理解深度学习的特征学习——tensorflow实战(黄文坚)



好了,部分截图到此,了解更多自己看书去... .. .(然后你会发现后面的内容都是在抄书[捂脸])
下面开始抄代码... .. .
=================================================================
步骤一:导入各种模块
import numpy as n import sklearn.preprocessing as prep #1 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #2
① sklearn 中的 preprocessing 模块是一个常用于数据处理的模块,之后我们会死用它的数据标准化功能
②从Tensorflow的MNIST数据模块中导入数据
步骤二:定义自编码器的参数初始化方法
Xavier初始化方法是2010年提出来的一种很有效的神经网络初始化方法,需要深入理解请点击链接Understanding the difficulty of training deep feedforward neural networks
Xavier 就是让权重满足均值为0,同时方差为2/(nin-nout)分布可以用均匀分布和高斯分布,我们通过tf.random_uniform创建一个以下范围内的均匀分布:
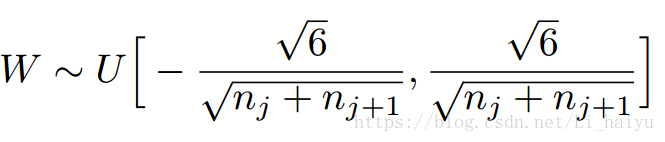
def xavier_init( fan_in, fan_out, constant = 1 ): low = -constant * np.sqrt( 6.0 / ( fan_in + fan_out ) ) #1 high = constant * np.sqrt( 6.0 / ( fan_in + fan_out ) ) return tf.random_uniform((fan_in, fan_out), minval=low, maxval=high, dtype=tf.float32 ) #2
① np.sqrt 是numpy科学计算库的开方运算,其中math模块中的math.pow(6.0/(fan_in+fan_out),0.5)也实现类似功能
② tf.random_uniform的第一个参数是shape,紧接着的两个参数表示范围,最后一个是数据类型
步骤三:定义去噪自编码的class
class AdditiveGaussianNoiseAutoencoder(object): def __init__(self, n_input, n_hidden, transfer_function=tf.nn.softplus, optimizer = tf.train.AdamOptimizer(), scale=0.1 ): self.n_input = n_input # 输入变量数 self.n_hidden = n_hidden # 隐藏层节点数 self.transfer = transfer_function # 隐藏层激活函数,默认是softplus self.scale = tf.placeholder( tf.float32 ) # class内的scale self.training_scale = scale # 训练数据的高斯噪声系数 network_weights = self._initialize_weights() # 初始化._initialize_weights()方法 self.weights = network_weights self.x = tf.placeholder( tf.float32, [None, self.n_input] ) # tf.placeholder 第一个参数是数据类型,第二个参数是shape # 第一层权重 中间隐藏层经过激活函数处理的结果 # tf.add()实现加法,tf.matmul()矩阵乘法,tf.random_normal()的第一个参数是shape,mean = 0,stddev = 1,从正太分布中输出随机值, self.hidden = self.transfer( tf.add( tf.matmul(self.x + scale * tf.random_normal(( n_input, ) ), self.weights['w1'] ), self.weights['b1'] )) # 第二层权重 self.reconstruction 就是最后输出的结果 self.reconstruction = tf.add( tf.matmul( self.hidden, self.weights['w2'] ), self.weights['b2'] ) # 计算损失函数 tf.reduce_sum()求和 tf.pow()求幂 tf.subtract()相减 self.cost = 0.5 * tf.reduce_sum( tf.pow( tf.subtract( self.reconstruction, self.x ), 2 ) ) # optimizer = tf.train.AdamOptimizer() self.optimizer = optimizer.minimize( self.cost ) # 定义初始化所有变量方法 init = tf.global_variables_initializer() self.sess = tf.Session() # 执行初始化变量方法 self.sess.run( init ) print ("begin to run session...")
