在前面几篇文章中,介绍了Spark的启动流程Spark内核架构流程深度剖析,Spark源码分析之DAGScheduler详解,Spark源码解读之Executor以及Task工作原理剖析,Spark源码解读之Executor以及Task工作原理剖析等Spark重要组件的源码剖析之后,接着之前的文章,本篇文章来剖析Shuffle的原理,shuffle阶段无论是mapreduce还是Spark都是其核心以及难点,了解了其shuffle操作原理之后,更加有利于我们调优系统 ,避免不必要的错误。
转载请标明原文地址:原文地址
spark的shuffle操作有之前的版本和现在优化后的版本,它可以通过一个参数来调节,具体我们后面会详述,本篇主要从以下几个方面来深入Shuffle原理:
- 普通shuffle操作的原理剖析
- 优化后的shuffle操作原理剖析
- shuffle源码剖析
普通shuffle操作的原理剖析
首先来看看早期没有任何优化的shuffle操作的原理,如下图是shuffle简单原理图:
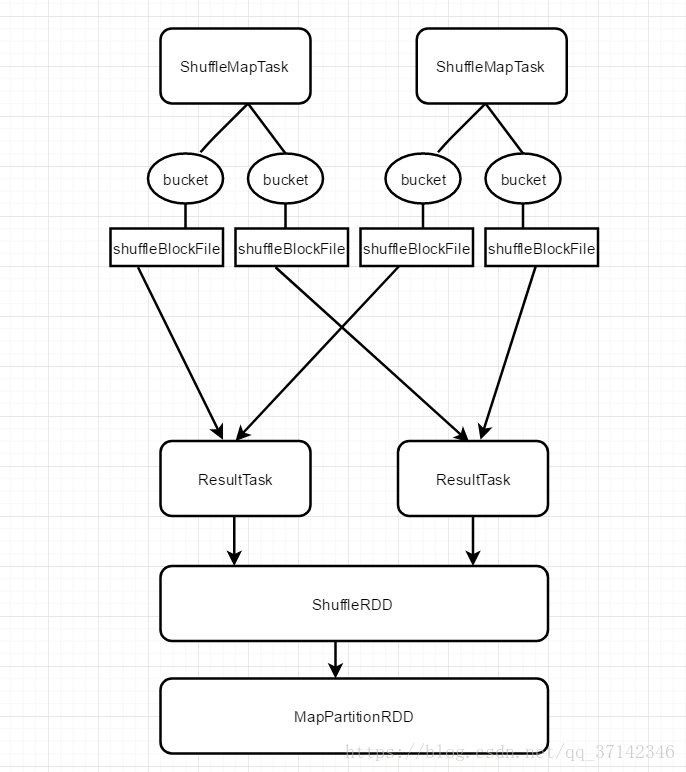
这里我们假设每一个节点上运行着两个ShuffleMapTask,每一个ShuffleMapTask都会为每一个ResultTask创建一个bucket缓存,并且接着会将bucket缓存中的数据刷新到磁盘文件shuffleBlockFile中,ShuffleMapTask刷新到磁盘中的数据信息会封装在MapStatus中,发送到Driver的DAGScheduler的MapOutputTracker中,而每一个ResultTask会用BlockStoreShuffleFetcher去MapOutputTracker中获取自己所需要的数据的信息,然后通过底层的BlockManager将数据拉取过来。
将数据拉取过来之后,会将这些数据组成一个RDD,即ShuffleRDD,优先存入内存当中,其次再写入磁盘中。然后每一个ResultTask针对这些RDD数据执行自己的聚合操作或者算子函数生成MapPartitionRDD。
以上就是普通Shuffle操作的执行原理,从上图我们可以发现一个问题,每一个ShuffleMapTask都需要为每一个ResultTask生成一个文件和bucket缓存,假设有100个ShuffleMapTask,100个ResultTask,那么就需要总共生成10000个文件,此时会有大量的磁盘IO操作,严重的影响shuffle的性能。
因此,在后期的新版本的Spark中,加入了优化操作,具体原理我们来看看。
优化后的shuffle操作原理剖析
优化后的Shuffle操作原理图如下:
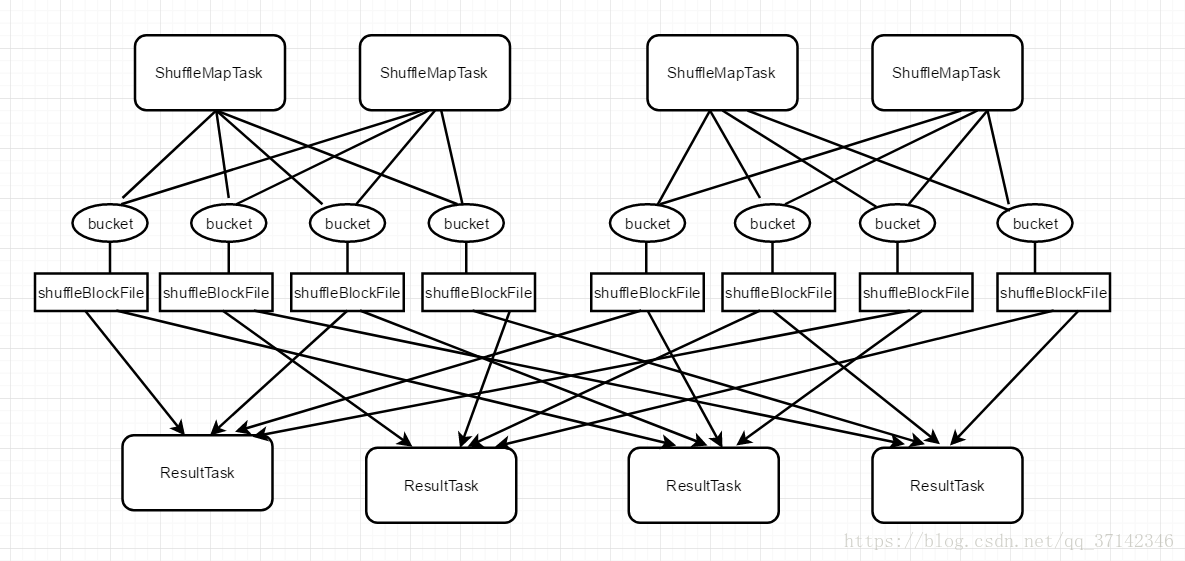
这里假设我们的服务器上有两个CPU cores,运行着4个ShuffleMapTask,因此每次可以并行执行两个两个ShuffleMapTask,在之前的版本中,当前并行执行的一批ShuffleMapTask执行完毕之后执行下一批时会重新生成bucket缓存,而且在刷新到磁盘上的时候也会重新生成ShuffleBlockFile。但是在优化后的Shuffle操作中它不会重新生成缓存和磁盘文件,而是将数据写入之前的缓存和磁盘文件中,即合并了多个ShuffleMpaTask产生的文件,这也叫做consolidation机制。在多个ShuffleMapTask合并产生的文件称为一组ShuffleGroup,里面存储了多个ShuffleMapTask的数据,每个ShuffleMapTask的数据称为一个segment,此外还会通过一些索引来标识每个ShuffleMapTask在ShuffleBlockFile中的位置以及偏移量,来进行区分不同的ShuffleMapTask产生的数据。
