1.神经元模型
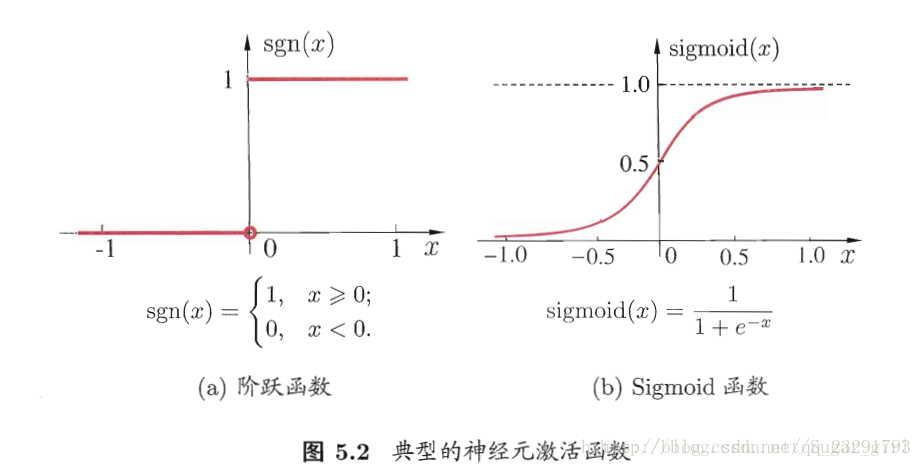
神经网络中最基本的成分是神经元模型,即“简单单元”。“M-P神经元模型”,神经元接收到来自nn个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。

2.感知机与多层网络
感知机(Perceptron)是由两层神经元组成的一个简单模型,但只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称为功能神经元(functional neuron);输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。这样一来,感知机与之前线性模型中的对数几率回归的思想基本是一样的,都是通过对属性加权与另一个常数求和,再使用sigmoid函数将这个输出值压缩到0-1之间,从而解决分类问题。不同的是感知机的输出层应该可以有多个神经元,从而可以实现多分类问题,同时两个模型所用的参数估计方法十分不同。
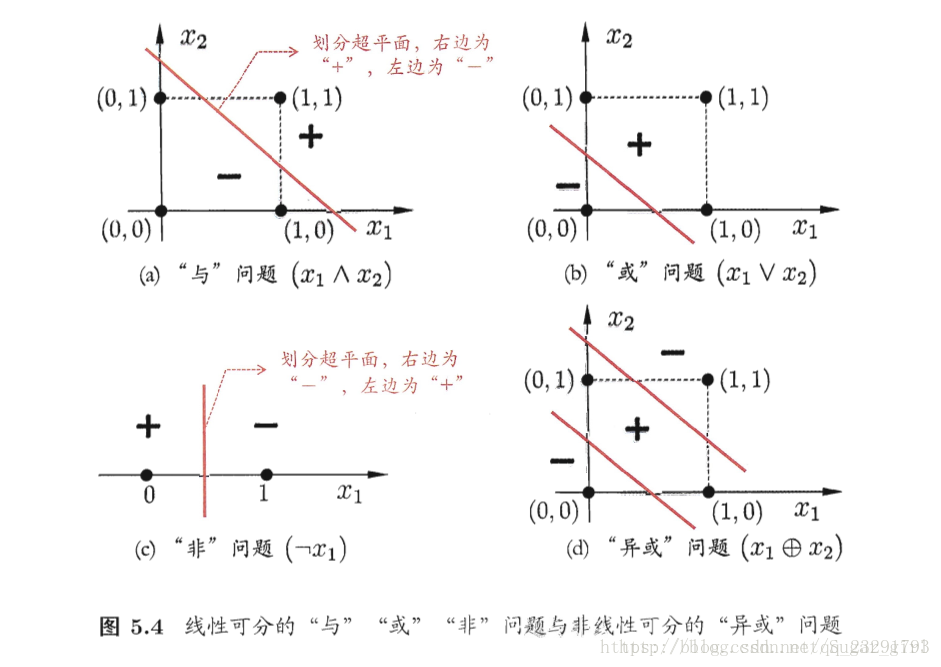
感知机只有输出层神经元进行激活函数处理,即只拥有一层功能神经元,其学习能力非常有限。事实上,上述与、或、非问题都是线性可分问题。可以证明,若两类模式是线性可分的,即存在一个线性超平面能将它们分开,则感知机的学习过程一定会收敛而求得适当的权向量;否则感知机学习过程会发生振荡,ω 难以稳定下来,不能求得合适解。
要解决非线性可分问题,需考虑使用多层功能神经元。输出层与输入层之间的一层神经元,被称为隐层或隐含层,隐含层和输出层神经元都是拥有激活函数的功能神经元。
常见的神经网络,每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。这样的神经网络结构通常称为“多层前馈神经网络”,其中输入层神经网络接收外界输入,隐层与输出层神经元对信号进行加工,最终结果由输出层神经元输出。神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值。
3.误差逆传播算法(反向传播算法)
多层网络的学习能力比单层感知机强的多,要训练多层网络,就需要更加强大的学习算法:BP算法,也就是反向传播算法。误差逆传播(BP)算法是训练多层网络学习算法最杰出的代表。BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络。
BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整。学习率η=(0,1)η=(0,1) 控制着算法每一轮迭代中的更新步长,若太大则容易震荡,太小则收敛速度又会过慢。
