原文地址:https://blog.csdn.net/zhanglh046/article/details/78486338
一 Spark中Checkpoint是什么
假设一个应用程序特别复杂场景,从初始RDD开始到最后整个应用程序完成,有非常多的步骤,比如超过20个transformation操作,而且整个运行时间也比较长,比如1-5个小时。此时某一个步骤数据丢失了,尽管之前在之前可能已经持久化到了内存或者磁盘,但是依然丢失了,这是很有可能的。也就是说没有容错机制,那么有可能需要重新计算一次。而如果这个步骤很耗时和资源,那么有点悲剧。
对于一个复杂的RDD,我们如果担心某些关键的,会在后面反复使用的RDD,可能会因为节点的故障,导致持久化数据的丢失,就可以针对该RDD启动checkpoint机制,实现容错和高可用。它的流程大致如下图所示:
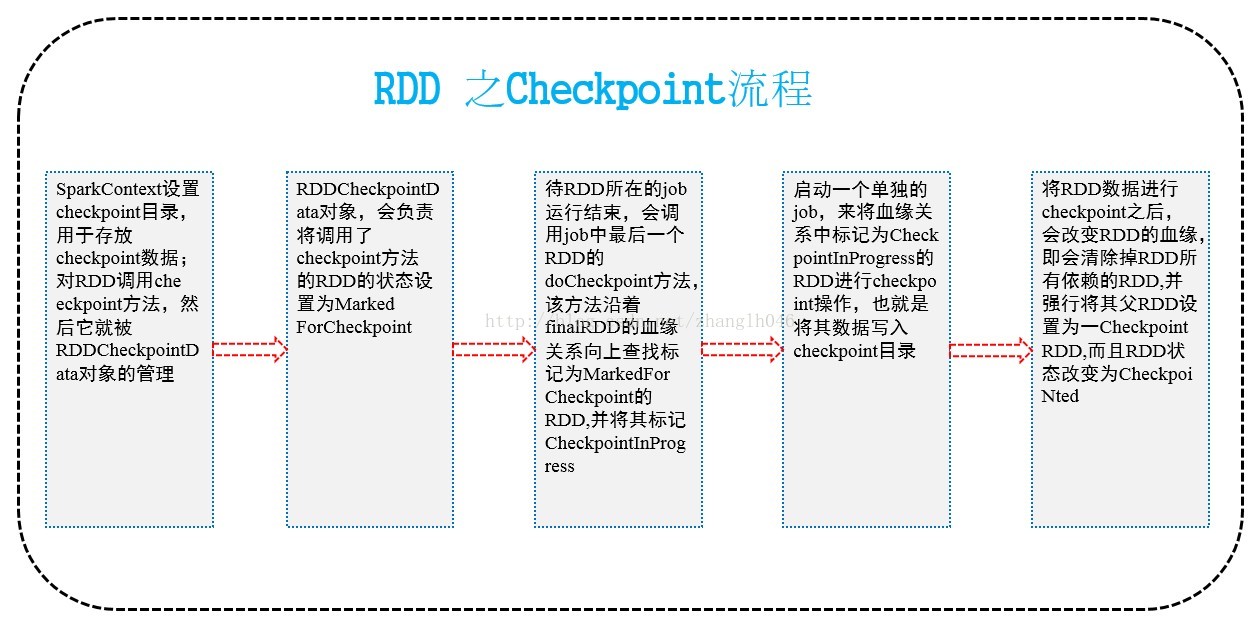
二 如何进行Checkpoint呢?
