一、基本概念
可以用1,2,3,4来总结DBSCAN的基本概念。
1个核心思想:基于密度
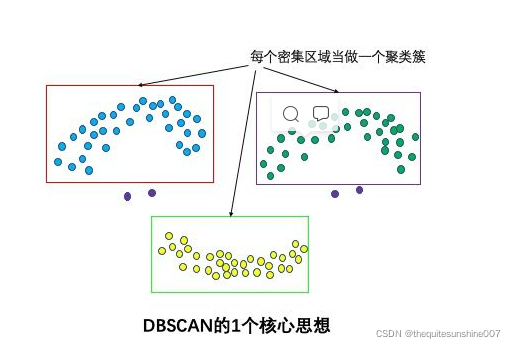
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
2个算法参数:邻域半径R和最少点数目minpoints
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。

3种点的类别:核心点,边界点和噪声点

邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。

4种关系:密度直达,密度可达,密度相连,非密度相连
如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
二、算法描述
DBSCAN 算法对簇的定义很简单,由密度可达关系导出的最大密度相连的样本集合,即为最终聚类的一个簇。
DBSCAN 算法的簇里面可以有一个或者多个核心点。如果只有一个核心点,则簇里其他的非核心点样本都在这个核心点的 Eps 邻域里。如果有多个核心点,则簇里的任意一个核心点的 Eps 邻域中一定有一个其他的核心点,否则这两个核心点无法密度可达。这些核心点的 Eps 邻域里所有的样本的集合组成一个 DBSCAN 聚类簇。
DBSCAN算法的描述如下。
输入:数据集,邻域半径 Eps,邻域中数据对象数目阈值 MinPts;
输出:密度联通簇。
处理流程如下。
1)从数据集中任意选取一个数据对象点 p;
2)如果对于参数 Eps 和 MinPts,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复(2)、(3)步,直到所有点被处理。
DBSCAN 算法的计算复杂的度为 O(n²),n 为数据对象的数目。这种算法对于输入参数 Eps 和 MinPts 是敏感的。
代码实现逻辑如下:
1)计算每个point的eps范围内的point数量pts;
2)对于所有pts >Minpts的point,记为Core point;
3)对于所有的corepoint,将其eps范围内的core point下标添加到vector集合(vector<int> neighborCoreIdx)中;
4)遍历所有的corepoint,采用深度优先的方式遍历它的neighborCoreIdx集合,使得相互连接的core point具有相同的cluster编号;
5)对所有pts < Minpts且在Core point 范围内的点,记为Borderpoint;
若某个Borderpoint点在某个Core point的eps范围内,则让该Borderpoint点的cluster编号等于这个Core point的cluster编号;
6)剩余的point的为Noise point;
程序结束。
三、代码实现
看了几个其他博客的代码,但是感觉很乱,有的运行出错,或者是展示效果差。本人自己整理了一份可以使用和展示的代码,运行无误! 加了很多帮助理解的注释,浅显易懂!
