs
def reset_graph(seed=42):
tf.reset_default_graph()
tf.set_random_seed(seed)
np.random.seed(seed)
# To plot pretty figures
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "autoencoders"
def save_fig(fig_id, tight_layout=True):
path = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID, fig_id + ".png")
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format='png', dpi=300)- 模型:
#Build 3D dataset
import numpy as np
import numpy.random as rnd
rnd.seed(4)
m = 200
w1, w2 = 0.1, 0.3
noise = 0.1
angles = rnd.rand(m) * 3 * np.pi / 2 - 0.5
data = np.empty((m, 3))
data[:, 0] = np.cos(angles) + np.sin(angles)/2 + noise * rnd.randn(m) / 2
data[:, 1] = np.sin(angles) * 0.7 + noise * rnd.randn(m) / 2
data[:, 2] = data[:, 0] * w1 + data[:, 1] * w2 + noise * rnd.randn(m)
#Normalize the data:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(data[:100])
X_test = scaler.transform(data[100:])
#autoencoder
import tensorflow as tf
reset_graph()
n_inputs = 3
n_hidden = 2 # codings
n_outputs = n_inputs
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
hidden = tf.layers.dense(X, n_hidden)
outputs = tf.layers.dense(hidden, n_outputs)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
n_iterations = 1000
codings = hidden
with tf.Session() as sess:
init.run()
for iteration in range(n_iterations):
training_op.run(feed_dict={X: X_train})
codings_val = codings.eval(feed_dict={X: X_test})
#fig = matplotlib.pyplot.gcf()
#fig.set_size_inches(18.5, 10.5)
fig = plt.figure(figsize=(12,10))
plt.plot(codings_val[:,0], codings_val[:, 1], "b.")
plt.xlabel("$z_1$", fontsize=18)
plt.ylabel("$z_2$", fontsize=18, rotation=0)
save_fig("linear_autoencoder_pca_plot")
plt.show()输出:
Saving figure linear_autoencoder_pca_plot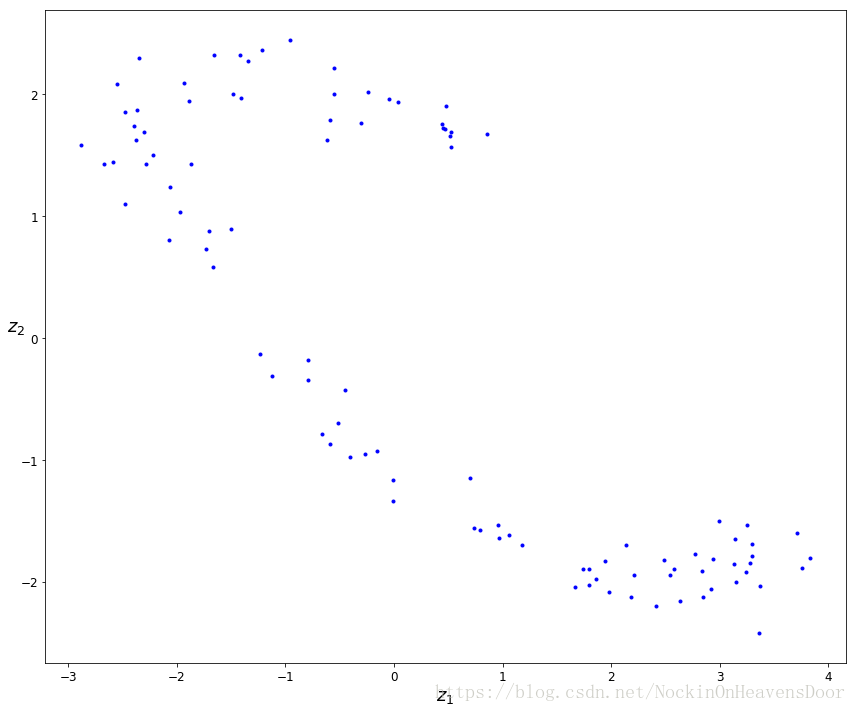
堆栈编码器(stacked autoencoder)
特点:即有很多隐层来叠加,结构如图:
代码:
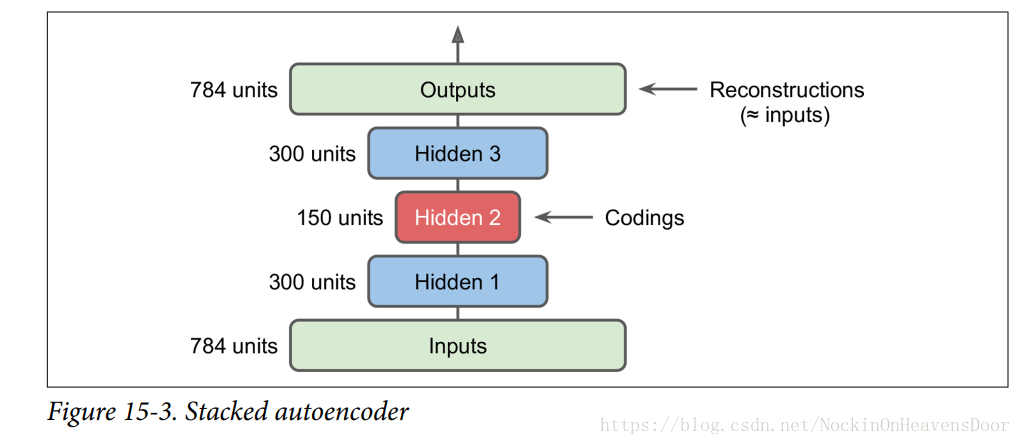
#build a stacked Autoencoder with 3 hidden layers and 1 output layer (ie. 2 stacked Autoencoders).
#We will use ELU activation, He initialization and L2 regularization.
