神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。如今,神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向–深度学习的基础。
引子
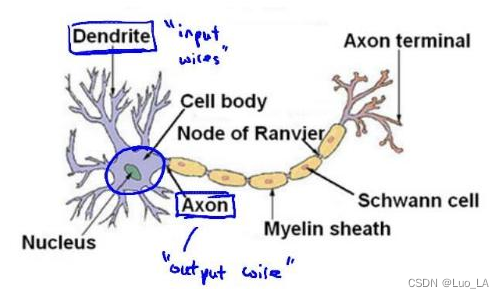
为了构建神经网络模型,我们需要首先思考大脑中的神经网络是怎样的?每一个神经元都可以被认为是一个处理单元/神经核,它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
模型表示
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入,并且根据本身的模型提供一个输出。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。
下图是一个以逻辑回归模型作为自身学习模型的神经元示例。
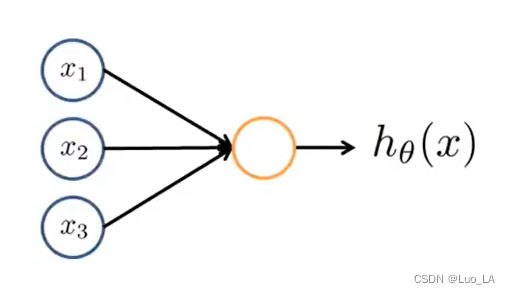
注意中间的箭头线,这些线称为“连接”。每个连接上有一个“权值”,在学习逻辑回归时,我们称之为参数,在神经网络中,参数又可被成为权重(weight)。连接是神经元中最重要的东西。每一个连接上都有一个权重。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
图中的 h θ ( x ) {h_\theta}\left( x \right) hθ(x)是 s i g m o i d sigmoid sigmoid函数,即 1 1 + e − θ T x \frac{1}{1+{ {e}^{-{\theta^{T}}x}}} 1+e−θTx1
通常在输入层我们只输入节点 x 1 x 2 x 3 x1 x2 x3 x1x2x3,有必要的时候会增加一个额外的节点 x 0 x0 x0, x 0 x0 x0 被称作偏置单元或偏置神经元。 x 0 x0 x0的值总是为1。
我们设计出了类似于神经元的神经网络,效果如下:
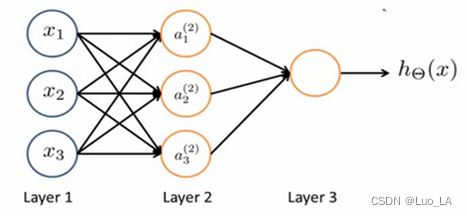
神经网络其实就是一组神经元连接在一起的集合。
其中 x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3是输入单元(input units),我们将原始数据输入给它们。
a 1 a_1 a1, a 2 a_2 a2, a 3 a_3 a3是中间单元,它们负责将数据进行处理,然后呈递到下一层。
最后是输出单元,它负责计算 h θ ( x ) {h_\theta}\left( x \right) hθ(x)。
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单元:

下面引入一些标记法来帮助描述模型:
a i ( j ) a_{i}^{\left( j \right)} ai(j) 代表第 j j j 层的第 i i i 个激活单元。 θ ( j ) {
{\theta }^{\left( j \right)}} θ(j)代表从第 j j j 层映射到第 j + 1 j+1 j+1 层时的权重的矩阵,例如 θ ( 1 ) {
{\theta }^{\left( 1 \right)}} θ(1)代表从第一层映射到第二层的权重的矩阵。其尺寸为:以第 j + 1 j+1 j+1层的激活单元数量为行数,以第 j j j 层的激活单元数加一为列数的矩阵。例如:上图所示的神经网络中 θ ( 1 ) {
{\theta }^{\left( 1 \right)}} θ(1)的尺寸为 3*4。
