原文地址:https://blog.csdn.net/zhanglh046/article/details/78486051
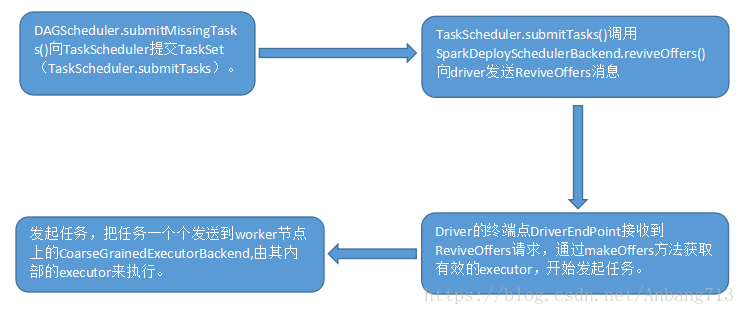
TaskScheduler是一个接口,DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler。TaskSchduler的核心任务是提交Taskset到集群运算并汇报结果。其执行过程如下图所示:
- 为TaskSet创建和维护一个TaskSetManager并追踪任务的本地性以及错误信息。
- 遇到Straggle任务会放到其他的节点进行重试。
- 向DAGScheduler汇报执行情况,包括在Shuffle输出lost的时候报告fetch failed错误等信息。
在Standalone模式下StandaloneSchedulerBackend在启动的时候构造AppClient实例并在该实例start的时候启动了ClientEndpoint这个消息循环体。ClientEndpoint在启动的时候会向Master注册当前程序。而StandaloneSchedulerBackend的父类CoarseGrainedSchedulerBackend在start的时候会实例化类型为DriverEndpoint(这就是我们程序运行时候的经典对象的Driver)的消息循环体,StandaloneSchedulerBackend专门负责收集Worker上的资源信息,当ExecutorBackend启动的时候会发送RegisteredExecutor信息向DriverEndpoint注册,此时StandaloneSchedulerBackend就掌握了当前应用程序拥有的计算资源,TaskScheduler就是通过StandaloneSchedulerBackend拥有的计算资源来具体运行Task。
一、核心属性
- Int maxTaskFailures: task最多失败次数
- Boolean isLocal: 是否本地运行
- AtomicLong nextTaskId:递增的task id
- SPECULATION_INTERVAL_MS : 多久检查一次推测任务
- CPUS_PER_TASK: 每一个任务需要的cpu核数
- HashMap[Long, TaskSetManager]taskIdToTaskSetManager: 为TaskSet创建和维护一个TaskSetManager并追踪任务的本地性以及错误信息
- HashMap[Long, String] taskIdToExecutorId: 维护的taskId和executorId的映射
- HashMap[String, HashSet[Long]]executorIdToRunningTaskIds:每一个execuotor上运行的task集合的映射
- HashMap[String, HashSet[String]] hostToExecutors: 主机名和executors之间的映射
- HashMap[String, HashSet[String]] hostsByRack:机架和主机名的映射
- HashMap[String, String] executorIdToHost: executorID和主机名映射
- DAGScheduler dagScheduler:
- SchedulerBackend backend:调度器的通信终端
- SchedulableBuilder schedulableBuilder:调度模式,比如FIFO或者Fair
- schedulingModeConf:所配置的调度模式,默认FIFO
- Pool rootPool: 用于调度TaskManager
- TaskResultGetter taskResultGetter: Task结果获取器
二、重要方法
2.1 初始化和启动方法
我们知道,在SparkContext初始化的时候,就会初始化TaskScheduler以及SchedulerBackend,并且会初始化和启动TaskScheduler。
/** SparkContext.scala*/
def initialize(backend:SchedulerBackend) {
// 初始化SchedulerBackend
this.backend= backend
// 创建一个Pool用于调度TasksetManager
rootPool = new Pool("",schedulingMode, 0, 0)
// 通过配置的调度模式,构建SchedulableBuilder
schedulableBuilder= {
schedulingModematch{
case SchedulingMode.FIFO=>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR=>
new FairSchedulableBuilder(rootPool,conf)
case _ =>
throw new IllegalArgumentException(s"Unsupportedspark.scheduler.mode:$schedulingMode")
}
}
// 开始构建pool
schedulableBuilder.buildPools()
}
/** TaskScheduler.scala*/
override def start() {
// 启动SchedulerBackend的start方法,StandaloneSchedulerBackend在
// 启动的时候构造AppClient实例并在该实例start的时候启动了ClientEndpoint
// 这个消息循环体。ClientEndpoint在启动的时候会向Master注册当前程序。