在SparkContext中需要调用setCheckpointDir方法,设置一个容错的文件系统的目录,比如HDFS。然后对RDD调用checkpoint方法,之后在RDD所处的job运行结束之后,会启动一个单独的job来将checkpoint过的RDD的数据写入之前设置的文件系统中。进行持久化操作。
那么此时,即使在后面使用RDD的时候,他的持久化数据不小心丢失了,但是还是可以从它的checkpoint文件中读取出该数据,而无需重新计算。
注意:在进行checkpoint之前,最好先对RDD执行持久化操作,比如persist(StorageLevel.DISK_ONLY)如果持久化了,就不用再重新计算;否则如果没有持久化RDD,还设置了checkpoint,那么本来job都结束了,但是由于中间的RDD没有持久化,那么checkpointjob想要将RDD数据写入外部文件系统,还得从RDD之前的所有的RDD全部重新计算一次,再进行checkpoint。然后从持久化的RDD磁盘文件读取数据。
三 Checkpoint与持久化的区别
3.1 lineage是否发生改变
持久化只是将数据保存在BlockManager中;但是RDD的lineage(血缘关系)是不会变化的。Checkpoint完毕之后,RDD已经没有之前的lineage(血缘关系),而只有一个强行为其设置的CheckpointRDD, 也就是说checkpoint之后,lineage发生了改变。
3.2 丢失数据的可能性
持久化的数据丢失的可能性更大。Checkpoint的数据通常是保存在容错高可用的文件系统中,比如HDFS,所以checkpoint丢失数据的更能性更小。
四 源码分析
4.1 RDD的checkpoint方法
- 如果SparkContext没有设置checkpointDir,则抛出异常。
- 如果设置了,则创建RDDCheckpointData,这个类主要负责管理RDD的checkpoint的进程和状态等。
- 创建RDDCheckpointData的时候,会初始化checkpoint状态为Initialized。
def checkpoint(): Unit = RDDCheckpointData.synchronized {
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
4.2 persist 持久化RDD
- 如果该RDD已经有了storage level,但是还和指定的storage level不相等,那么抛出异常,不支持在一个RDD分配了storage level之后再分配一个storage level。
- 标记这个RDD为persisting。
- 设置RDD的storage level。
private def persist(newLevel:StorageLevel, allowOverride: Boolean):this.type = {
if (storageLevel!= StorageLevel.NONE&& newLevel != storageLevel&& !allowOverride) {
throw new UnsupportedOperationException(
"Cannotchange storage level of an RDD after it was already assigned a level")
}
// If this isthe first time this RDD is marked for persisting, register it
// with the SparkContext for cleanupsand accounting. Do this only once.
if (storageLevel== StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
storageLevel = newLevel
this
}
4.3 RDD的doCheckpoint方法
当调用DAGScheduler的runJob的时候,开始调用RDD的doCheckpoint方法。
- 该rdd是否已经调用doCheckpoint,如果还没有,则开始处理。
- 查看是否需要把该rdd的所有依赖即血缘全部checkpoint,如果需要,血缘上的每一个rdd递归调用该方法。
- 调用RDDCheckpointData的checkpoint方法。
private[spark] def doCheckpoint(): Unit = {
RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {
// 该rdd是否已经调用doCheckpoint,如果还没有,则开始处理
if (!doCheckpointCalled) {
doCheckpointCalled = true
// 判断RDDCheckpointData是否已经定义了,如果已经定义了
if (checkpointData.isDefined) {
// 查看是否需要把该rdd的所有依赖即血缘全部checkpoint
if (checkpointAllMarkedAncestors) {
// 血缘上的每一个rdd递归调用该方法
dependencies.foreach(_.rdd.doCheckpoint())
}
// 调用RDDCheckpointData的checkpoint方法
checkpointData.get.checkpoint()
} else {
dependencies.foreach(_.rdd.doCheckpoint())
}
}
}
}
4.4 RDDCheckpointData的checkpoint
- 将checkpoint的状态从Initialized置为CheckpointingInProgress。
- 调用子类的doCheckpoint,创建一个新的CheckpointRDD。
- 将checkpoint状态置为Checkpointed状态,并且改变rdd之前的依赖,设置父rdd为新创建的CheckpointRDD。
final def checkpoint(): Unit = {
// 将checkpoint的状态从Initialized置为CheckpointingInProgress
RDDCheckpointData.synchronized {
if (cpState == Initialized) {
cpState = CheckpointingInProgress
} else {
return
}
}
// 调用子类的doCheckpoint,我们以ReliableCheckpointRDD为例,创建一个新的CheckpointRDD
val newRDD = doCheckpoint()
// 将checkpoint状态置为Checkpointed状态,并且改变rdd之前的依赖,设置父rdd为新创建的CheckpointRDD
RDDCheckpointData.synchronized {
cpRDD = Some(newRDD)
cpState = Checkpointed
rdd.markCheckpointed()
}
}
4.5 RDDCheckpointData的doCheckpoint
我们以ReliableCheckpointRDD为例,将rdd的数据写入HDFS中checkpoint目录,并且创建CheckpointRDD。
protected override def doCheckpoint(): CheckpointRDD[T] = {
// 将rdd的数据写入HDFS中checkpoint目录,并且创建CheckpointRDD
val newRDD = ReliableCheckpointRDD.writeRDDToCheckpointDirectory(rdd, cpDir)