#下载数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data")
reset_graph()
from functools import partial
n_inputs = 28 * 28 # for mnist
n_hidden1 = 300
n_hidden2 = 150 #codings
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
l2_reg = 0.0001
X = tf.placeholder(tf.float32,shape=[None,n_inputs])
he_init = tf.contrib.layers.variance_scaling_initializer()# He initialization
#等价于
#he_init = lambda shape, dtype=tf.float32: tf.truncated_normal(shape, 0., stddev=np.sqrt(2/shape[0]))
l2_regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
my_dense_layer = partial(tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=he_init,
kernel_regularizer=l2_regularizer)
hidden1 = my_dense_layer(X, n_hidden1)
hidden2 = my_dense_layer(hidden1, n_hidden2)
hidden3 = my_dense_layer(hidden2, n_hidden3)
outputs = my_dense_layer(hidden3, n_outputs,activation=None)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
##
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
#tf.add_n :Adds all input tensors element-wise.
loss = tf.add_n([reconstruction_loss] + reg_losses)
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
#训练(y_batch is not used). This is unsupervised training.
n_epochs = 5
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}%".format(100 * iteration // n_batches), end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch})
loss_train = reconstruction_loss.eval(feed_dict={X:X_batch})
print("\r{}".format(epoch),"Train MSE:",loss_train)
saver.save(sess,"./my_model_all_layers.ckpt")输出:
0 Train MSE: 0.020855438
1 Train MSE: 0.011372581
2 Train MSE: 0.010224564
3 Train MSE: 0.009900457
49% Train MSE: 0.010375758
#可视化其中的原始图 和重构图
def show_reconstructed_digits(X, outputs, model_path = None, n_test_digits = 2):
with tf.Session() as sess:
if model_path:
saver.restore(sess,model_path)
X_test = mnist.test.images[:n_test_digits]
outputs_val = outputs.eval(feed_dict={X:X_test})
fig = plt.figure(figsize=(8, 3 * n_test_digits))
for digit_index in range(n_test_digits):
plt.subplot(n_test_digits, 2, digit_index * 2 + 1)
plot_image(X_test[digit_index])
plt.subplot(n_test_digits, 2, digit_index * 2 + 2)
plot_image(outputs_val[digit_index])
#保存图
show_reconstructed_digits(X, outputs, "./my_model_all_layers.ckpt")
save_fig("reconstruction_plot")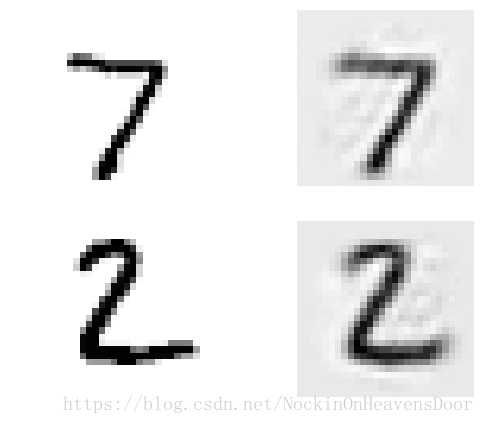
权重绑定(tying weights)
即把解码层(decoder layers)与编码层(encoder layers)的权重绑定在一起,即公用这个权值。
优点:防止过拟合、减半权重参数。
设编码器有
层(不包括input layer),用
表示第
层的连接权重,即第一层是第一隐层,
层是coding层,最后一层
是output layers。解码层的权值可以设为:
注:绑定的权重只训练一次,在另一端不是变量,另一端做训练时不进行正则化;偏置值不进行绑定,也不加入参数正则化。
代码:
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 150 # codings
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
l2_reg = 0.0005
activation = tf.nn.elu
regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
initializer = tf.contrib.layers.variance_scaling_initializer()
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
weights1_init = initializer([n_inputs, n_hidden1])
weights2_init = initializer([n_hidden1,n_hidden2])
weights1 = tf.Variable(weights1_init, dtype=tf.float32, name="weights1")
weights2 = tf.Variable(weights2_init, dtype=tf.float32, name="weights2")
# 权值绑定
weights3 = tf.transpose(weights2,name="weights3")
weights4 = tf.transpose(weights1,name="weights4")
bias1 = tf.Variable(tf.zeros(n_hidden1),name="biases1")