/*
DBSCAN Algorithm
@author:TheQuiteSunshine
*/
#include <iostream>
#include <sstream>
#include <fstream>
#include <vector>
#include <ctime>
#include <cstdlib>
#include <limits>
#include <cmath>
#include <map>
using namespace std;
//为了便于可视化展示算法效果,引入OpenCV库。
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
using namespace cv;
/*
* @样本点类型
*-- 邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。
*-- 不属于核心点但在某个核心点的邻域内的点叫做边界点。
*-- 既不是核心点也不是边界点的是噪声点。
*/
enum ESampleType
{
NOISE = 1,
BORDER = 2,
CORE = 3,
};
struct point
{
public:
float x;
float y;
int cluster = 0; //所属类别(一个标识代号,属于同一类的样本具有相同的cluster)
//邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。
//不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点
int pointType = NOISE; // 1:noise 2:border 3:core (初始默认为噪声点)
int pts = 0; //points in MinPts (指定领域内样本点的个数)
vector<int> neighborCoreIdx; //对所有的corepoint,将其eps范围内的core point下标添加到vector<int> neighborCoreIdx中
int visited = 0; //是否被遍历访问过
point()
{
}
point(float a, float b)
{
x = a;
y = b;
//cluster = c;
}
};
float stringToFloat(string i)
{
stringstream sf;
float score = 0;
sf << i;
sf >> score;
return score;
}
//读取文本文件,从中解析出数据。
vector<point> openFile(const char *dataset)
{
fstream file;
file.open(dataset, ios::in);
if (!file)
{
cout << "Open File Failed!" << endl;
vector<point> a;
return a;
}
vector<point> data;
int i = 1;
while (!file.eof())
{
string temp;
file >> temp;
int split = temp.find(',', 0);
point p(stringToFloat(temp.substr(0, split)), stringToFloat(temp.substr(split + 1, temp.length() - 1)));
data.push_back(p);
}
file.close();
cout << "successful!" << endl;
return data;
}
//计算平面内两点之间的距离
float squareDistance(point a, point b)
{
return sqrt((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y));
}
/** @brief DBSCAN聚类算法
@param dataset:输入样本数据 [in][out]参数
@param Eps:领域半径
@param MinPts:聚类中心的下标
@return :返回每个样本的类别,类别从1开始,0表示未分类或者分类失败
*/
void DBSCAN(vector<point> &dataset, float Eps, int MinPts)
{
int count = 0;
int len = dataset.size();
//calculate pts
cout << "计算各点的邻域数量" << endl;
for (int i = 0; i < len; i++)
{
//特别注意 !!! 这里如果j从i开始,表明某点的邻域范围内样本数量包含自己,若j从i+1开始则不包含自己。
for (int j = i; j < len; j++)
{
if (squareDistance(dataset[i], dataset[j]) < Eps)
{
dataset[i].pts++;
dataset[j].pts++;
}
}
}
//core point ,若某个点在其领域Eps范围内的点个数>=MinPts,称该点为core point核心点
cout << "寻找核心点" << endl;
//核心点集合索引(索引为样本点原本的索引,从0开始)
vector<int> corePtInxVec;
for (int i = 0; i < len; i++)
{
if (dataset[i].pts >= MinPts)
{
dataset[i].pointType = CORE;
dataset[i].cluster = (++count);
corePtInxVec.push_back(i);
printf("样本(%.1f, %.1f)的邻域点数量为:%d,被确立为核心点, cluster:%d\n", dataset[i].x, dataset[i].y, dataset[i].pts, dataset[i].cluster);
}
}
//合并core point
cout << "合并核心点" << endl;
for (int i = 0; i < corePtInxVec.size(); i++)
{
for (int j = i + 1; j < corePtInxVec.size(); j++)
{
//对所有的corepoint,将其eps范围内的core point下标添加到vector<int> corepts中
if (squareDistance(dataset[corePtInxVec[i]], dataset[corePtInxVec[j]]) < Eps)
{
dataset[corePtInxVec[i]].neighborCoreIdx.push_back(corePtInxVec[j]);
dataset[corePtInxVec[j]].neighborCoreIdx.push_back(corePtInxVec[i]);
printf("核心点%.1f, %.1f)与核心点%.1f, %.1f)处在半径范围内,相互连接,可以合并\n",
