神经网络与正则化
正则化项能够控制模型的过拟合问题,深层神经网络模型如果不添加正则化项,很容易陷入过拟合。
1 L2 Regularization
1.1 正则化惩罚到底做了什么?
最常见的用于控制过拟合的方法为L2正则化,它所做的只是对损失函数增加了系数惩罚——在原公式基础上增加所有系数的二次方值的和。
原始损失函数:
L2正则化损失函数:
对神经网络模型添加L2正则化惩罚项后,它的前向传播函数没有发生任何变化;而在计算反向传播函数时,对于
1.2 正则化惩罚为什么会起作用?
L2惩罚所基于的假设:模型的系数们越小,则该模型越简单(为什么简单的模型会更好呢?根据奥卡姆剃刀原理,如果用简单的模型和复杂的模型都能同样地解释某一现象,我们更倾向于选择简单的模型来解释该现象。——括号里是我自己推想的)。
通过在损失函数里增加系数的二次方值,可以实现使所有的系数值都变小(当有某个系数的值较大时,整个损失函数会变得很大,因此该损失函数不能容忍有太大值的系数)。系数值较小的模型对外界的波动变得不那么敏感,推测这也导致了泛化能力增加。
我们对比一下,无正则化惩罚和有L2正则化惩罚的两个模型分别对同一批数据的训练结果:

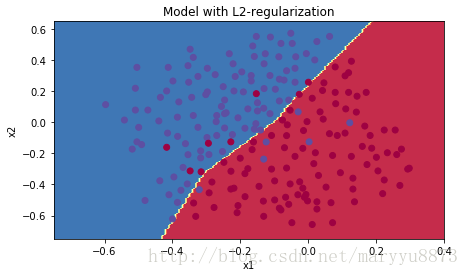
2 Dropout
Dropout是神经网络模型中另一个常用的用于控制过拟合的方法。它只是在模型训练过程中才会用到(做预测时不需要用到)。
2.1 Dropout使模型做了哪些变化?
Dropout会在模型训练的每次迭代过程中,随机去除某些节点(需要自定义概率值)。

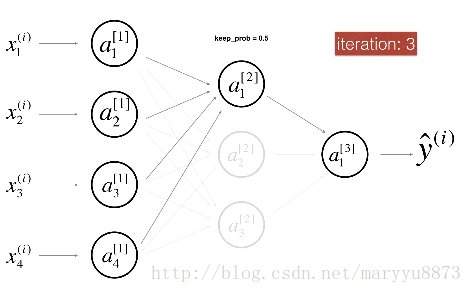
如上面两图所示,在第一次迭代时,将隐藏层的第二个节点去掉了;在第三次迭代时,只保留了隐藏层的第一个节点。
前向传播算法中增加Dropout
每个节点被丢弃的概率为
反向传播算法中的Dropout
由于在前向传播的计算过程中随机关闭了一些节点,在应用反向传播算法时也应该把这些节点当做不存在;由于在应用前向传播时,进行了激活值A除以
2.1 Dropout为何会有效?
在使用Dropout的迭代训练过程中,由于我们每次都是随机关闭某些节点,因此每次迭代过程中模型的实际结构都不相同。每次迭代,我们都只是用到原始结构的一个子集。这样训练所得的模型,不会对某几个特定的节点过于敏感(因为Dropout使每个节点都有一定的概率缺失),因此模型不容易陷入过拟合,从而泛化能力增强。
注意:Dropout只能应用在训练过程(前向传播和反向传播都需要),预测过程就不要应用Dropout了。
如下图所示,对于同一批数据使用Dropout方法后有效地缓解了过拟合现象:

注:如无特殊说明,以上所有图片均截选自吴恩达在Coursera开设的神经网络系列课程的讲义。