bias2 = tf.Variable(tf.zeros(n_hidden2),name="biases2")
bias3 = tf.Variable(tf.zeros(n_hidden3),name="biases3")
bias4 = tf.Variable(tf.zeros(n_outputs),name="biases4")
hidden1 = activation(tf.matmul(X,weights1) + bias1)
hidden2 = activation(tf.matmul(hidden1,weights2) + bias2)
hidden3 = activation(tf.matmul(hidden2, weights3) +bias3)
outputs = tf.matmul(hidden3,weights4) + bias4
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) #MSE
reg_loss = regularizer(weights1) + regularizer(weights2) #dont regular the bias
loss = reconstruction_loss + reg_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 5
batch_size = 150
with tf.Session() as sess:
#启动流程图
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
#
print("\r{}%".format(100 * iteration // n_batches),end="")
sys.stdout.flush()
x_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(train_op,feed_dict={X:x_batch})
#重构的损失才是MSE,用最后一个batch调看
loss_train = reconstruction_loss.eval(feed_dict={X:x_batch})
print("\r{}".format(epoch),"Train MSE:",loss_train)
saver.save(sess,"./my_model_tying_weights.ckpt")输出:
0 Train MSE: 0.015624228
1 Train MSE: 0.016569963
29% Train MSE: 0.017799906
3 Train MSE: 0.017334452
4 Train MSE: 0.018668532
show_reconstructed_digits(X, outputs, "./my_model_tying_weights.ckpt")同时训练几个编码器然后叠在一起
训练一个编码器,我们可以这样训练,用一个编码器训练第一隐层和输入层的权重,用另一个个编码器训练第二隐层和第三隐层的权重,然后把这几个训练好的层叠加在一起,成为一个编码器。如图:
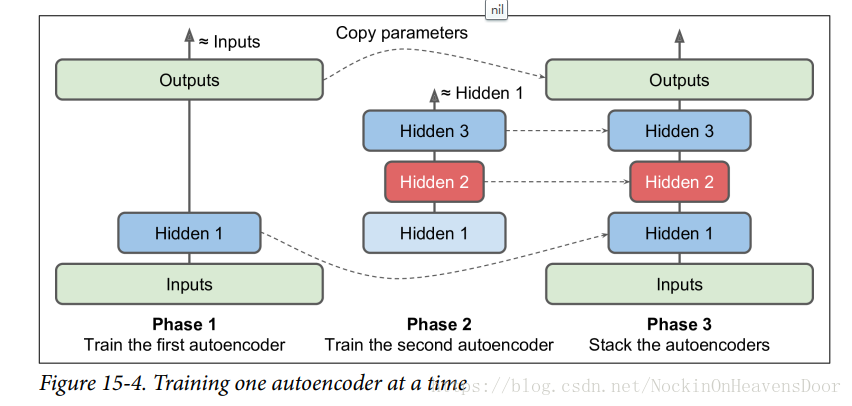
这个图的虚线已经表明是在拷贝训练好的参数,叠加在一起就成了训练好的一个堆栈编码器。
这个同样效果的流程可以是这样的,即在一个流程图上来训练几个编码器,如下图:
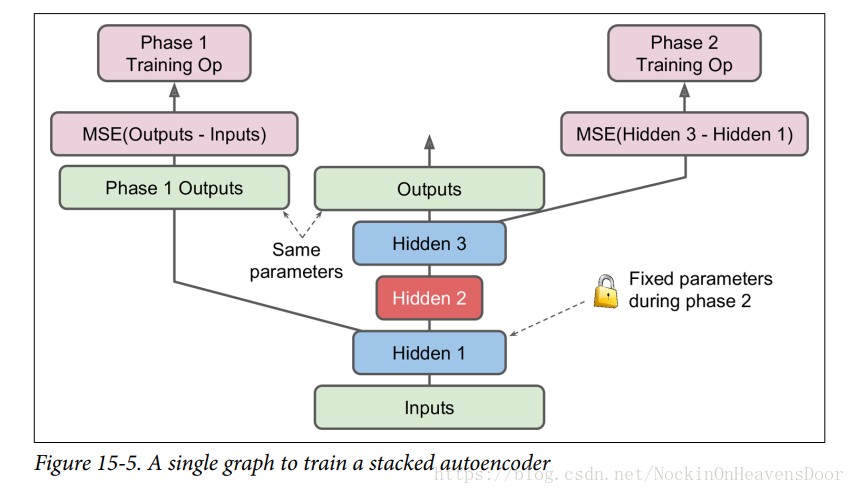
图的中间是一个上例的堆栈编码器,但是训练方式不一样,这中间的编码器是在训练完成后来使用。
第一个编码器:即训练的第一阶段,直接用第一隐层和输出层做编码器,得到隐层一和输出层的权重;同样,第二个编码器,训练的第二阶段,隐层1作为输出,coding层为隐层2,隐层3作为output层,得到隐层2和3的权重,最后叠加。注:第二阶段训练需要freeze hidden layer1,即保持权值的梯度计算不包括此外的层的权重参数。
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 150
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
l2_reg = 0.0001
activation = tf.nn.elu
regularizer = tf.contrib.layers.l2_regularizer(l2_reg)
initializer = tf.contrib.layers.variance_scaling_initializer()
X = tf.placeholder(tf.float32, [None,n_inputs])
weights1_init = initializer([n_inputs, n_hidden1])
weights2_init = initializer([n_hidden1, n_hidden2])
weights3_init = initializer([n_hidden2, n_hidden3])
weights4_init = initializer([n_hidden3, n_outputs])
weights1 = tf.Variable(weights1_init, dtype=tf.float32, name="weights1")
weights2 = tf.Variable(weights2_init, dtype=tf.float32, name="weights2")
weights3 = tf.Variable(weights3_init, dtype=tf.float32, name="weights3")
weights4 = tf.Variable(weights4_init, dtype=tf.float32, name="weights4")
bias1 = tf.Variable(tf.zeros([n_hidden1]), name="bias1")
bias2 = tf.Variable(tf.zeros([n_hidden2]), name="bias2")
bias3 = tf.Variable(tf.zeros([n_hidden3]), name="bias3")
bias4 = tf.Variable(tf.zeros([n_outputs]), name="bias4")
hidden1 = activation(tf.matmul(X,weights1) + bias1)
hidden2 = activation(tf.matmul(hidden1,weights2) + bias2)
hidden3 = activation(tf.matmul(hidden2, weights3) + bias3)
outputs = activation(tf.matmul(hidden3, weights4) + bias4)
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
optimizer = tf.train.AdamOptimizer(learning_rate)
with tf.name_scope("phase1"):
# 直接约过第二第三隐层
phase1_outputs = tf.matmul(hidden1,weights4) + bias4
phase1_reconstruction_loss = tf.reduce_mean(tf.square(phase1_outputs - X))
phase1_reg_loss = regularizer(weights1) + regularizer(weights4)