步骤四:定义calss的成员函数
# 定义参数初始化函数 def _initialize_weights(self): all_weights = dict() #创建字典存储参数 # 初始化w1采用前面定义的xavier_init函数 all_weights['w1'] = tf.Variable( xavier_init(self.n_input, self.n_hidden ) ) # tf.zeros(shape,dtype),shape可以用元组传递也可以用列表传递 all_weights['b1'] = tf.Variable( tf.zeros( [self.n_hidden], dtype = tf.float32 ) ) all_weights['w2'] = tf.Variable( tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32) ) # 因为自编码器的输入层和输出层节点是一样的,所以 b2 初始化tf.zeros([self.n_input],dtype = tf.float.32) all_weights['b2'] = tf.Variable( tf.zeros( [self.n_input], dtype = tf.float32 ) ) return all_weights # 定义计算损失函数及执行一步训练的函数 # 实现对一个batch数据进行训练并返回cost def partial_fit(self, X): # Session执行两个计算图的节点,分别是cost和训练过程optimizer # 输入的feed_dict包括输入数据x,以及噪声系数scale cost, opt = self.sess.run( (self.cost, self.optimizer), feed_dict = { self.x : X, self.scale : self.training_scale } ) return cost # 定义函数只求cost # Session只执行一个计算图节点self.cost 传入参数和 partial_fit一致 # 这个函数再自编码器训练完毕后,在测试集上对模型性能进行评测时用到,它不像 partial_fit 触发训练操作 def calc_total_cost( self, X ): return self.sess.run( self.cost, feed_dict = { self.x : X, self.scale : self.training_scale } ) # 定义transform 函数返回隐含层激活函数处理后的输出结果 # 它的目的是提供一个接口来获取抽象后的特征,自编码器的隐含层的主要功能就是学习出数据中的高阶特征 def transform( self, X ): return self.sess.run( self.hidden, feed_dict = { self.x : X, self.scale : self.training_scale } ) # 定义generate函数,将隐含层输出结果作为输入,通过之后的重建层将提取到的高阶特征恢复为原始数据 # 这个接口和前面的transform正好将自编码器分为两部分,这里的generate接口是后半部分,将高阶特征复原成原始数据 def generate( self, hidden = None ): if hidden == None: hidden = np.random.normal( size = self.weights['b1'] ) return self.sess.run( self.reconstruction, feed_dict = { self.hidden : hidden } ) # 定义reconstruction函数,它整体运行一遍复原过程,包括transform和generate两块,输入原始数据,输出复原后的数据 def reconstruction( self, X ): # 注意这里的输入数据不是从self.hidden输入了,而是直接由原始数据输入self.x return self.sess.run( self.reconstruction, feed_dict = { self.x : X, self.scale : self.training_scale } ) # 获取隐含层的权重w1 def getWeights( self ): return self.sess.run( self.weights['w1'] ) # 获取隐含层偏置b1 def getBiases( self ): return self.sess.run( self.weights['b1'] )
步骤五:训练前的准备工作
# 使用tensorflow提供的读取示例数据的函数载入MNIST数据集 mnist = input_data.read_data_sets( '../MNIST_data', one_hot = True ) # 定义一个对训练,测试数据进行标准化处理的函数 # 标准化就是让变成数据均值为0,标准差为1的分布 方法:(X-X_mean)/stddev # 直接使用sklearn.preprocessing的StandardScaler类可以实现,现在训练集进行fit,再将这个Scaler用到训练集和测试集上 # 注意:必须保证训练集和测试集使用相同的Scaler,这样才能保证后面模型处理数据时的一致性,这也是为什么先在训练数据fit出一个共同的caler的原因 def standard_scale( X_train, X_test ): # 在训练数据集上fit出一个共同的Scaler preprocessor = prep.StandardScaler().fit( X_train ) X_train = preprocessor.transform( X_train ) X_test = preprocessor.transform( X_test ) return X_train, X_test # 定义一个获取随机block数据函数:取一个从0到len(data)-batch_size之间的随机整数 # 再以这个随机数作为block的起始位置,然后顺序取到一个batch_size数据 # 注意:这属于放放回抽样,可以提高数据的利用率 def get_random_block_from_data( data, batch_size ): start_index = np.random.randint( 0, len(data) - batch_size ) return data[ start_index : (start_index+batch_size) ] # 使用之前定义的standard_scale函数对训练集和测试集进行标准化变换 X_train, X_test =standard_scale( mnist.train.images, mnist.test.images ) # 下面定义几个常用的参数,总训练样本数,最大训练的轮数(epoch)设为20,batch_size设为128,并每隔一轮epoch就显示一次cost # batch_size 一般设置为8的倍数,太小不容易收敛,太大训练吃力,精度不够 n_samples = int( mnist.train.num_examples ) training_epochs = 20 batch_size = 128 display_step = 1 # 创建前面定义去噪声的自编码实例 # 输入节点784(28*28),200个隐藏层节点,激活函数是softplus,优化器学习率0.001,噪声系数0.1 autoencoder = AdditiveGaussianNoiseAutoencoder( n_input = 784, n_hidden = 200, transfer_function = tf.nn.softplus, optimizer = tf.train.AdamOptimizer( learning_rate = 0.001 ), scale = 0.01 )
步骤六:开始训练