// 父类CoarseGrainedSchedulerBackend在start的时候会实例化类型为DriverEndpoint(这就是我们程序运行时候的经典对象的Driver)
backend.start()
// 如果非本地执行,则检查是否需要推测
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
// 如果可以推测则调用speculationSchedule定时调度checkSpeculatableTasks方法
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
2.2 submitTasks 提交task
/** TaskScheduler.scala*/
override def submitTasks(taskSet: TaskSet) {
// 获取task集合,TaskSet是对Task的封装
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
// 创建TaskSetManager,用于跟踪每一个Task,task失败进行重试等
val manager = createTaskSetManager(taskSet, maxTaskFailures)
// 获取该TaskSet所对应的stageId
val stage = taskSet.stageId
// 构建一个<stageId,HashMap<stageAttemptId,TaskSetManager>映射
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 将这个创建TaskSetManager放入到映射中
stageTaskSets(taskSet.stageAttemptId) = manager
// 如果有冲突的TaskSet,则抛异常
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 申请任务调度,有FIFO和FAIR两种策略。根据executor的空闲资源状态
// 及locality策略将task分配给executor。调度的数据结构封装为Pool类,
// 对于FIFO,Pool就是TaskSetManager的队列;对于Fair,则是TaskSetManager
// 组成的树。Pool维护TaskSet的优先级,等待executor接受资源offer(resourceOffer)
// 的时候出列并提交executor计算
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
// 不是本地且没有接收task,启动一个timer定时调度,如果一直没有task就警告,直到有task
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
// SchedulerBackend向driver发送ReviveOffers消息
backend.reviveOffers()
}
/** CoarseGrainedSchedulerBackend.scala(SparkDeploySchedulerBackend的父类)*/
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}2.3 DriverEndPoint类的主要方法
2.3.1 receive()
override def receive: PartialFunction[Any, Unit] = {
// 如果接收StatusUpdate消息,用于状态更新
case StatusUpdate(executorId, taskId, state, data) =>
// 调用TaskSchedulerImpl#statusUpdate进行更新
scheduler.statusUpdate(taskId, state, data.value)
// 如果Task处于完成状态
if (TaskState.isFinished(state)) {
// 通过executor id获取ExecutorData
executorDataMap.get(executorId) match {
// 如果存在数据
case Some(executorInfo) =>
// 则更新executor的cpu核数
executorInfo.freeCores += scheduler.CPUS_PER_TASK
// 获取集群中可用的executor列表,发起task
makeOffers(executorId)
case None =>
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
// 如果发送ReviveOffers消息
case ReviveOffers =>
// 获取集群中可用的executor列表,发起task
makeOffers()
// 如果是KillTask消息,表示kill掉这个task
case KillTask(taskId, executorId, interruptThread) =>
executorDataMap.get(executorId) match {
// 向Executor发送KillTask的消息
case Some(executorInfo) =>
executorInfo.executorEndpoint.send(KillTask(taskId, executorId, interruptThread))
case None =>
// Ignoring the task kill since the executor is not registered.
logWarning(s"Attempted to kill task $taskId for unknown executor $executorId.")