phase1_loss = phase1_reconstruction_loss + phase1_reg_loss
phase1_training_op = optimizer.minimize(phase1_loss)
with tf.name_scope("phase2"):
phase2_outputs = tf.matmul(hidden2,weights3) + bias3
phase2_reconstruction_loss = tf.reduce_mean(tf.square(phase2_outputs - hidden1))
phase2_reg_loss = regularizer(weights2) + regularizer(weights3)
phase2_loss = phase2_reconstruction_loss + phase2_reg_loss
train_vars = [weights2,bias2,weights3,bias3]
# freeze hidden1,没有计算第一隐层的梯度
phase2_training_op = optimizer.minimize(phase2_loss,var_list=train_vars)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
training_ops = [phase1_training_op , phase2_training_op]
reconstruction_losses = [phase1_reconstruction_loss, phase2_reconstruction_loss]
n_epochs = [4, 4]
batch_sizes = [ 150, 150]
#重点,到底怎么跑
with tf.Session() as sess:
init.run()
# 两个训练阶段,即两个编码器的训练
for phase in range(2):
print("Training phase #{}".format(phase + 1))
# 多少训练轮次
for epoch in range(n_epochs[phase]):
#一共多少个批量被训练
n_batches = mnist.train.num_examples // batch_sizes[phase]
for iteration in range(n_batches):
print("\r{}%".format(100 * iteration // n_batches),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_sizes[phase])
#训练
sess.run(training_ops[phase],feed_dict={X:X_batch})
#用最后的batch看重构损失
loss_train = reconstruction_losses[phase].eval(feed_dict={X:X_batch})
print("\r{}".format(epoch), "Train MSE:",loss_train)
saver.save(sess, "./my_model_one_at_a_time.ckpt")
loss_test = reconstruction_loss.eval(feed_dict={X:mnist.test.images})
print("Test MSE:", loss_test)输出:
Training phase #1
0 Train MSE: 0.0081648985
1 Train MSE: 0.0077271913
2 Train MSE: 0.0077941013
3 Train MSE: 0.007753604
Training phase #2
09% Train MSE: 0.02971007
19% Train MSE: 0.008726512
2 Train MSE: 0.0041971155
3 Train MSE: 0.0026325467
Test MSE: 0.01008975
在上的训练第2个编码器,即phase2阶段,由于第一隐层的权值是固定了的,那么计算第二个编码器的时候,每一个epoch都会计算一次第一隐层的输出是什么,所以我们可以在第一个训练结束后,用所有的训练样本得到第一隐层的全部输出,在第二个编码器训练的时候就可以直接拿来作为第二隐层的输入用,从而加速训练过程。
代码:先导入import numpy.random as rnd
training_ops = [phase1_training_op, phase2_training_op]
reconstruction_losses = [phase1_reconstruction_loss, phase2_reconstruction_loss]
n_epochs = [4, 4]
batch_sizes = [150, 150]
with tf.Session() as sess:
init.run()
for phase in range(2):
print("Training phase #{}".format(phase + 1))
if phase == 1:
#第二阶段开始的时候,先对全部的训练数据在第一隐层的输出做计算。
hidden1_cache = hidden1.eval(feed_dict={X: mnist.train.images})
for epoch in range(n_epochs[phase]):
n_batches = mnist.train.num_examples // batch_sizes[phase]
for iteration in range(n_batches):
print("\r{}%".format(100 * iteration // n_batches), end="")
sys.stdout.flush()
#第二阶段直接导入部分训练样本求出作为第二隐层的输入
if phase == 1:
indices = rnd.permutation(mnist.train.num_examples)
hidden1_batch = hidden1_cache[indices[:batch_sizes[phase]]]
feed_dict = {hidden1: hidden1_batch}
#输入为第一隐层的输出
sess.run(training_ops[phase], feed_dict=feed_dict)
else:
X_batch, y_batch = mnist.train.next_batch(batch_sizes[phase])
feed_dict = {X: X_batch}
sess.run(training_ops[phase], feed_dict=feed_dict)
loss_train = reconstruction_losses[phase].eval(feed_dict=feed_dict)
print("\r{}".format(epoch), "Train MSE:", loss_train)
saver.save(sess, "./my_model_cache_frozen.ckpt")
loss_test = reconstruction_loss.eval(feed_dict={X: mnist.test.images})
print("Test MSE:", loss_test)输出:
Training phase #1