# 开始训练 for epoch in range( training_epochs ): # 初始化平均损失值 avg_cost = 0 # 计算迭代次数(iteration) total_batch = int( n_samples / batch_size ) # 每一次i就是将bitch_size扔网络训练一次 for i in range( total_batch ): batch_xs = get_random_block_from_data( X_train, batch_size ) # 使用类的方法partial_fit获取损失函数值 cost = autoencoder.partial_fit( batch_xs ) # 计算平均损失函数值avg_cost avg_cost = cost / n_samples * batch_size # 每一轮就显示一次cost值,display_step = 1,所以下面表示显示每次epoch的avg_cost值 if epoch % display_step == 0: # %04d 表示输出以为少于4位的数值时,前面补0 # %.9f保留小数点后面9位 # 输出示例:epoch : 0001, cost = 39.167500000 print( "epoch : %04d, cost = %.9f" % ( epoch+1, avg_cost ) )
第七步:利用测试集进行性能测试
# 对测试集X_test进行测试 如果使用示例中的参数,损失值约为60万[笑哭] print( "Total cost : ", str( autoencoder.calc_total_cost(X_test)))
输出结果:

最后:终于抄完了,为了首尾呼应,截图为终

参考: tensorflow实战(黄文坚)
附代码:
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
#
def xavier_init( fan_in, fan_out, constant = 1 ):
low = -constant * np.sqrt( 6.0 / ( fan_in + fan_out ) )
high = constant * np.sqrt( 6.0 / ( fan_in + fan_out ) )
return tf.random_uniform((fan_in, fan_out), minval=low, maxval=high, dtype=tf.float32 )
class AdditiveGaussianNoiseAutoencoder(object):
def __init__(self, n_input, n_hidden, transfer_function=tf.nn.softplus, optimizer = tf.train.AdamOptimizer(), scale=0.1 ):
self.n_input = n_input # 输入变量数
self.n_hidden = n_hidden # 隐藏层节点数
self.transfer = transfer_function # 隐藏层激活函数,默认是softplus
self.scale = tf.placeholder( tf.float32 ) # class内的scale
self.training_scale = scale # 训练数据的高斯噪声系数
network_weights = self._initialize_weights() # 初始化._initialize_weights()方法
self.weights = network_weights
self.x = tf.placeholder( tf.float32, [None, self.n_input] ) # tf.placeholder 第一个参数是数据类型,第二个参数是shape
# 第一层权重 中间隐藏层经过激活函数处理的结果
# tf.add()实现加法,tf.matmul()矩阵乘法,tf.random_normal()的第一个参数是shape,mean = 0,stddev = 1,从正太分布中输出随机值,
self.hidden = self.transfer( tf.add( tf.matmul(self.x + scale * tf.random_normal(( n_input, ) ), self.weights['w1'] ), self.weights['b1'] ))
# 第二层权重 self.reconstruction 就是最后输出的结果
self.reconstruction = tf.add( tf.matmul( self.hidden, self.weights['w2'] ), self.weights['b2'] )
# 计算损失函数 tf.reduce_sum()求和 tf.pow()求幂 tf.subtract()详见
self.cost = 0.5 * tf.reduce_sum( tf.pow( tf.subtract( self.reconstruction, self.x ), 2 ) )
# optimizer = tf.train.AdamOptimizer()
self.optimizer = optimizer.minimize( self.cost )
# 定义初始化所有变量方法
init = tf.global_variables_initializer()
self.sess = tf.Session()
# 执行初始化变量方法
self.sess.run( init )
print ("begin to run session...")
# 定义参数初始化函数
def _initialize_weights(self):
all_weights = dict() #创建字典存储参数
# 初始化w1采用前面定义的xavier_init函数
all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden ) )
# tf.zeros(shape,dtype),shape可以用元组传递也可以用列表传递
all_weights['b1'] = tf.Variable( tf.zeros( [self.n_hidden], dtype = tf.float32 ) )
all_weights['w2'] = tf.Variable( tf.zeros([self.n_hidden, self.n_input], dtype = tf.float32) )
# 因为自编码器的输入层和输出层节点是一样的,所以 b2 初始化tf.zeros([self.n_input],dtype = tf.float.32)
# 表示1行有784个数
all_weights['b2'] = tf.Variable( tf.zeros( [self.n_input], dtype = tf.float32 ) )
return all_weights
# 定义计算损失函数及执行一步训练的函数
# 实现对一个batch数据进行训练并返回cost
def partial_fit(self, X):
# Session执行两个计算图的节点,分别是cost和训练过程optimizer
# 输入的feed_dict包括输入数据x,以及噪声系数scale
cost, opt = self.sess.run( (self.cost, self.optimizer),
feed_dict = { self.x : X, self.scale : self.training_scale } )
