通过上篇softmax回归已经知道大概了,但是有个缺点,现在来仔细看看
Softmax回归模型参数化的特点
Softmax 回归有一个不寻常的特点:它有一个“冗余”的参数集。为了便于阐述这一特点,假设我们从参数向量 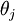 中减去了向量
中减去了向量 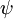 ,这时,每一个 都变成了
,这时,每一个 都变成了 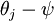 (
(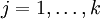 )。此时假设函数变成了以下的式子:
)。此时假设函数变成了以下的式子:
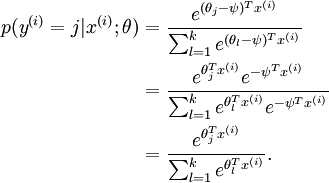
换句话说,从 中减去 完全不影响假设函数的预测结果!这表明前面的 softmax 回归模型中存在冗余的参数。更正式一点来说, Softmax 模型被过度参数化了。对于任意一个用于拟合数据的假设函数,可以求出多组参数值,这些参数得到的是完全相同的假设函数 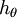 。
。
进一步而言,如果参数 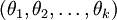 是代价函数
是代价函数  的极小值点,那么
的极小值点,那么 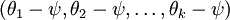 同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
同样也是它的极小值点,其中 可以为任意向量。因此使 最小化的解不是唯一的。(有趣的是,由于 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题。但是 Hessian 矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题)
注意,当 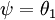 时,我们总是可以将
时,我们总是可以将 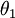 替换为
替换为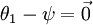 (即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的
(即替换为全零向量),并且这种变换不会影响假设函数。因此我们可以去掉参数向量 (或者其他 中的任意一个)而不影响假设函数的表达能力。实际上,与其优化全部的 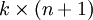 个参数 (其中
个参数 (其中 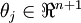 ),我们可以令
),我们可以令 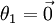 ,只优化剩余的
,只优化剩余的 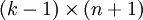 个参数,这样算法依然能够正常工作。
个参数,这样算法依然能够正常工作。
在实际应用中,为了使算法实现更简单清楚,往往保留所有参数 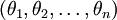 ,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
,而不任意地将某一参数设置为 0。但此时我们需要对代价函数做一个改动:加入权重衰减。权重衰减可以解决 softmax 回归的参数冗余所带来的数值问题。
权重衰减(也叫做惩罚项)
我们通过添加一个权重衰减项 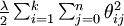 来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
来修改代价函数,这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }} \right] + \frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^n \theta_{ij}^2\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/7/1/471592d82c7f51526bb3876c6b0f868d.png)
有了这个权重衰减项以后 ( ),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了。 此时的 Hessian矩阵变为可逆矩阵,并且因为是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解。
为了使用优化算法,我们需要求得这个新函数 的导数,如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} ( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) ) \right] } + \lambda \theta_j\end{align}](http://ufldl.stanford.edu/wiki/images/math/3/a/f/3afb4b9181a3063ddc639099bc919197.png)
通过最小化 ,我们就能实现一个可用的 softmax 回归模型。
参考:http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92