对于上图所示的模型,激活单元和输出分别表达为:
a 1 ( 2 ) = g ( Θ 10 ( 1 ) x 0 + Θ 11 ( 1 ) x 1 + Θ 12 ( 1 ) x 2 + Θ 13 ( 1 ) x 3 ) a_{1}^{(2)}=g(\Theta _{10}^{(1)}{
{x}_{0}}+\Theta _{11}^{(1)}{
{x}_{1}}+\Theta _{12}^{(1)}{
{x}_{2}}+\Theta _{13}^{(1)}{
{x}_{3}}) a1(2)=g(Θ10(1)x0+Θ11(1)x1+Θ12(1)x2+Θ13(1)x3)
a 2 ( 2 ) = g ( Θ 20 ( 1 ) x 0 + Θ 21 ( 1 ) x 1 + Θ 22 ( 1 ) x 2 + Θ 23 ( 1 ) x 3 ) a_{2}^{(2)}=g(\Theta _{20}^{(1)}{
{x}_{0}}+\Theta _{21}^{(1)}{
{x}_{1}}+\Theta _{22}^{(1)}{
{x}_{2}}+\Theta _{23}^{(1)}{
{x}_{3}}) a2(2)=g(Θ20(1)x0+Θ21(1)x1+Θ22(1)x2+Θ23(1)x3)
a 3 ( 2 ) = g ( Θ 30 ( 1 ) x 0 + Θ 31 ( 1 ) x 1 + Θ 32 ( 1 ) x 2 + Θ 33 ( 1 ) x 3 ) a_{3}^{(2)}=g(\Theta _{30}^{(1)}{
{x}_{0}}+\Theta _{31}^{(1)}{
{x}_{1}}+\Theta _{32}^{(1)}{
{x}_{2}}+\Theta _{33}^{(1)}{
{x}_{3}}) a3(2)=g(Θ30(1)x0+Θ31(1)x1+Θ32(1)x2+Θ33(1)x3)
h Θ ( x ) = a 1 ( 3 ) = g ( Θ 10 ( 2 ) a 0 ( 2 ) + Θ 11 ( 2 ) a 1 ( 2 ) + Θ 12 ( 2 ) a 2 ( 2 ) + Θ 13 ( 2 ) a 3 ( 2 ) ) { {h}_{\Theta }}(x)=a_{1}^{(3)}=g(\Theta _{10}^{(2)}a_{0}^{(2)}+\Theta _{11}^{(2)}a_{1}^{(2)}+\Theta _{12}^{(2)}a_{2}^{(2)}+\Theta _{13}^{(2)}a_{3}^{(2)}) hΘ(x)=a1(3)=g(Θ10(2)a0(2)+Θ11(2)a1(2)+Θ12(2)a2(2)+Θ13(2)a3(2))
向量化计算
相对于使用循环来编码,利用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值:
这里,我们令
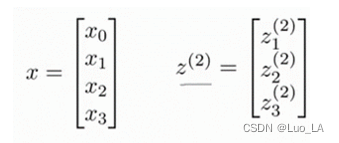
令 z 1 ( 2 ) = Θ 10 ( 1 ) x 0 + Θ 11 ( 1 ) x 1 + Θ 12 ( 1 ) x 2 + Θ 13 ( 1 ) x 3 z_{1}^{(2)}=\Theta _{10}^{(1)}{
{x}_{0}}+\Theta _{11}^{(1)}{
{x}_{1}}+\Theta _{12}^{(1)}{
{x}_{2}}+\Theta _{13}^{(1)}{
{x}_{3}} z1(2)=Θ10(1)x0+Θ11(1)x1+Θ12(1)x2+Θ13(1)x3
以此类推,即 z ( 2 ) = Θ ( 2 ) x z^{(2)}=\Theta ^{(2)}x z(2)=Θ(2)x