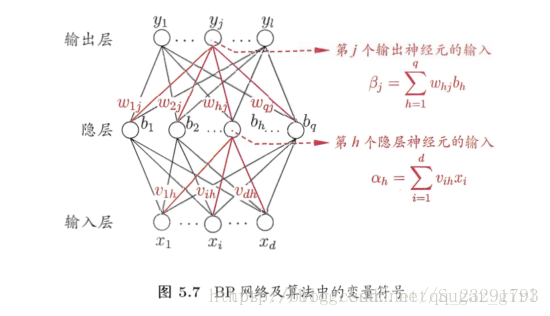
对于每个训练样例,BP算法执行以下操作:先将输入示例提供给输入层神经元,然后逐层将信号前传,知道产生输出层的结果;然后计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差来对连接权和阈值进行调整。该迭代过程循环进行,直到达到某些停止条件为止,例如训练误差已达到一个很小的值。

但上面介绍的“标准BP算法”每次仅针对一个训练样例更新连接权和阈值,也就是说,图5.8中算法的更新规则是基于单个的Ek 推导而成。如果类似地推导出基于累计误差最小化的更新规则,就得到了累积误差逆传播算法。一般来说,标准BP算法每次更新只针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小点,标准BP算法往往需进行更多次数的迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集D一遍后才对参数进行更新,其参数更新的频率低得多。但在很多任务中,累计误差下降到一定程度之后,进一步下降会非常缓慢,这时标准BP往往会更快获得更好的解,尤其是在训练集D非常大时更明显。
由于BP神经网络强大的表示能力,BP神经网络经常遭遇过拟合。针对过拟合,有两种策略:第一种策略是“早停”:将数据分为训练集和验证集,训练集用来计算梯度、更新连接权和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。第二种策略是“正则化”,其基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如连接权与阈值的平方和。
4.全局最优与局部最优
局部最小解是参数空间中的某个点,某领域点的误差函数值均不小于该点的函数值;全局最小值则是指参数空间中所有点的误差函数均不小于该点的误差函数值。
基于梯度的搜索是使用最为广泛的参数寻优方法。在此类方法中,我们从某些初始解出发,迭代寻找最优参数值。每次迭代中,我们先计算误差函数在当前点的梯度,然后根据梯度确定搜索方向。若误差函数在当前点的梯度为零,则已达到局部极小,更新量将为零,这意味着参数的迭代更新将在此停止。
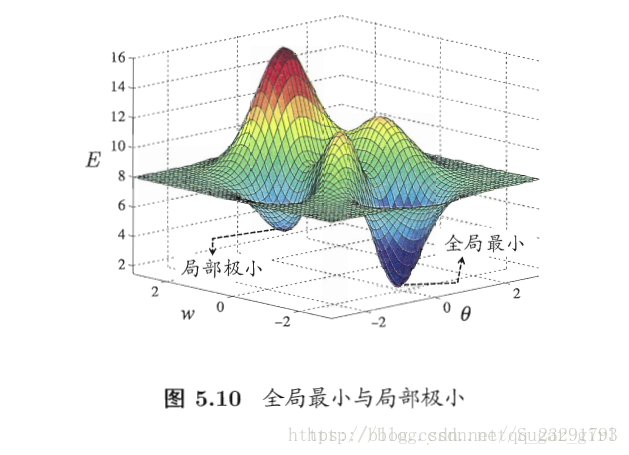
可采用以下策略来试图“跳出”局部极小,从而进一步接近全剧最小:
- 以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数。
- 使用“模拟退火”技术。模拟退火在每一步都以一定的概率接受比当前解更差的结果,从而有助于“跳出”局部极小。
- 使用随机梯度下降,在计算梯度时加入了随机因素。
此外,遗传算法也常用来训练神经网络以更好地逼近全局最小。