优化参数的设置只需在SparkConf中设置即可,即设置spark.shuffle.consolidateFiles参数为true即可,可以看出来,在优化后的shuffle操作,它产生的磁盘文件是cpu core数量*ResultTask的数量,比如这里假设了2个cpu core,有100个ResultTask,因此会产生200个磁盘文件,相比之前没有优化的Shuffle操作,减少了20倍的磁盘文件,对系统的性能有很大的提升。
对Spark Shuffle操作有以下两个特点:
- 在早期版本中,bucket缓存十分重要,因为ShuffleMapTask只有将数据写入缓存中,然后才会刷新到磁盘中,但是如果缓存过多,有可能会导致OutOfMemory,因此,在新版中,进行了优化设置,缩小了缓存的大小,默认是100KB,当超过这个阀值时,就会将数据一点点写入磁盘中。但是这样也有一个缺点,当数据过多的时候 ,会有大量的磁盘IO操作。
- 与MpaReduce的Shuffle不一样,MapReduce它必须将所有的数据写入磁盘文件之后才会去进行Reduce操作,因为MapReduce会对数据进行排序。但是Spark不会对数据进行排序,因此不需要等待全部数据写入磁盘就ResultTask就可以拉取数据进行计算。这样,明显比MapReduce快很多,但是MapReduce可以直接在Reduce端对每一个key的value进行计算,但是Spark由于实时拉取的机制,因此只有先执行action操作,进行Shuffle操作,生成对应的MapPartitionRDD,然后去进行计算。
shuffle源码剖析
在上面了解了Shuffle的原理之后,我们来简单看看其内部源码。
Shuffle操作会在stage之间进行操作,之前的stage会先将数据写入到磁盘,这里使用了HashShuffleWriter,在这个类中,我们来看看write方法:
/** Write a bunch of records to this task's output */
/**
* 将每个ShuffleMapTask计算出来的新的RDD的partition数据,写入本地磁盘
* @param records
*/
override def write(records: Iterator[_ <: Product2[K, V]]): Unit = {
//判断是否需要进行本地,如果是reduceByKey这种操作,则要进行聚合操作
//即dep.aggregator.isDefined为true
//dep.mapSideCombine也为true
val iter = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
//这里进行本地聚合操作,比如本地有(hello,1),(hello,1)
//则可以聚合成(hello,2)
dep.aggregator.get.combineValuesByKey(records, context)
} else {
records
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
records
}
//如果需要本地聚合,则先进行聚合
//然后遍历数据,对每一个数据,进行partition操作,默认的是HashPartitioner,并且生成bucketId
//也就表示这数据要写入哪一个bucket
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
//调用shuffleBlockManager.forMapTask()方法生成bucketId对应的writer,然后用writer将数据写入bucket
shuffle.writers(bucketId).write(elem)
}