}
}2.3.2 receiverAndReply()
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// 接收RegisterExecutor表示向Executor注册
case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls) =>
// 如果已经注册过,则会返回RegisterExecutorFailed向executor注册失败的消息
if (executorDataMap.contains(executorId)) {
executorRef.send(RegisterExecutorFailed("Duplicate executor ID: " + executorId))
context.reply(true)
} else {
// 获取executor的地址
val executorAddress = if (executorRef.address != null) {
executorRef.address
} else {
context.senderAddress
}
logInfo(s"Registered executor $executorRef ($executorAddress) with ID $executorId")
// 更新<address,executorId>集合
addressToExecutorId(executorAddress) = executorId
// 重新计算现在的总的CPU核数
totalCoreCount.addAndGet(cores)
// 计算现在已经注册executor数量
totalRegisteredExecutors.addAndGet(1)
// 构建一个Executor数据
val data = new ExecutorData(executorRef, executorRef.address, hostname,
cores, cores, logUrls)
// 然后开始注册executor
CoarseGrainedSchedulerBackend.this.synchronized {
executorDataMap.put(executorId, data)
if (currentExecutorIdCounter < executorId.toInt) {
currentExecutorIdCounter = executorId.toInt
}
if (numPendingExecutors > 0) {
numPendingExecutors -= 1
logDebug(s"Decremented number of pending executors ($numPendingExecutors left)")
}
}
// 然后返回消息RegisteredExecutor
executorRef.send(RegisteredExecutor)
context.reply(true)
listenerBus.post(
SparkListenerExecutorAdded(System.currentTimeMillis(), executorId, data))
// 获取有效的executor,开始发起任务
makeOffers()
}
// 接收StopDriver消息,表示停止Driver
case StopDriver =>
context.reply(true)
stop()
// 接收StopExecutors消息,表示停止Executor
case StopExecutors =>
logInfo("Asking each executor to shut down")
// 遍历注册所有的executor,然后向Executor终端发送StopExecutor消息
for ((_, executorData) <- executorDataMap) {
executorData.executorEndpoint.send(StopExecutor)
}
context.reply(true)
// 接收RemoveExecutor消息,表示删除Executor
case RemoveExecutor(executorId, reason) =>
executorDataMap.get(executorId).foreach(_.executorEndpoint.send(StopExecutor))
removeExecutor(executorId, reason)
context.reply(true)
// 接收RetrieveSparkAppConfig消息,表示获取application相关的配置信息
case RetrieveSparkAppConfig =>
val reply = SparkAppConfig(sparkProperties,
SparkEnv.get.securityManager.getIOEncryptionKey())
context.reply(reply)
}2.3.3 removeExecutor()
private def removeExecutor(executorId: String, reason: ExecutorLossReason): Unit = {
logDebug(s"Asked to remove executor $executorId with reason $reason")
// 获取对应的ExecutorData
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
// 从相关集合或者列表移除该executorId
val killed = CoarseGrainedSchedulerBackend.this.synchronized {
addressToExecutorId -= executorInfo.executorAddress
executorDataMap -= executorId
executorsPendingLossReason -= executorId
executorsPendingToRemove.remove(executorId).getOrElse(false)
}
// 重新计算CPU核数
totalCoreCount.addAndGet(-executorInfo.totalCores)
totalRegisteredExecutors.addAndGet(-1)
scheduler.executorLost(executorId, if (killed) ExecutorKilled else reason)
listenerBus.post(
SparkListenerExecutorRemoved(System.currentTimeMillis(), executorId, reason.toString))
case None =>
scheduler.sc.env.blockManager.master.removeExecutorAsync(executorId)
logInfo(s"Asked to remove non-existent executor $executorId")
}
}2.3.4 makeOffers获取有效的executor,开始发起任务
private def makeOffers() {
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
private def makeOffers(executorId: String) {
// 获取集群中可用的executor列表
if (executorIsAlive(executorId)) {
val executorData = executorDataMap(executorId)
// 创建WorkerOffer,只是表示executor上有可用的空闲资源
val workOffers = IndexedSeq(
new WorkerOffer(executorId, executorData.executorHost, executorData.freeCores))
// 发起task
launchTasks(scheduler.resourceOffers(workOffers))
}
}2.3.5 launchTasks()