0 Train MSE: 0.00753817
1 Train MSE: 0.00775457
2 Train MSE: 0.00734359
3 Train MSE: 0.00783768
Training phase #2
0 Train MSE: 0.200137
1 Train MSE: 0.00520852
2 Train MSE: 0.00259211
3 Train MSE: 0.00210128
Test MSE: 0.0097786
- 重用隐层的参数:
n_epochs = 4
batch_size = 150
n_labeled_instances = 20000
# Freeze layers 1 and 2 (optional)
training_op = optimizer.minimize(loss, var_list=[weights3, biases3])
with tf.Session() as sess:
init.run()
#恢复的参数只有部分
pretrain_saver.restore(sess, "./my_model_supervised.ckpt")
#pretrain_saver.restore(sess, "./my_model_cache_frozen.ckpt")
for epoch in range(n_epochs):
n_batches = n_labeled_instances // batch_size
for iteration in range(n_batches):
print("\r{}%".format(100 * iteration // n_batches), end="")
sys.stdout.flush()
indices = rnd.permutation(n_labeled_instances)[:batch_size]
X_batch, y_batch = mnist.train.images[indices], mnist.train.labels[indices]
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
print("\r{}".format(epoch), "Train accuracy:", accuracy_val, end="\t")
saver.save(sess, "./my_model_supervised_pretrained.ckpt")
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels})
print("Test accuracy:", accuracy_val)输出:
INFO:tensorflow:Restoring parameters from ./my_model_supervised.ckpt
09% Train accuracy: 0.99333334 Test accuracy: 0.9628
19% Train accuracy: 0.98 Test accuracy: 0.9594
29% Train accuracy: 1.0 Test accuracy: 0.964
3 Train accuracy: 0.9866667 Test accuracy: 0.9659
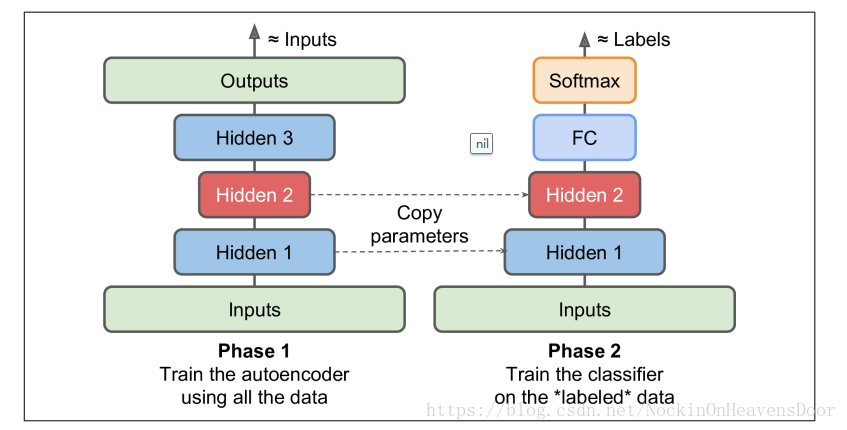
用编码器做无监督预训练
- 类似于用RBM做无监督预训练,因为现实场景中无标签数据很多且获取比较方便,可以用全部的无标签数据预训练一个堆栈编码器,然后复用训练好的低层参数做一个分类器去训练有标签的数据。如图:
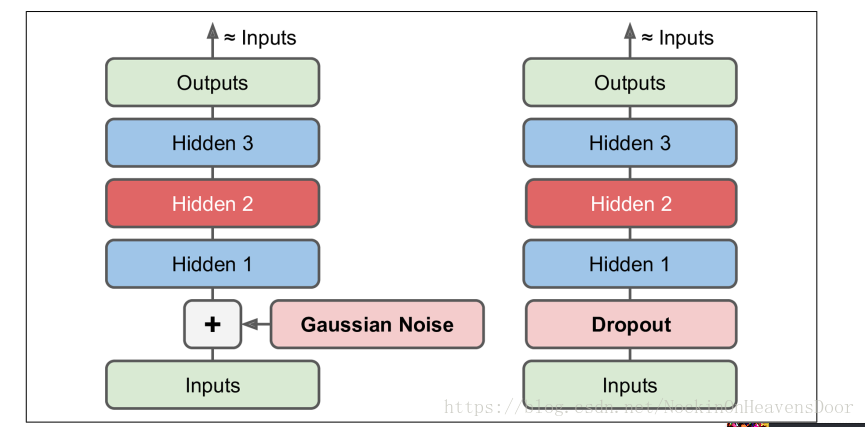
- 编码器的限制类型:
undercomplete:为了学习数据中更具有代表性的特征,限制coding层的大小比输入数据小很多;overcomplete:coding层大小和输入数据大小一致或者大小输入数据;- 其他限制:输入加入噪声,比如高斯噪声,然后再降低输出和无噪声的原始数据(
noise-free inputs)的损失,目的是去噪呗;噪声还可以是inputs数据的变异体,比如对输入数据做dropout。
如图:
去噪编码器代码:
reset_graph()
n_inouts = 28 * 28
n_hiddens1 = 300
n_hiddens2 = 150
n_hiddens3 = n_hiddens1
n_outputs = n_inputs
learning_rate = 0.01
noise_level = 1.0
X = tf.placeholder(tf.float32, [None, n_inputs])
#tf.shape会创建一个op
X_noisy = X + noise_level * tf.random_normal(tf.shape(X))
hidden1 = tf.layers.dense(X_noisy,n_hidden1,activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1,n_hidden2,activation=tf.nn.relu,
name="hidden2")
hidden3 = tf.layers.dense(hidden2,n_hidden3,activation=tf.nn.relu,
name="hidden3")
outputs = tf.layers.dense(hidden3,n_outputs,name="outputs")
#和原始未加噪声的数据比较
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 10
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batchs = mnist.train.num_examples // batch_size
for iteration in range(n_batchs):
print("\r{}".format(100 * iteration // n_batchs),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch})
reconstruction_loss_val = sess.run(reconstruction_loss,feed_dict={X:X_batch})
print("\r{}".format(epoch),"Train MSE:{}".format(reconstruction_loss_val))
saver.save(sess,"./my_model_stacked_denoising_gaussian.ckpt")
输出:
09 Train MSE:0.04139880836009979
1 Train MSE:0.04199552163481712
29 Train MSE:0.04200055077672005
3 Train MSE:0.041156355291604996
4 Train MSE:0.0395776703953743
5 Train MSE:0.04113364964723587
6 Train MSE:0.04057881608605385
7 Train MSE:0.0417446605861187
8 Train MSE:0.04276226833462715
9 Train MSE:0.042041391134262085
- 改变输入形式的编码器:
Using dropout