然后就有 a ( 2 ) = g ( z ( 2 ) ) a^{(2)}=g(z^{(2)}) a(2)=g(z(2)) 计算输出的值为:
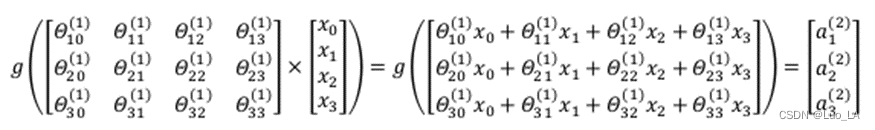
计算后添加 a 0 ( 2 ) = 1 a_{0}^{\left( 2 \right)}=1 a0(2)=1
令 z ( 3 ) = Θ ( 2 ) a ( 2 ) {
{z}^{\left( 3 \right)}}={
{\Theta }^{\left( 2 \right)}}{
{a}^{\left( 2 \right)}} z(3)=Θ(2)a(2),则 h θ ( x ) = a ( 3 ) = g ( z ( 3 ) ) h_\theta(x)={
{a}^{\left( 3 \right)}}=g({
{z}^{\left( 3 \right)}}) hθ(x)=a(3)=g(z(3))。
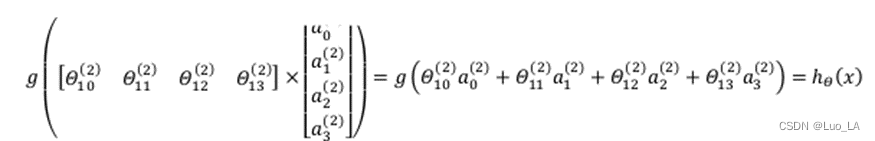
上面计算 h θ ( x ) h_\theta(x) hθ(x)的过程也成为前向传播。
为了更好了了解Neuron Networks的工作原理,我们先把左半部分遮住:
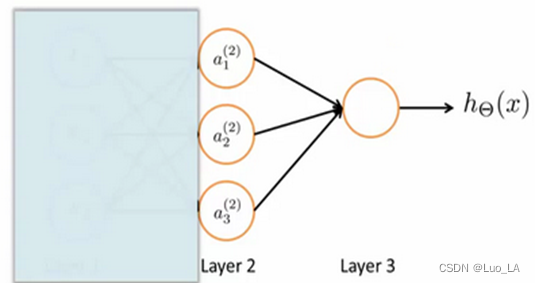
右半部分其实就是以 a 0 , a 1 , a 2 , a 3 a_0, a_1, a_2, a_3 a0,a1,a2,a3,按照逻辑回归的方式输出 h θ ( x ) h_\theta(x) hθ(x)
其实神经网络就像是逻辑回归,只不过我们把逻辑回归中的输入向量 [ x 1 ∼ x 3 ] \left[ x_1\sim {x_3} \right] [x1∼x3] 变成了中间层的 [ a 1 ( 2 ) ∼ a 3 ( 2 ) ] \left[ a_1^{(2)}\sim a_3^{(2)} \right] [a1(2)∼a3(2)], 即: h θ ( x ) = g ( Θ 0 ( 2 ) a 0 ( 2 ) + Θ 1 ( 2 ) a 1 ( 2 ) + Θ 2 ( 2 ) a 2 ( 2 ) + Θ 3 ( 2 ) a 3 ( 2 ) ) h_\theta(x)=g\left( \Theta_0^{\left( 2 \right)}a_0^{\left( 2 \right)}+\Theta_1^{\left( 2 \right)}a_1^{\left( 2 \right)}+\Theta_{2}^{\left( 2 \right)}a_{2}^{\left( 2 \right)}+\Theta_{3}^{\left( 2 \right)}a_{3}^{\left( 2 \right)} \right) hθ(x)=g(Θ0(2)a0(2)+Θ1(2)a1(2)+Θ2(2)a2(2)+Θ3(2)a3(2))
我们可以把 a 0 , a 1 , a 2 , a 3 a_0, a_1, a_2, a_3 a0,a1,a2,a3看成更为高级的特征值,也就是 x 0 , x 1 , x 2 , x 3 x_0, x_1, x_2, x_3 x0,x1,x2,x3的进化体,并且它们是由 x x x与 θ \theta θ决定的,因为是梯度下降的,所以 a a a是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x x x次方厉害,也能更好的预测新数据。这就是神经网络相比于逻辑回归和线性回归的优势。
从本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征 x 1 , x 2 , . . . , x n x_1,x_2,...,{ {x}_{n}} x1,x2,...,xn,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
