版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/86232277
1 Spark Checkpoint
- 有些时候,Spark应用程序特别复杂,从初始的RDD开始,到最后整个应用程序完成,有非常多的步骤,比如超过20 个 transformation 操作。而且整个应用运行的时间也特别长;这种情况就比较适合 checkpoint 。因为对于特别复杂的 Spark 应用,有很高的风险,会出现某个要反复使用的 RDD ,因为节点的故障,虽然之前持久化过,但是还是导致数据丢失了。也就是出现失败的时候,没有容错机制,所以当后面的 transfroamtion 操作,又要使用该 RDD 时,就会发现数据丢失了(CacheManager),此时如果没有进行容错处理的话,那么可能就又要重新计算一次数据;
-checkpoint,对于一个复杂的RDD chain,如果担心中间某些关键的在后面反复使用的 RDD,可能会因为节点的故障,导致持久化的数据丢失,那么就可以针对该 RDD 格外启动 checkpoint 机制,实现容错和高复用; - 要先调用
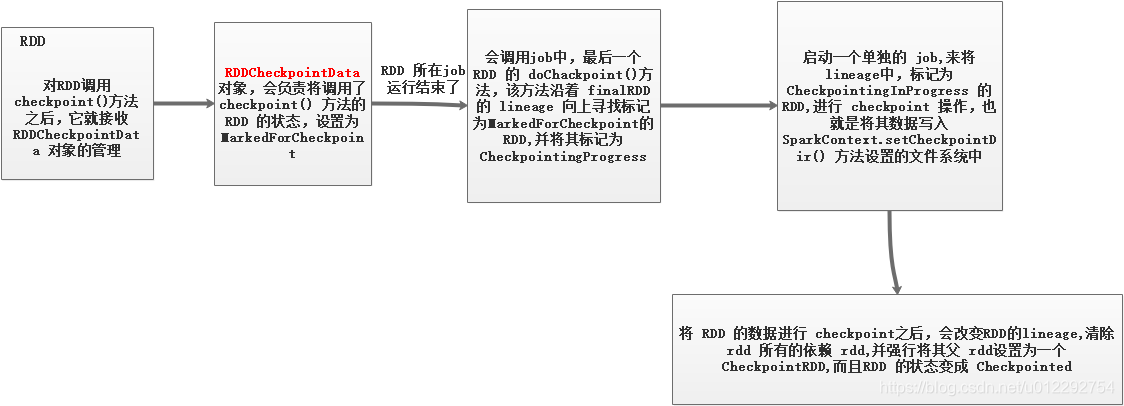
SparkContext的setCheckpoint()方法,设置一个容错的文件系统的目录,比如说 HDFS; 然后,对 RDD 调用checkpoint()方法。之后,在RDD 所处的 job 运行结束之后,会启动一个单独的 job ,来将 checkpoint 过的RDD 数据写入 之前设置的文件系统,进行高可用,容错的持久化操作; - 实现了 checkpoint 之后,后续再某个 task 又调用该 rdd 的
iterator()方法时,就实现了高容错机制,即使 rdd 的持久化数据丢失,或者没有持久化,还是可以通过readCheckpointOrCompute()方法 优先从 rdd 的父 rdd —— CheckpointRDD 中读取,HDFS(外部文件系统)的数据。 - 默认情况,如果某个 rdd 没有持久化,还设置了 checkpoint ,那么就悲剧了,本来这个 job 都执行结束了,但是由于中间的 rdd 没有持久化,那么 checkpoint job 想要将 rdd 的数据写入外部文件系统的话,还得从 rdd 之前所有的 rdd ,全部重新计算一次,然后计算出 rdd 的数据,再将其 checkpoint 到外部文件系统。
- 所以建议对要 checkpoint 的 rdd ,使用 persist(StorgeLevel.DISK_ONLY),该 rdd 计算之后,就直接将其持久化到磁盘上。后面进行 checkpoint 操作时,直接从磁盘上读取 rdd 的数据,并 checkpoint 到外部文件系统,不需要重新计算一次 rdd 。
1.1 Checkpoint 和 持久化的区别
- 持久化,只是将数据保存在
BlockManager,但是 rdd 的lineage是不变的; checkpoint执行完之后,rdd 已经没有之前所谓的依赖 rdd 了,而只有一个强行为其设置的CheckpointRDD。也就是说,checkpoint之后,rdd 的lineage就改变了。- 持久化的数据丢失的可能性更大,磁盘或者内存可能丢失;但是 checkpoint 的数据通常保存在容错、高可用的文件系统,比如 HDFS;