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 150 # codings
n_hidden3 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.01
dropout_rate = 0.3
"""
tf.placeholder_with_default: A placeholder op that passes through input when its output is not fed.
* input: A Tensor. The default value to produce when output is not fed.
"""
training = tf.placeholder_with_default(False, shape=(),name="training")
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
"""
training: Either a Python boolean, or a TensorFlow boolean scalar tensor
(e.g. a placeholder). Whether to return the output in training mode
(apply dropout) or in inference mode (return the input untouched).
"""
X_drop = tf.layers.dropout(inputs=X ,rate=dropout_rate,training=training)
hidden1 = tf.layers.dense(X_drop, n_hidden1,activation=tf.nn.relu,
name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu,
name="hidden3")
outputs = tf.layers.dense(hidden3, n_outputs, name="outputs")
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(reconstruction_loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 10
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}".format(100 * iteration // n_batches),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch})
reconstruction_loss_val = sess.run(reconstruction_loss,feed_dict={X:X_batch})
print("\r{}".format(epoch)," Train MSE:{}".format(reconstruction_loss_val))
saver.save(sess, "./my_model_stacked_denoising_dropout.ckpt")输出:
0 Train MSE:0.030757810920476913
19 Train MSE:0.029541434720158577
2 Train MSE:0.027485424652695656
3 Train MSE:0.027985714375972748
4 Train MSE:0.026596367359161377
5 Train MSE:0.027273502200841904
69 Train MSE:0.026832997798919678
7 Train MSE:0.02562137506902218
8 Train MSE:0.026205850765109062
9 Train MSE:0.025004003196954727
稀疏编码器
也是一种限制形式,利用稀疏性(sparsity)提取有用的特征,其方法是在损失函数中加入额外的损失(稀疏损失),从而在减少coding层中被激活的神经元,为什么要减少呢,可以想象越少的神经元要保留更多的信息,那么每一个神经元都必须提取更加有用的信息(也就是特征),举例,一个人一个月只能说两三句话的时候,这几句话肯定代表着这个人最想表达的信息。
注:训练批次不能太小,因为会计算coding层在一个训练批次内,平均每个神经元被激活多少次,批次太小均值会不准确。
- 衡量某一个神经元激活概率过大,在实践中利用KL散度比MSE更加合适,原因如图:
p = 0.1
q = np.linspace(0.001, 0.999, 500)
kl_div = p * np.log( p / q) + (1 - p) * np.log( (1 - p) / (1 - q))
mse = (p - q) ** 2
plt.rcParams['figure.dpi']=300
#在这个位置画一个线
plt.plot([p,p],[0, 0.3],'k:')
#在这个位置插入文字
plt.text(0.05 , 0.32, "Target\n sparsity", fontsize=14)
plt.plot(q, kl_div, 'b-',label="KL divergence")
plt.plot(q, mse, 'r--', label='MSE')
plt.legend(loc="upper left")
plt.xlabel("Actual sparsity")
plt.ylabel("Cost",rotation=0)
plt.axis([0,1,0,0.95])
save_fig("sparsity_loss_plot")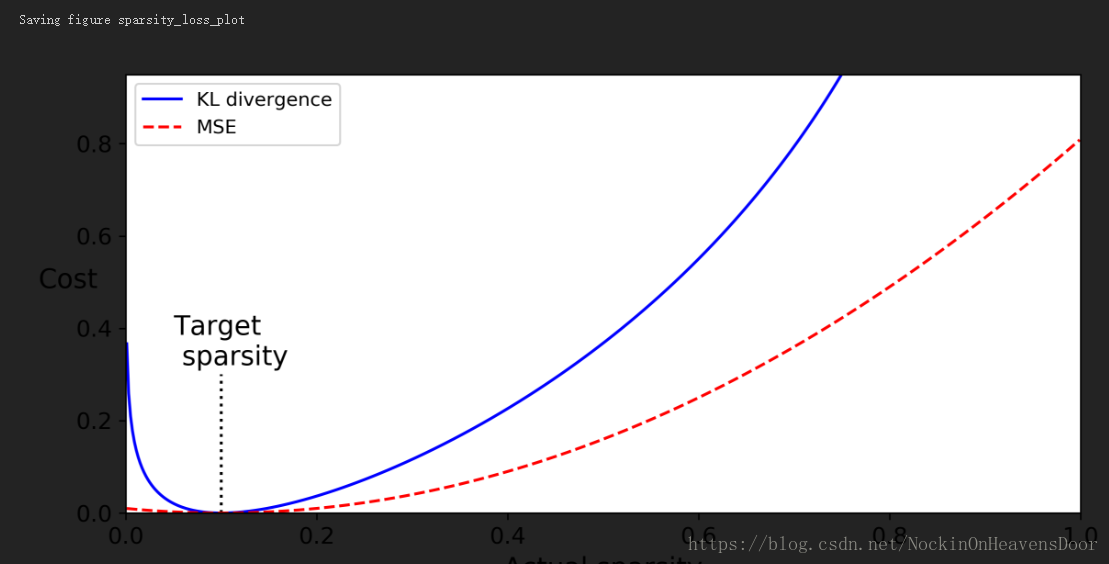
- 总的损失是稀疏性损失加上一个重构损失(MSE),为了控制两个损失的平衡性,对稀疏性损失乘上一个超参数作为权重,该权重过大,越在乎稀疏性损失而忽略重构损失,过小的话相反。
代码:
- 注:coding层被激活之后的输出必须大于0小于1,不然KL返回
NaN,所以,用sigmoid函数作为激活函数。 - 注:为了加速训练,把
inputs正则化到[0,1]范围,然后用cross entropy取代MSE作为损失函数。
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 1000 # sparse codings
n_outputs = n_inputs
def Kl_divergence(p, q):
return p * tf.log(p / q) + (1 - p) * tf.log( (1-p) / (1-q))
learning_rate = 0.01
sparsity_target = 0.1
sparsity_weight = 0.2
X = tf.placeholder(tf.float32,[None, n_inputs])
hidden1 = tf.layers.dense(X, n_hidden1,activation=tf.nn.sigmoid,
name="hidden1")
outputs = tf.layers.dense(hidden1, n_outputs,name="outputs")
##计算隐层中1000个神经元的权重平均值,等于被激活的概率
hidden1_mean = tf.reduce_mean(hidden1, axis=0) #记住0是按照列计算