举个例子
下面通过一个例子来向大家展示神经网络是怎样计算复杂的非线性假设模型的。
先从简单的开始。神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)、逻辑非(NOT)。
1. 逻辑与(AND)
下图中左半部分是神经网络的设计与output层表达式,右边是sigmod函数
我们可以用这样的一个神经网络表示AND 函数:
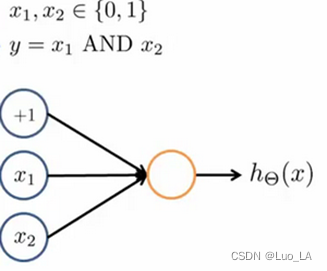
首先加一个偏置单元,也称为+1单元
对权重进行赋值: θ 0 = − 30 , θ 1 = 20 , θ 2 = 20 \theta_0 = -30, \theta_1 = 20, \theta_2 = 20 θ0=−30,θ1=20,θ2=20
我们的输出函数 h θ ( x ) h_\theta(x) hθ(x)即为: h Θ ( x ) = g ( − 30 + 20 x 1 + 20 x 2 ) h_\Theta(x)=g\left( -30+20x_1+20x_2 \right) hΘ(x)=g(−30+20x1+20x2)
g ( x ) g(x) g(x)的图像是:
下面是真值表:

所以我们有: h Θ ( x ) ≈ x 1 AND x 2 h_\Theta(x) \approx \text{x}_1 \text{AND} \, \text{x}_2 hΘ(x)≈x1ANDx2
这就是AND函数。
2. 逻辑或(OR)
下图的神经元(三个权重分别为-10,20,20)可以被视为作用等同于逻辑或(OR):

OR与AND整体一样,区别只在于的取值不同。
3. 逻辑非(NOT)
下图的神经元(两个权重分别为 10,-20)可以被视为作用等同于逻辑非(NOT):
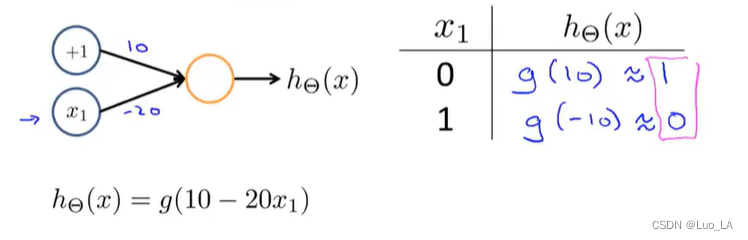
我们可以利用神经元来组合成更为复杂的神经网络以实现更复杂的运算。例如我们要实现XNOR 功能(输入的两个值必须一样,均为1或均为0),即 XNOR = ( x 1 AND x 2 ) OR ( ( NOT x 1 ) AND ( NOT x 2 ) ) \text{XNOR}=( \text{x}_1\, \text{AND}\, \text{x}_2 )\, \text{OR} \left( \left( \text{NOT}\, \text{x}_1 \right) \text{AND} \left( \text{NOT}\, \text{x}_2 \right) \right) XNOR=(x1ANDx2)OR((NOTx1)AND(NOTx2))
首先构造一个能表达 ( NOT x 1 ) AND ( NOT x 2 ) \left( \text{NOT}\, \text{x}_1 \right) \text{AND} \left( \text{NOT}\, \text{x}_2 \right) (NOTx1)AND(NOTx2)部分的神经元:

然后把下面着3块单独的部分组合到网络当中:

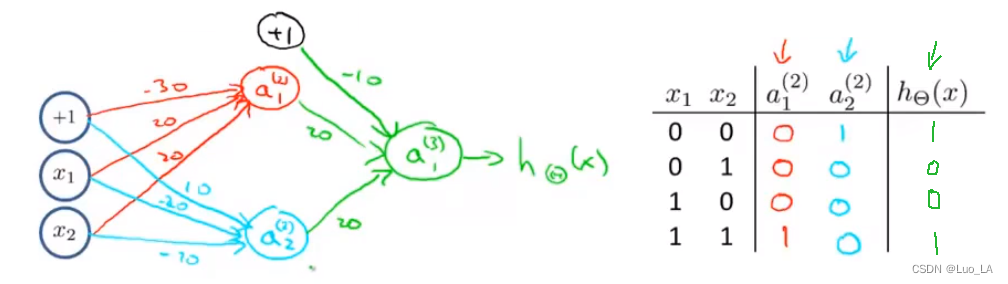
我们就得到了一个能实现 XNOR 运算符功能的神经网络。
按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。
这就是神经网络的厉害之处。
以上就是关于神经网络的基本知识。这篇文章是我学习吴恩达机器学习记录的一些笔记,有问题欢迎大家提出!