在 softmax回归中,我们解决的是多分类问题(相对于 logistic 回归解决的二分类问题),类标  可以取
可以取  个不同的值(而不是 2 个)。因此,对于训练集
个不同的值(而不是 2 个)。因此,对于训练集 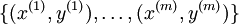 ,我们有
,我们有 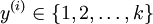 。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有
。(注意此处的类别下标从 1 开始,而不是 0)。例如,在 MNIST 数字识别任务中,我们有 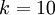 个不同的类别。
个不同的类别。
对于给定的测试输入  ,如果输入的图片分辨率是28x28.则数据x是一个784的向量。我们想用假设函数针对每一个类别j估算出概率值
,如果输入的图片分辨率是28x28.则数据x是一个784的向量。我们想用假设函数针对每一个类别j估算出概率值 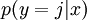 ,j表示第j类。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数
,j表示第j类。也就是说,我们想估计 的每一种分类结果出现的概率。因此,我们的假设函数将要输出一个 维的向量(向量元素的和为1)来表示这 个估计的概率值。 具体地说,我们的假设函数 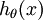 形式如下:
形式如下:
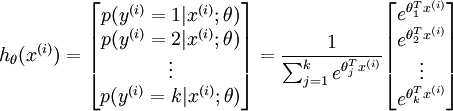
其中 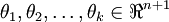 是模型的参数。请注意
是模型的参数。请注意 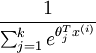 这一项对概率分布进行归一化,使得所有概率之和为 1 。
这一项对概率分布进行归一化,使得所有概率之和为 1 。
为了方便起见,我们同样使用符号  来表示全部的模型参数。在实现Softmax回归时,将 用一个
来表示全部的模型参数。在实现Softmax回归时,将 用一个 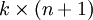 的矩阵来表示会很方便,该矩阵是将
的矩阵来表示会很方便,该矩阵是将 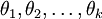 都是784维的列向量。按行罗列起来得到的,如下所示:
都是784维的列向量。按行罗列起来得到的,如下所示:
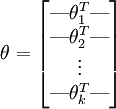
代价函数
现在我们来介绍 softmax 回归算法的代价函数。在下面的公式中, 是示性函数,其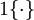 取值规则为:
取值规则为:
值为真的表达式
, 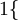 值为假的表达式
值为假的表达式 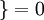 。举例来说,表达式
。举例来说,表达式 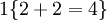 的值为1 ,
的值为1 ,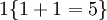 的值为 0。我们的代价函数为:
的值为 0。我们的代价函数为:
![\begin{align}J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }}\right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/7/6/3/7634eb3b08dc003aa4591a95824d4fbd.png)
外层求和是表示共有m个样本数据,内层求和表示j从1到k表示共有k类,对于minist数据集来说k=10,这里j是从1开始。
![\begin{align}J(\theta) &= -\frac{1}{m} \left[ \sum_{i=1}^m (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) + y^{(i)} \log h_\theta(x^{(i)}) \right] \\&= - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=0}^{1} 1\left\{y^{(i)} = j\right\} \log p(y^{(i)} = j | x^{(i)} ; \theta) \right]\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/4/9/5491271f19161f8ea6a6b2a82c83fc3a.png)
可以看到,Softmax代价函数与logistic 代价函数在形式上非常类似,只是在Softmax损失函数中对类标记的 个可能值进行了累加。注意在Softmax回归中将 分类为类别  的概率为:
的概率为:
-
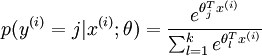 .
.
现在来讲讲softmax回归的代价函数的求导过程:

上面求的对theta j求导实际上是个784维的向量,向量中每一个数字代表着图片中每个像素的权重。
对于  的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
的最小化问题,目前还没有闭式解法。因此,我们使用迭代的优化算法(例如梯度下降法,或 L-BFGS)。经过求导,我们得到梯度公式如下:
![\begin{align}\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} \left( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) \right) \right] }\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/9/e/59ef406cef112eb75e54808b560587c9.png)
让我们来回顾一下符号 "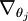 " 的含义。
" 的含义。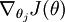 本身是一个向量,它的第
本身是一个向量,它的第  个元素
个元素 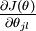 是 对
是 对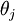 的第 个分量的偏导数。此时的l 表示的图片中第l个像素。
的第 个分量的偏导数。此时的l 表示的图片中第l个像素。
有了上面的偏导数公式以后,我们就可以将它代入到梯度下降法等算法中,来最小化 。 例如,在梯度下降法的标准实现中,每一次迭代需要进行如下更新:  (
( )。
)。
当实现 softmax 回归算法时, 我们通常会使用上述代价函数的一个改进版本。具体来说,就是和权重衰减(weight decay)一起使用。这个具体的后面再介绍。
参考:http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
https://blog.csdn.net/cheese_pop/article/details/51264567