sparsity_loss = tf.reduce_sum(Kl_divergence(sparsity_target, hidden1_mean))
reconstruction_loss = tf.reduce_mean(tf.square(outputs-X)) #MSE
loss = reconstruction_loss + sparsity_weight * sparsity_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 100
batch_size = 1000
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}".format( 100 * iteration // n_batches),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch})
reconstruction_loss_val, sparsity_loss_val, loss_val = sess.run([reconstruction_loss,sparsity_loss,loss],
feed_dict={X:X_batch})
print("\r{}".format(epoch), "Train MSE:", reconstruction_loss_val, "\tSparsity loss:", sparsity_loss_val, "\tTotal loss:", loss_val)
saver.save(sess, "./my_model_sparse.ckpt")可视化试试:
show_reconstructed_digits(X, outputs, "./my_model_sparse.ckpt")用交叉熵的代码:
logits = tf.layers.dense(hidden1, n_outputs)
outputs = tf.nn.sigmoid(logits)
#记住logits是未用激活函数激活的数值,参考我转的写logits的那个文章
xentropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits)
reconstruction_loss = tf.reduce_mean(xentropy)变分编码器
变分编码器
- 类似于RBMs,但是更易训练和生成样本。如图,encoder产生
codings: 和标准差 ,然后用来做个一个高斯分布作为采样来源,decoder从这个高斯分布中采集样本进行解码,done!右边是一个实例的情况。因为多个高斯分布的叠加被证明可以接近任何分布,但是变分编码器不局限于只从高斯分布采样。 - 数学证明参考我写的这个
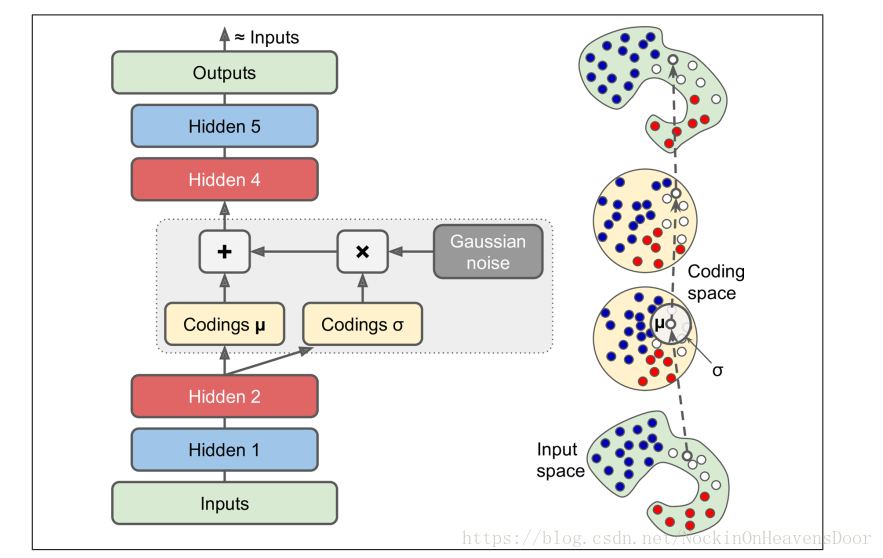
- 代码:
reset_graph()
from functools import partial
n_inputs = 28 * 28
n_hidden1 = 500
n_hidden2 = 300
n_hidden3 = 20 #codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
outputs = n_inputs
learning_rate = 0.001
initializer = tf.contrib.layers.variance_scaling_initializer()
my_dense_layer = partial(
tf.layers.dense,
activation=tf.nn.elu,
#
kernel_initializer=initializer)
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = my_dense_layer(X,n_hidden1)
hidden2 = my_dense_layer(hidden1,n_hidden2)
hidden3_mean = my_dense_layer(hidden2,n_hidden3,activation= None)
hidden3_sigma = my_dense_layer(hidden2,n_hidden3,activation= None)
noise = tf.random_normal(tf.shape(hidden3_sigma), dtype=tf.float32)
hidden3 = hidden3_mean + hidden3_sigma * noise #sigma和noise对应元素相乘
hidden4 = my_dense_layer(hidden3, n_hidden4)
hidden5 = my_dense_layer(hidden4, n_hidden5)
logits = my_dense_layer(hidden5,n_outputs,activation=None)
outputs = tf.sigmoid(logits)
xentropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=X,logits=logits)
reconstruction_loss = tf.reduce_sum(xentropy)
eps = 1e-10# smoothing term to avoid computing log(0) which is NaN
latent_loss = 0.5 * tf.reduce_mean(
tf.square(hidden3_sigma) + tf.square(hidden3_mean)
-1 - tf.log(eps + tf.square(hidden3_sigma)))
loss = reconstruction_loss + latent_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 50
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_bathches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}".format(100 * iteration // batch_size),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch})
loss_val, reconstruction_loss_val, latent_loss_val = sess.run([loss, reconstruction_loss,latent_loss],
feed_dict={X:X_batch})
print("\r{}".format(epoch), "Train total loss:", loss_val, "\tReconstruction loss:", reconstruction_loss_val, "\tLatent loss:", latent_loss_val)
saver.save(sess, "./my_model_variational.ckpt")
看看咱们的训练如何:
show_reconstructed_digits(X, outputs, "./my_model_variational.ckpt")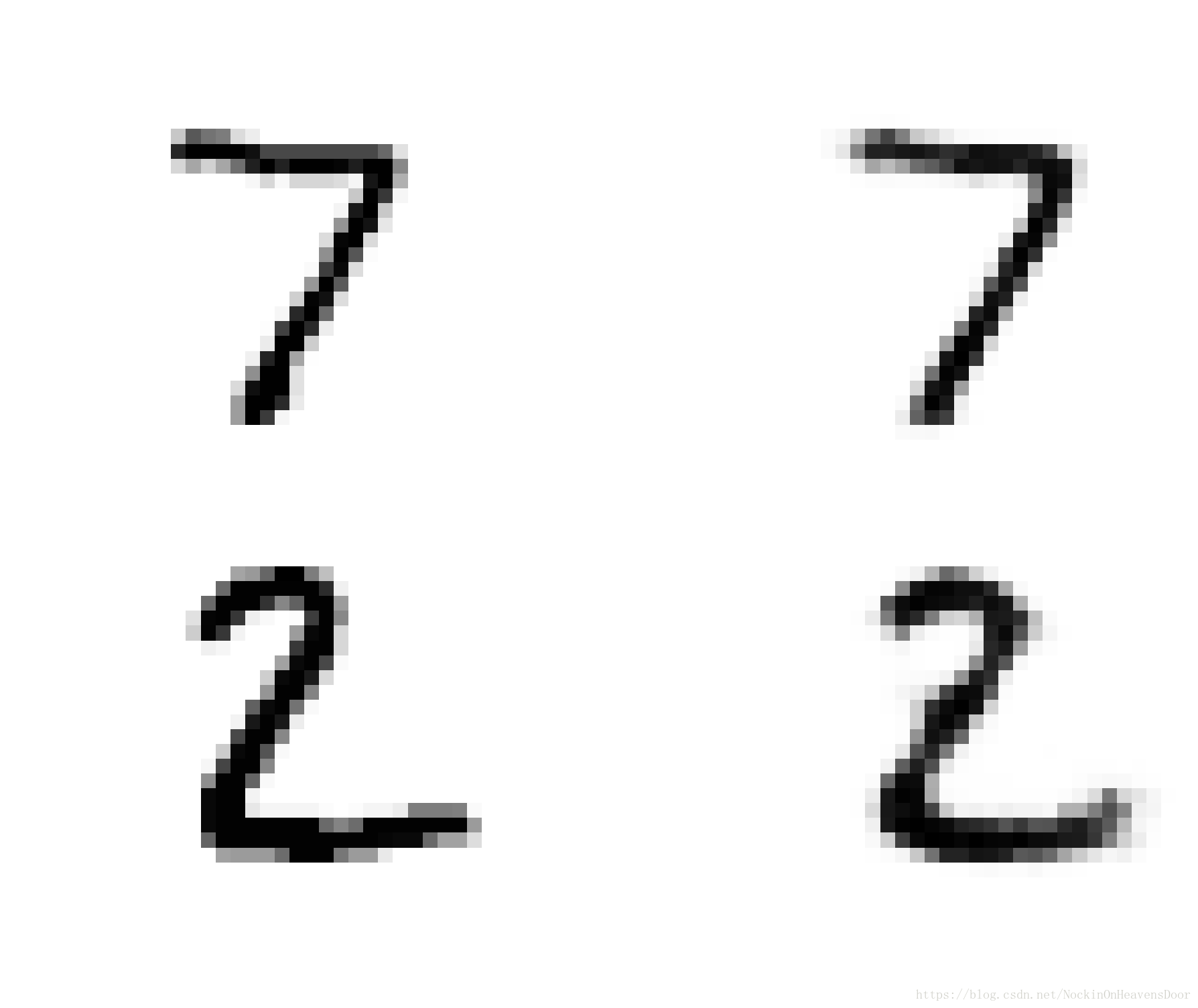
非常接近啊。
- 注:这里有一个技巧可以更好的训练和采样,即令 ,这样encoder输入的便是 ..