}在写入bucket的时候,会调用shuffleBlockManager.forMapTask()方法生成bucketId对应的writer,然后用writer将数据写入bucket,因此我们进行forMapTask这个 方法中:
/**
* Get a ShuffleWriterGroup for the given map task, which will register it as complete
* when the writers are closed successfully
*/
/**
* 给每一个map task生成 一个ShuffleWriterGroup
*/
def forMapTask(shuffleId: Int, mapId: Int, numBuckets: Int, serializer: Serializer,
writeMetrics: ShuffleWriteMetrics) = {
new ShuffleWriterGroup {
shuffleStates.putIfAbsent(shuffleId, new ShuffleState(numBuckets))
private val shuffleState = shuffleStates(shuffleId)
private var fileGroup: ShuffleFileGroup = null
val openStartTime = System.nanoTime
//判断是否开启了consolidate优化,如果开启了,就不会为每一个bucket获取一个输出文件
//而是为每一个bucket获取一个ShuffleGroup的write
val writers: Array[BlockObjectWriter] = if (consolidateShuffleFiles) {
fileGroup = getUnusedFileGroup()
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
//首先生成一个唯一的blockId,然后用bucketId来调用ShuffleFileGroup的apply函数来获取一个writer
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
//使用blockManager.getDiskWriter()函数来获取一个writer
//实际上在开启优化配置后,对一个bucketId,不再是像之前一样获取一个独立的ShuffleBlockFile的writer
//而是获取ShuffleFileGroup中的一个writer
//这样就实现了多个ShufffleMapTask的输出文件的合并
blockManager.getDiskWriter(blockId, fileGroup(bucketId), serializer, bufferSize,
writeMetrics)
}
} else {
//如果没有进行shuffle优化配置,也会针对每一个shuffleMapTask创建一个ShuffleBlockFile
Array.tabulate[BlockObjectWriter](numBuckets) { bucketId =>
val blockId = ShuffleBlockId(shuffleId, mapId, bucketId)
val blockFile = blockManager.diskBlockManager.getFile(blockId)
// Because of previous failures, the shuffle file may already exist on this machine.
// If so, remove it.
