DBSCAN密度聚类算法简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
DBSCAN一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。

算法流程

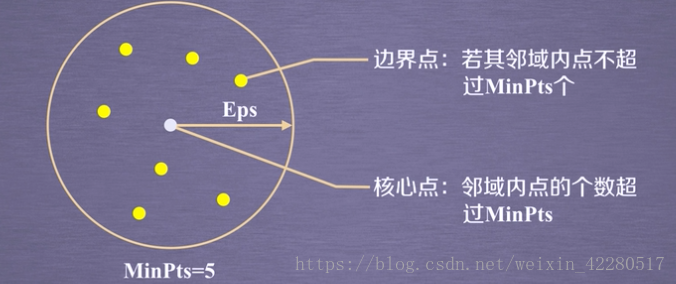
主要参数

与K-means聚类的比较

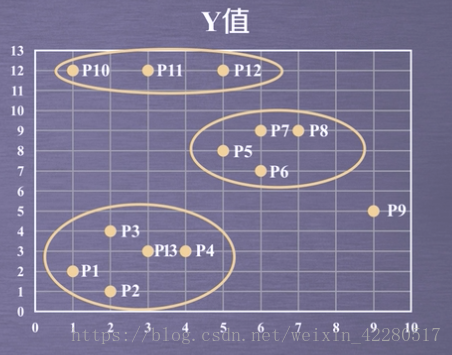
举个栗子
有13个点如图所示,用DBSCAN进行聚类。
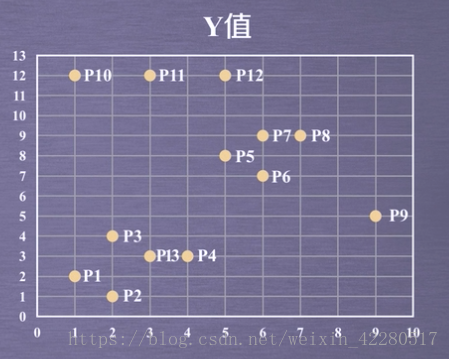
1. 取领域Eps=3, MinPts=3。依据DBSCAN对所有点进行聚类(曼哈顿距离)。
2. 对每个点计算其领域Eps=3内所有点的集合。集合内点的个数超过MinPts=3的点记为核心点。
扫描二维码关注公众号,回复:
2716690 查看本文章

3. 查看剩余点是否在核心点的领域内。是,记为边界点,否则为噪声点。
4. 将距离不超过Eps=3的点相互连接,构成一个簇。核心点邻域内的点也会加入到这个簇中。