if (rdd.conf.getBoolean("spark.cleaner.referenceTracking.cleanCheckpoints", false)) {
rdd.context.cleaner.foreach { cleaner =>
cleaner.registerRDDCheckpointDataForCleanup(newRDD, rdd.id)
}
}
logInfo(s"Done checkpointing RDD ${rdd.id} to $cpDir, new parent is RDD ${newRDD.id}")
newRDD
}
4.6 ReliableCheckpointRDD的writeRDDToCheckpointDirectory
将rdd的数据写入HDFS中checkpoint目录,并且创建CheckpointRDD。
def writeRDDToCheckpointDirectory[T: ClassTag](
originalRDD: RDD[T],
checkpointDir: String,
blockSize: Int = -1): ReliableCheckpointRDD[T] = {
val sc = originalRDD.sparkContext
// 创建checkpoint输出目录
val checkpointDirPath = new Path(checkpointDir)
// 获取HDFS文件系统API接口
val fs = checkpointDirPath.getFileSystem(sc.hadoopConfiguration)
// 创建目录
if (!fs.mkdirs(checkpointDirPath)) {
throw new SparkException(s"Failed to create checkpoint path $checkpointDirPath")
}
// 将配置文件信息广播到所有节点
val broadcastedConf = sc.broadcast(
new SerializableConfiguration(sc.hadoopConfiguration))
// 重新启动一个job,将rdd的分区数据写入HDFS
sc.runJob(originalRDD,
writePartitionToCheckpointFile[T](checkpointDirPath.toString, broadcastedConf) _)
// 如果rdd的partitioner不为空,则将partitioner写入checkpoint目录
if (originalRDD.partitioner.nonEmpty) {
writePartitionerToCheckpointDir(sc, originalRDD.partitioner.get, checkpointDirPath)
}
// 创建一个CheckpointRDD,该分区数目应该和原始的rdd的分区数是一样的
val newRDD = new ReliableCheckpointRDD[T](
sc, checkpointDirPath.toString, originalRDD.partitioner)
if (newRDD.partitions.length != originalRDD.partitions.length) {
throw new SparkException(
s"Checkpoint RDD $newRDD(${newRDD.partitions.length}) has different " +
s"number of partitions from original RDD $originalRDD(${originalRDD.partitions.length})")
}
newRDD
}
4.7 RDD的iterator方法
-
当持久化RDD的时候,执行task的时候,会遍历RDD指定分区的数据,在持久的时候,因为指定了storage level,所以我们会调用getOrCompute获取数据,由于第一次还没有持久化过,所以会先计算。但是数据还没有被持久化,所以此时先把数据持久化到磁盘(假设持久化时就指定了StorageLevel=DISK_ONLY),然后再把block数据缓存到本地内存。
-
进行checkpoint操作时,会启动一个新的job来处理checkpoint任务。当执行checkpoint的任务来执行RDD的iterator方法时,此时我们知道该RDD的持久化级别不为空,则从BlockManager获取出结果来,因为已经持久化过了所以不需要进行计算。如果持久化的数据此时已经丢失呢,怎么办呢?即storage level为空了,这此时就会调用computeOrReadCheckpoint方法,重新计算结果,然后写入checkpoint目录。
-
如果已经持久化和checkpoint了,那么此时如果有任务在iterator获取不到block,那么就会调用computeOrReadCheckpoint方法,此时已经物化过了,所以直接从原始RDD对应的父RDD(CheckpointRDD)的iterator方法,此时已经没有持久化级别,所以CheckpointRDD的iterator方法就会调用CheckpointRDD的compute方法从checkpoint文件读取数据。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
// 如果StorageLevel不为空,表示该RDD已经持久化过了,可能是在内存,也有可能是在磁盘,
// 如果是磁盘获取的,需要把block缓存在内存中
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
// 进行rdd partition的计算或者根据checkpoint读取数据
computeOrReadCheckpoint(split, context)
}
}
4.8 RDD的computeOrReadCheckpoint方法
如果checkpoint状态已经置为checkpointed了,表示checkpoint已经完成,这时候从checkpoint获取;如果还是checkpointInProgress,则表示持久化数据丢失,或者根本就没有持久化,所以需要原来的RDD的compute方法重新计算结果。
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] = {
// 当前rdd是否已经checkpoint和物化了,如果已经checkpoint,则调用父类的CheckpointRDD的iterator方法获取
// 如果没有则开始计算
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {
// 则调用rdd的compute方法开始计算,返回一个Iterator对象
compute(split, context)
}
}
4.9 CheckpointRDD的compute方法
- 创建checkpoint文件
- 从HDFS上的checkpoint文件读取checkpoint过的数据
override def compute(split: Partition, context: TaskContext): Iterator[T] = {
// 创建checkpoint文件
val file = new Path(checkpointPath, ReliableCheckpointRDD.checkpointFileName(split.index))
// 从HDFS上的checkpoint文件读取checkpoint过的数据
ReliableCheckpointRDD.readCheckpointFile(file, broadcastedConf, context)
}