// 发起task,会把任务一个个发送到worker节点上的CoarseGrainedExecutorBackend,由其内部的executor来执行
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
// 将每一个task序列化
val serializedTask = ser.serialize(task)
// 检查task序列化之后是否超过所允许的rpc消息的最大值
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
} else {
// 获取对应的ExecutorData数据
val executorData = executorDataMap(task.executorId)
// Executor的剩余核数就需要减少一个task需要的cpu核数
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
// 然后向Executor终端发送LaunchTask,发起task
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}2.4 resourceOffers 为executor分配task
计算每一个TaskSetMangaer的本地化级别(locality_level);并且对task set尝试使用最小的本地化级别(locality_level), 将task set的task在executor上启动;如果启动不了,放大本地化级别,以此类推直到某种本地化级别尝试成功。
def resourceOffers(offers:IndexedSeq[WorkerOffer]):Seq[Seq[TaskDescription]] = synchronized {
// 标记每一个slave是可用的且记住主机名
var newExecAvail= false
// 遍历有可用资源的Executor
for (o <- offers) {
// 如果没有包含了这个executor的host,初始化一个集合,存放host
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) =new HashSet[String]()
}
// 如果<executorId,taskId集合>不包含这个executorId
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host)+= o.executorId
// 通知DAGScheduler添加executor
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) =HashSet[Long]()
newExecAvail = true
}
// 遍历主机所在机架
for (rack <- getRackForHost(o.host)) {
// 更新hosts和机架的映射
hostsByRack.getOrElseUpdate(rack,new HashSet[String]())+= o.host
}
}
// 将WorkerOffer打乱,做到负载均衡
val shuffledOffers= Random.shuffle(offers)
// 构建一个task列表,然后分配给每一个worker
val tasks= shuffledOffers.map(o=> new ArrayBuffer[TaskDescription](o.cores))
// 有效可用的CPU核数
val availableCpus= shuffledOffers.map(o=> o.cores).toArray
// 从调度池获取按照调度策略排序好的TaskSetManager
val sortedTaskSets= rootPool.getSortedTaskSetQueue
// 如果有新加入的executor,需要重新计算数据本地性
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// 为排好序的TaskSetManager列表分配资源,分配原则是就近原则,按照顺序为
// PROCESS_LOCAL, NODE_LOCAL, NO_PREF,RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask= false
var launchedTaskAtCurrentMaxLocality=false
// 计算每一个TaskSetMangaer的本地化级别(locality_level),
// 并且对task set尝试使用最小的本地化级别(locality_level),将task set的task在executor上启动
// 如果启动不了,放大本地化级别,以此类推直到某种本地化级别尝试成功
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality= resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers,availableCpus, tasks)
launchedAnyTask|= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
// 如果这个task在任何本地化级别都启动不了,有可能在黑名单
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size> 0) {
hasLaunchedTask= true
}
return tasks
}
2.5 resourceOfferSingleTaskSet 分配单个TaskSet里的task到executor
调用resourceOffer方法找到在executor上,哪些TaskSet的task可以通过当前本地化级别启动;遍历在该executor上当前本地化级别可以运行的task。
private defresourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean = {
// 默认发起task为false
var launchedTask= false
// 遍历所有executor
for (i <- 0 until shuffledOffers.size) {
// 获取executorId和host
val execId= shuffledOffers(i).executorId
val host= shuffledOffers(i).host
// 必须要有每一个task可供分配的的CPU核数,否则直接返回
if (availableCpus(i) >=CPUS_PER_TASK) {
try {
// 调用resourceOffer方法找到在executor上,哪些TaskSet的task可以通过当前本地化级别启动
// 遍历在该executor上当前本地化级别可以运行的task
for (task <- taskSet.resourceOffer(execId,host, maxLocality)) {
// 如果存在,则把每一个task放入要在当前executor运行的task数组里面
// 即指定executor要运行的task
tasks(i) += task
// 将相应的分配信息加入内存缓存
val tid= task.taskId
taskIdToTaskSetManager(tid) =taskSet
taskIdToExecutorId(tid) =execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >=0)
launchedTask = true
}
} catch {
case e:TaskNotSerializableException =>
logError(s"Resource offer failed, task set${taskSet.name} was not serializable")
// Do notoffer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
}
}
}
return launchedTask
}