//如果ShuffleBlockFile存在,则进行删除
if (blockFile.exists) {
if (blockFile.delete()) {
logInfo(s"Removed existing shuffle file $blockFile")
} else {
logWarning(s"Failed to remove existing shuffle file $blockFile")
}
}
//写入磁盘中
blockManager.getDiskWriter(blockId, blockFile, serializer, bufferSize, writeMetrics)
}
}将结果数据写入磁盘文件之后,就开始了Shuffle操作,Shuffle操作的入口在RDD包下的ShuffleRDD类中,源码如下:
/**
*shuffle的入口
*/
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
//这里会调用shuffleManager.getReader()来获取一个HashShuffleReader
//然后调用它的reader方法来拉取resultTask需要聚合的数据
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}在读取数据的时候使用的HashShuffleReader这个类。在这个类的read方法中:
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val ser = Serializer.getSerializer(dep.serializer)
//通过BlockStoreShuffleFetcher的fetch方法来从DAGScheduler的MapOutputTrackerMaster中获取
//自己需要的数据的信息,然后底层再通过对应的BlockManager拉取需要的数据
val iter = BlockStoreShuffleFetcher.fetch(handle.shuffleId, startPartition, context, ser)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
new InterruptibleIterator(context, dep.aggregator.get.combineCombinersByKey(iter, context))
} else {
new InterruptibleIterator(context, dep.aggregator.get.combineValuesByKey(iter, context))
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
// Convert the Product2s to pairs since this is what downstream RDDs currently expect
iter.asInstanceOf[Iterator[Product2[K, C]]].map(pair => (pair._1, pair._2))
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter = new ExternalSorter[K, C, C](ordering = Some(keyOrd), serializer = Some(ser))
sorter.insertAll(aggregatedIter)
context.taskMetrics.incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics.incDiskBytesSpilled(sorter.diskBytesSpilled)
sorter.iterator
case None =>
aggregatedIter
}
}这里会使用BlockStoreShuffleFetcher调用fetch方法来拉取所需要的数据,我们可以进行这个方法中简单看一下:
def fetch[T](
shuffleId: Int,
reduceId: Int,
context: TaskContext,
serializer: Serializer)
: Iterator[T] =
{
logDebug("Fetching outputs for shuffle %d, reduce %d".format(shuffleId, reduceId))
val blockManager = SparkEnv.get.blockManager
val startTime = System.currentTimeMillis
//获取一个全局的MapOutputTracker,并且调用其getServerStatuses方法
//注意这里传入了两个参数,shuffleId和reduceId
//shuffle有两个stage参与,因此shuffleId代表表示上一个stage,使用这个参数来获取
//上一个stage的ShuffleMapTask shuffle write输出的MapStatus数据信息
//在获取到MapStatus之后,还要使用reduceId来拉取当前stage需要获取的之前stage的ShuffleMapTask的输出文件信息
//这个getServerStatuses方法是需要走网络通信的,因为它要连接Driver上的DAGScheduler来获取MapOutputTracker上的数据信息
val statuses = SparkEnv.get.mapOutputTracker.getServerStatuses(shuffleId, reduceId)
logDebug("Fetching map output location for shuffle %d, reduce %d took %d ms".format(
shuffleId, reduceId, System.currentTimeMillis - startTime))
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(Int, Long)]]
for (((address, size), index) <- statuses.zipWithIndex) {
splitsByAddress.getOrElseUpdate(address, ArrayBuffer()) += ((index, size))
}
val blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = splitsByAddress.toSeq.map {
case (address, splits) =>
(address, splits.map(s => (ShuffleBlockId(shuffleId, s._1, reduceId), s._2)))
}
def unpackBlock(blockPair: (BlockId, Try[Iterator[Any]])) : Iterator[T] = {
val blockId = blockPair._1
val blockOption = blockPair._2
blockOption match {
case Success(block) => {
block.asInstanceOf[Iterator[T]]
}
case Failure(e) => {
blockId match {
case ShuffleBlockId(shufId, mapId, _) =>
val address = statuses(mapId.toInt)._1
throw new FetchFailedException(address, shufId.toInt, mapId.toInt, reduceId, e)
case _ =>
throw new SparkException(
"Failed to get block " + blockId + ", which is not a shuffle block", e)
}
}
}
}
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
SparkEnv.get.blockManager.shuffleClient,
blockManager,
blocksByAddress,
serializer,
SparkEnv.get.conf.getLong("spark.reducer.maxMbInFlight", 48) * 1024 * 1024)
val itr = blockFetcherItr.flatMap(unpackBlock)
val completionIter = CompletionIterator[T, Iterator[T]](itr, {
context.taskMetrics.updateShuffleReadMetrics()
})
new InterruptibleIterator[T](context, completionIter) {
val readMetrics = context.taskMetrics.createShuffleReadMetricsForDependency()
override def next(): T = {
readMetrics.incRecordsRead(1)
delegate.next()
}
}
}这个方法中主要会去连接Driver去MapOutputTracker中去获取数据信息,然后进行拉取。具体源代码读者可以自行去查看,本篇文章就介绍完毕,如有任何问题,欢迎指教。