偏差大(欠拟合):训练集和测试集的准确率都很低;通常可以增加单层神经元数量、增加层数来优化
方差大(过拟合):训练集的正确率高,测试集(或dev)的正确率比训练集低一些;通常可以增大正则化lambda的值、增加训练集数据量解决
可以通过在训练模型过程中正则化来解决过拟合问题
l2正则化,在原来的cost function基础上添加l2 regularization cost

对于反向传播,dW需要加上:
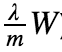
代码实现:
#计算cost function

L2_regularization_cost = lambd/(2*m)*(np.sum(np.square(W1)) + np.sum(np.square(W2)) + np.sum(np.square(W3)))
cost = cross_entropy_cost + L2_regularization_cost
#反向传播
dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m*W3
dW2 = 1./m * np.dot(dZ2, A1.T) + lambd/m*W2
dW1 = 1./m * np.dot(dZ1, X.T) + lambd/m*W1
dropout
每次训练中,随机关闭神经元。被关闭的神经元在前向和后向传播中都不起作用。由于dropout随机关闭神经元,每次遍历相当于用不同的模型,这使得对某个神经元的依赖性降低。
前向传播代码实现
D1 = np.random.rand(A1.shape[0],A1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...),维度与a1相同
D1 = np.int64(D1 < keep_prob) # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
A1 = np.multiply(A1,D1) # Step 3: shut down some neurons of A1,drop掉一部分神经元
A1 = np.divide(A1,keep_prob) #step 4:通过除以keep prob,保持cost与预期基本一致
D2 = np.random.rand(A2.shape[0],A2.shape[1]) # Step 1: initialize matrix D2 = np.random.rand(..., ...)
D2 = np.int64(D2 < keep_prob) # Step 2: convert entries of D2 to 0 or 1 (using keep_prob as the threshold)
A2 = np.multiply(A2,D2) # Step 3: shut down some neurons of A2
A2 = np.divide(A2,keep_prob) #step 4:通过除以keep prob,保持cost与预期基本一致
后向传播代码实现
dA2 = np.multiply(dA2,D2) # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation
dA2 = np.divide(dA2,keep_prob) # Step 2: Scale the value of neurons that haven't been shut down
参考Andrew Ng深度学习课程。