- 代码:
reset_graph()
from functools import partial
n_inputs = 28 * 28
n_hidden1 = 500
n_hidden2 = 500
n_hidden3 = 20 # codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.001
with tf.contrib.framework.arg_scope(
[fully_connected],
activation_fn=tf.nn.relu,
weights_initializer=tf.contrib.layers.variance_scaling_initializer()):
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = fully_connected(X, n_hidden1)
hidden2 = fully_connected(hidden1,n_hidden2)
hidden3_mean = fully_connected(hidden2,n_hidden3,activation_fn=None)
hidden3_gamma = fully_connected(hidden2,n_hidden3,activation_fn=None)
hidden3_sigma = tf.exp(0.5 * hidden3_gamma)
noise = tf.random_normal(tf.shape(hidden3_sigma),dtype=tf.float32)
hidden3 = hidden3_mean + hidden3_sigma * noise
hidden4 = fully_connected(hidden3,n_hidden4)
hidden5 = fully_connected(hidden4,n_hidden5)
logits = fully_connected(hidden5,n_outputs,activation_fn=None)
outputs = tf.sigmoid(logits)
reconstruction_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(labels=X,logits=logits))
latent_loss = 0.5 * tf.reduce_sum(tf.exp(hidden3_gamma) + tf.square(hidden3_mean)
- 1 - hidden3_gamma)
cost = reconstruction_loss + latent_loss
optimizer = tf.train.AdamOptimizer(learning_rate)
training_op = optimizer.minimize(cost)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 50
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}%".format(100 * iteration // n_batches), end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch})
loss_val, reconstruction_loss_val, latent_loss_val = sess.run([cost, reconstruction_loss, latent_loss], feed_dict={X: X_batch})
print("\r{}".format(epoch), "Train total cost:", loss_val, "\tReconstruction loss:", reconstruction_loss_val, "\tLatent loss:", latent_loss_val)
saver.save(sess, "./my_model_variational_variant.ckpt")
生成数据(图片)
- 步骤:
- training mode
- sample random codings in Guassian Distribution.
- decode samples.
代码:
import numpy as np
import tensorflow as tf
from functools import partial
reset_graph()
n_digits = 60
n_inputs = 28 * 28
n_hidden1 = 500
n_hidden2 = 500
n_hidden3 = 20 # codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
n_outputs = n_inputs
learning_rate = 0.001
initializer = tf.contrib.layers.variance_scaling_initializer()
my_dense_layer = partial(
tf.layers.dense,
activation=tf.nn.elu,
kernel_initializer=initializer)
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = my_dense_layer(X, n_hidden1)
hidden2 = my_dense_layer(hidden1, n_hidden2)
hidden3_mean = my_dense_layer(hidden2, n_hidden3, activation=None)
hidden3_gamma = my_dense_layer(hidden2, n_hidden3, activation=None)
noise = tf.random_normal(tf.shape(hidden3_gamma), dtype=tf.float32)
hidden3 = hidden3_mean + tf.exp(0.5 * hidden3_gamma) * noise
hidden4 = my_dense_layer(hidden3, n_hidden4)
hidden5 = my_dense_layer(hidden4, n_hidden5)
logits = my_dense_layer(hidden5, n_outputs, activation=None)
outputs = tf.sigmoid(logits)
xentropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits)
reconstruction_loss = tf.reduce_sum(xentropy)
latent_loss = 0.5 * tf.reduce_sum(
tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)
loss = reconstruction_loss + latent_loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
n_batches = mnist.train.num_examples // batch_size
for iteration in range(n_batches):
print("\r{}%".format( 100 * iteration // n_bathches),end="")
sys.stdout.flush()
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch})
loss_val,reconstruction_loss_val, latent_loss_val = sess.run([loss, reconstruction_loss, latent_loss], feed_dict={X: X_batch})
print("\r{}".format(epoch), "Train total loss:", loss_val, "\tReconstruction loss:", reconstruction_loss_val, "\tLatent loss:", latent_loss_val)
saver.save(sess, "./my_model_variational.ckpt") # not shown
##高斯分布中采样:size : 60 * 20
codings_rnd = np.random.normal(size=[n_digits,n_hidden3])
output_val = outputs.eval(feed_dict={hidden3: codings_rnd})
plt.figure(figsize=(8, 50))
for iteration in range(n_digits):
plt.subplot(n_digits, 10, iteration + 1)
plot_image(output_val[iteration])
编码和解码(Encode & Decode)
- encode:
n_digits = 3
X_test, y_test = mnist.test.next_batch(batch_size)
codings = hidden3
with tf.Session() as sess:
saver.restore(sess,"./my_model_variational.ckpt")
codings_eval = codings.eval(feed_dict={X:X_test})- decode:
with tf.Session() as sess:
saver.restore(sess,"./my_model_variational.ckpt")
outputs_val = outputs.eval(feed_dict={codings:codings_eval})- Let’s plot the reconstructions:
fig = plt.figure(figsize=(8, 2.5 * n_digits))
for iteration in range(n_digits):
plt.subplot(n_digits, 2, 1 + 2 * iteration)
plot_image(X_test[iteration])
plt.subplot(n_digits, 2, 2 + 2 * iteration)
plot_image(outputs_val[iteration])扭曲高斯分布的数据来画数字,即高斯分布数据作为自变量的函数画数据
n_iterations = 3
n_digits = 6
codings_rnd = np.random.normal(size=[n_digits, n_hidden3])
with tf.Session() as sess:
saver.restore(sess, "./my_model_variational.ckpt")
#来自高斯分布
target_codings = np.roll(codings_rnd, -1, axis=0)
for iteration in range(n_iterations + 1):
#变成了高斯分布的一个函数,数据被扭曲
codings_interpolate = codings_rnd + (target_codings - codings_rnd) * iteration / n_iterations
outputs_val = outputs.eval(feed_dict={codings: codings_interpolate})
plt.figure(figsize=(11, 1.5*n_iterations))
for digit_index in range(n_digits):
plt.subplot(1, n_digits, digit_index + 1)
plot_image(outputs_val[digit_index])
plt.show()