return cost
# 定义函数只求cost
# Session只执行一个计算图节点self.cost 传入参数和 partial_fit一致
# 这个函数再自编码器训练完毕后,在测试集上对模型性能进行评测时用到,它不像 partial_fit 触发训练操作
def calc_total_cost( self, X ):
return self.sess.run( self.cost, feed_dict = { self.x : X, self.scale : self.training_scale } )
# 定义transform 函数返回隐含层激活函数处理后的输出结果
# 它的目的是提供一个接口来获取抽象后的特征,自编码器的隐含层的主要功能就是学习出数据中的高阶特征
def transform( self, X ):
return self.sess.run( self.hidden, feed_dict = { self.x : X, self.scale : self.training_scale } )
# 定义generate函数,将隐含层输出结果作为输入,通过之后的重建层将提取到的高阶特征恢复为原始数据
# 这个接口和前面的transform正好将自编码器分为两部分,这里的generate接口是后半部分,将高阶特征复原成原始数据
def generate( self, hidden = None ):
if hidden == None:
hidden = np.random.normal( size = self.weights['b1'] )
return self.sess.run( self.reconstruction, feed_dict = { self.hidden : hidden } )
# 定义reconstruction函数,它整体运行一遍复原过程,包括transform和generate两块,输入原始数据,输出复原后的数据
def reconstruction( self, X ):
# 注意这里的输入数据不是从self.hidden输入了,而是直接由原始数据输入self.x
return self.sess.run( self.reconstruction, feed_dict = { self.x : X, self.scale : self.training_scale } )
# 获取隐含层的权重w1
def getWeights( self ):
return self.sess.run( self.weights['w1'] )
# 获取隐含层偏置b1
def getBiases( self ):
return self.sess.run( self.weights['b1'] )
# 使用tensorflow提供的读取示例数据的函数载入MNIST数据集
mnist = input_data.read_data_sets( '../MNIST_data', one_hot = True )
# 定义一个对训练,测试数据进行标准化处理的函数
# 标准化就是让变成数据均值为0,标准差为1的分布 方法:(X-X_mean)/stddev
# 直接使用sklearn.preprocessing的StandardScaler类可以实现,现在训练集进行fit,再将这个Scaler用到训练集和测试集上
# 注意:必须保证训练集和测试集使用相同的Scaler,这样才能保证后面模型处理数据时的一致性,这也是为什么先在训练数据fit出一个共同的caler的原因
def standard_scale( X_train, X_test ):
# 在训练数据集上fit出一个共同的Scaler
preprocessor = prep.StandardScaler().fit( X_train )
X_train = preprocessor.transform( X_train )
X_test = preprocessor.transform( X_test )
return X_train, X_test
# 定义一个获取随机block数据函数:取一个从0到len(data)-batch_size之间的随机整数
# 再以这个随机数作为block的起始位置,然后顺序取到一个batch_size数据
# 注意:这属于放放回抽样,可以提高数据的利用率
def get_random_block_from_data( data, batch_size ):
start_index = np.random.randint( 0, len(data) - batch_size )
return data[ start_index : (start_index+batch_size) ]
# 使用之前定义的standard_scale函数对训练集和测试集进行标准化变换
X_train, X_test =standard_scale( mnist.train.images, mnist.test.images )
# 下面定义几个常用的参数,总训练样本数,最大训练的轮数(epoch)设为20,batch_size设为128,并每隔一轮epoch就显示一次cost
# batch_size 一般设置为8的倍数,太小不容易收敛,太大训练吃力,精度不够
n_samples = int( mnist.train.num_examples )
training_epochs = 20
batch_size = 128
display_step = 1
# 创建前面定义去噪声的自编码实例
# 输入节点784(28*28),200个隐藏层节点,激活函数是softplus,优化器学习率0.001,噪声系数0.1
autoencoder = AdditiveGaussianNoiseAutoencoder( n_input = 784,
n_hidden = 200,
transfer_function = tf.nn.softplus,
optimizer = tf.train.AdamOptimizer( learning_rate = 0.001 ),
scale = 0.01 )
# 开始训练
for epoch in range( training_epochs ):
# 初始化平均损失值
avg_cost = 0
# 计算迭代次数(iteration)
total_batch = int( n_samples / batch_size )
# 每一次i就是将bitch_size扔网络训练一次
for i in range( total_batch ):
batch_xs = get_random_block_from_data( X_train, batch_size )
# 使用类的方法partial_fit获取损失函数值
cost = autoencoder.partial_fit( batch_xs )
# 计算平均损失函数值avg_cost
avg_cost = cost / n_samples * batch_size
# 每一轮就显示一次cost值,display_step = 1,所以下面表示显示每次epoch的avg_cost值
if epoch % display_step == 0:
# %04d 表示输出以为少于4位的数值时,前面补0
# %.9f保留小数点后面9位
# 输出示例:epoch : 0001, cost = 39.167500000
print( "epoch : %04d, cost = %.9f at %s" % ( epoch+1, avg_cost,time.ctime() ) )
# 对测试集X_test进行测试 如果使用示例中的参数,损失值约为60万[笑哭]
print( "Total cost : ", str( autoencoder.calc_total_cost(X_test)))