什么是神经网络
神经网络是一种模拟人脑工作原理,从而实现类人工智能的机器学习技术,支持处理图像、文本、语音以及序列多种类型的数据,可以实现分类、回归和预测等。
简单的神经元:逻辑单元(Logistic Unit)
由于神经网络建立在很多个神经元的基础上,其中每一个神经元都是一个学习模型,这些神经元叫做激活单元(Activation Unit)。以逻辑回归模型为例,采纳一些特征作为输入,给出逻辑输出,如下图:
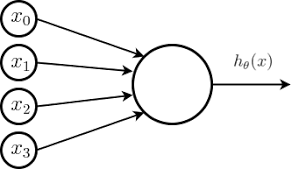 Logistic Unit
Logistic Unit
也可以用简单的式子来表示: .
图中空心的圆圈就是类似神经元的东西,类似神经元的树突,这个圆圈的输入神经为它传入信息,然后它对其进行计算,再通过它的输出神经(轴突)将得到的结果信息传出。
其中: (激励函数,activation function ),
(输入),
(权重,weights).
这就是最简单的一种模拟神经元的逻辑单元模型。我们在机器学习中的目标就是,得到最合适的权重组合,使得整个神经网络的预测效果达到最佳。
【总结】一个神经元的组成:
- 输入数据
- 线性加权
- 激励函数(非线性,易求导)
- 输出数据
神经网络的模型表示
神经网络就是多个神经元组合到一起的集合,如下图:
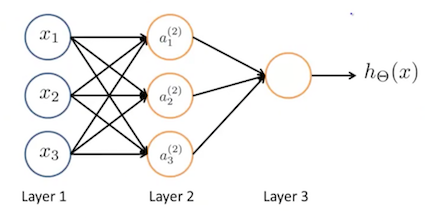 Neural Network
Neural Network
有时第一层也要加上额外的节点 ,第二层加一个偏执单元(bias unit)
。图中 Layer 1 叫做输入层(Input Layer),Layer 3 叫做输出层(Output Layer),Layer 2 叫做隐藏层(Hidden Layer)。输入层和输出层只有一个,而隐藏层可以有多个,实际上非输入层或非输出层的层都是隐藏层。
我们规定: 表示第 j 层的第 i 个神经元,
为一个权重矩阵,控制从第 j 层到第 j+1 层的映射。在上图的神经网络中,第二层的数据可以表示为:
其中的 g(x) 代表的是激励函数,也就是说这里的激励函数作用在输入数据经过权重处理后的线性组合上。参数矩阵 控制了三个输入单元到三个隐藏单元的映射,因此它是一个维度为 3x4 的矩阵。
则 .
一般来说,如果一个神经网络在第 j 层有 个单元,在第 j+1 层有
个单元,那么矩阵
控制着第 j 层到第 j+1 层的映射,它的维度为
. 其中第二项的 +1 来自
中的偏执节点
和
,也就是说输入层包括偏执节点,而输出层不包括。
接下来,再定义一些额外的项,我们把激励函数 g 括号里的部分记作 ,于是上面的表达式可以写作:
两组式子对比,我们可以看出来: ,
,其中:
. 这里
和
都是三维向量,因此激励函数 g 是逐个作用于
中的数据的。
若我们增加一项 ,那么
,
.
这个计算 h(x) 的过程也叫做前向传播(forward propagation)。
