目录
参考链接:
一、模型评估-bias and variance
验证集和测试集来自同一分布会更好;
常见情况如下:
训练集误差小(1%),验证集大(15%),为高方差,可能过拟合训练集了;
训练集误差大(15%),验证集大(16%),错误率几乎为0,高偏差,可能欠拟合,识别cat不准确;
训练集误差小(0.5%),验证集小(1%),低方差,低偏差;
训练集误差小(15%),验证集小(30%),高方差,高偏差;过拟合部分数据;
解决方法:
首先要明确问题 is bias or varianceor both?
先判断是否为高偏差(bias):1)用更大的网络;2)加大训练时间;3)或者使用其他不同的网络结构;
不是高偏差,则判断是否为高方差(variance):1)用更多的训练数据;2)正则化;3)或者使用其他不同的网络结构;
不断优化使error最小;
二、L1、L2正则化:
1、添加L1和L2正则化有什么用?
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型(很多0),可以用于特征选择;
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合;
2、为什么L1可以实现稀疏化,L2不可以?
参考链接:
1)数学公式角度

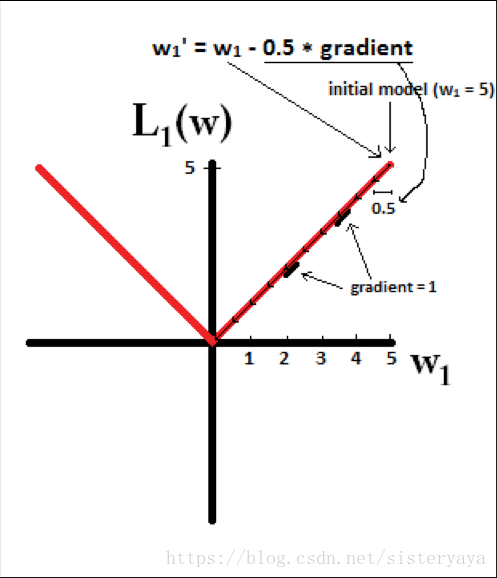
所以(不失一般性,我们假定:wi等于不为0的某个正的浮点数,学习速率η 为0.5)
L1的权值更新公式为:

也就是说权值每次更新都固定减少一个特定的值(比如0.5),那么经过若干次迭代之后,权值就有可能减少到0。
L2的权值更新公式为:

也就是说权值每次都等于上一次的1/2,那么,虽然权值不断变小,但是因为每次都等于上一次的一半,所以很快会收敛到较小的值但不为0。

总结:
L1能产生等于0的权值,即能够剔除某些特征在模型中的作用(特征选择),即产生稀疏的效果。
L2可以得迅速得到比较小的权值,但是难以收敛到0,所以产生的不是稀疏而是平滑的效果。
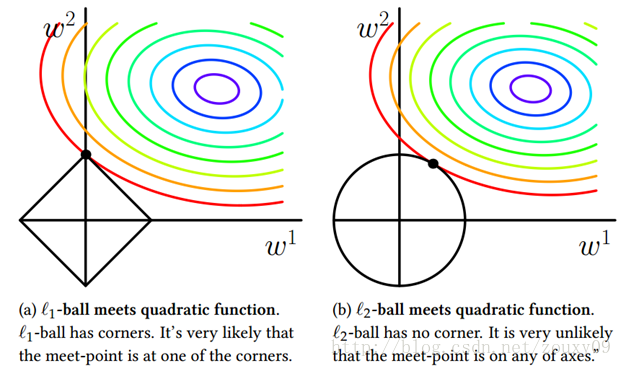
2)几何图像角度
1、L1正则

越大,方形越小,也可以取到很小的值;
2、L2正则

在二维空间表示,左边为L1函数,图示最优解落在坐标轴上,意味着某些参数为0,从而实现稀疏化;右边为L2,函数图像为圆形,与方形相比,没有棱角,在坐标轴相交的可能性大大减小,因此没有稀疏性。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型(很多0),可以用于特征选择;
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合;
3、那为什么L2正则化可以获得值很小的参数?

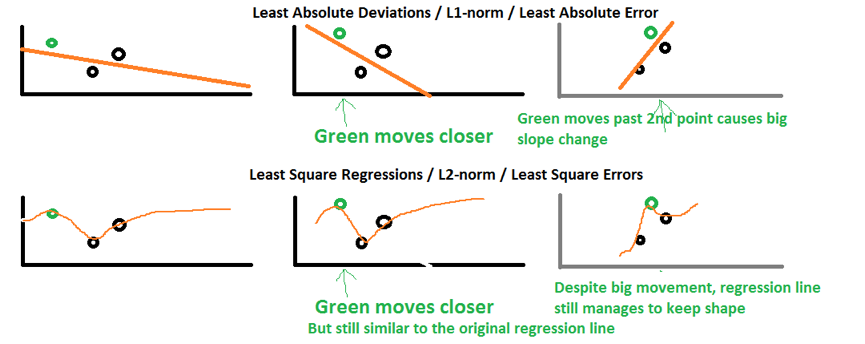
4、L2比L1稳定?
绿色的样本点稍作变动,就会影响回归线的斜率,L1变化很大,会影响到其他点的预测值,相比之下,L2比较稳定;
三、神经网络解决过拟合
1、L2正则化
可避免权值矩阵过大;越大,衰减的越快 ;
过大,
时,会减少很多隐藏单元的影响,但依然有很深的深度,易欠拟合;
加了正则之后,J才能在调幅范围内单调递减;
2、dropout
类似L2正则,压缩梯度;可以一些层用dropout,一些不用,因为有的隐藏层的单元数较少不需要再dropout了;
每次迭代,都会随机删减一些神经元,此时J不能再被明确定义,梯度下降的性能很难检查;可以先设keep_prob=1,即不用dropout,确保J函数是单调递减的后再打开dropout;
3、early stopping
验证集上的error一般下降后,会在某个位置上升,early stopping就是说神经网络在这个迭代过程中已经表现得很好了,可以停止训练了;
刚开始时, 为随机初始值,可能很小,随着迭代次数的增加,
增加,early stopping能够得到一个中等大小的
值;
L2:易搜索,但需要尝试很多值,计算代价高;
early stopping只需要运行一次梯度下降,就可以找出small,mid-size,large的 值,代价小;
4、特征归一化
当特征分布不平衡时,训练得到的 数量级差别大,用梯度下降时,选较小的学习因子来避免发生震荡,一旦较大,会震荡,不再但单调下降;
所以,对特征进行零均值化,方差归一化处理,使特征分布在相似的范围内,代价函数 J 优化起来更简单、快捷,也保证了单调递减;