dataset[corePtInxVec[i]].x, dataset[corePtInxVec[i]].y, dataset[corePtInxVec[j]].x, dataset[corePtInxVec[j]].y);
}
}
}
//对于所有的corepoint,采用深度优先的方式遍历每个core point的所有corepts,使得相互连接的core point具有相同的cluster编号
for (int i = 0; i < corePtInxVec.size(); i++)
{
for (int j = 0; j < dataset[corePtInxVec[i]].neighborCoreIdx.size(); j++)
{
int idx = dataset[corePtInxVec[i]].neighborCoreIdx[j];
dataset[idx].cluster = dataset[corePtInxVec[i]].cluster;
}
}
//不属于核心点但在某个核心点的邻域内的点叫做边界点
cout << "边界点,把边界点加入到靠近的核心点" << endl;
//border point,joint border point to core point
for (int i = 0; i < len; i++)
{
if (dataset[i].pointType == CORE) //忽略核心点
continue;
for (int j = 0; j < corePtInxVec.size(); j++)
{
int idx = corePtInxVec[j]; //核心点索引
if (squareDistance(dataset[i], dataset[idx]) < Eps)
{
dataset[i].pointType = BORDER;
dataset[i].cluster = dataset[idx].cluster;
printf("样本(%.1f, %.1f)被确立为边界点, cluster:%d\n", dataset[i].x, dataset[i].y, dataset[i].cluster);
break;
}
}
}
cout << "输出结果:" << endl;
for (int i = 0; i < len; i++)
{
if (dataset[i].pointType == CORE)
{
printf("CORE: x:%.2f, y:%.2f cluster:%d\n", dataset[i].x, dataset[i].y, dataset[i].cluster);
}
else if (dataset[i].pointType == BORDER)
{
printf("BORDER: x:%.2f, y:%.2f cluster:%d\n", dataset[i].x, dataset[i].y, dataset[i].cluster);
}
else
{
printf("NOISE: x:%.2f, y:%.2f cluster:%d\n", dataset[i].x, dataset[i].y, dataset[i].cluster);
}
}
// for(int i=0;i < corePoint.size(); i++)
// {
// clustering<<corePoint[i].x<<","<<corePoint[i].y<<","<<corePoint[i].cluster<<"\n";
// }
}
/*
*@生成随机颜色
*/
cv::Scalar random_color()
{
static cv::RNG _rng(10086);
unsigned icolor = (unsigned)_rng;
return cv::Scalar(icolor & 0xFF, (icolor >> 8) & 0xFF, (icolor >> 16) & 0xFF);
}
int main(int argc, char **argv)
{
//加载数据
vector<point> dataset = openFile("dataset.txt");
float radius = 2.0; //邻域半径R
int MinPts = 2; //邻域半径R内样本点的数量大于等于minpoints的点叫做核心点
//DBSCAN算法进行聚类
DBSCAN(dataset, radius, MinPts);
//设置了6种不同的颜色
const int colorCnts = 6;
cv::Scalar colors[] = {cv::Scalar(255, 100, 80), cv::Scalar(0, 255, 0), cv::Scalar(0, 0, 255),
cv::Scalar(0, 255, 255), cv::Scalar(255, 0, 255), cv::Scalar(255, 255, 0)};
//画出原始数据分布图
cv::Point offset(10, 10); //所有样本均加上这个偏移、防止离原点太近影响视觉显示效果
cv::Mat originalMat = cv::Mat::zeros(cv::Size(300, 300), CV_8UC3);
for (size_t i = 0; i < dataset.size(); i++)
{
cv::Point pt = offset + cv::Point(dataset[i].x * 10, dataset[i].y * 10);
cv::circle(originalMat, pt, 2, cv::Scalar(0, 0, 255), 2);
}
cv::imshow("original data", originalMat);
//画出结果示意图,不同的cluster样本点用不同的颜色表示。
map<int, cv::Scalar> clusterMap;
map<int, cv::Scalar>::iterator it;
cv::Mat resultMat = cv::Mat::zeros(cv::Size(300, 300), CV_8UC3);
cv::Scalar color;
for (size_t i = 0; i < dataset.size(); i++)
{
it = clusterMap.find(dataset[i].cluster);
if (it == clusterMap.end()) //首次出现,为该cluster随机分配一组颜色。
{
color = random_color();
clusterMap.insert(std::make_pair(dataset[i].cluster, color));
}
else
color = it->second;
cv::Point pt = offset + cv::Point(dataset[i].x * 10, dataset[i].y * 10);
cv::circle(resultMat, pt, 2, color, 2);
}
cv::imshow("cluster data", resultMat);
cv::waitKey(0);
getchar();
return 0;
}
附程序所使用的dataset.txt文件:
0,0
3,8
2,2
1,1
5,3
4,8
6,3
5,4
6,4
7,5
12,4
12,5
12,6
13,4
17,8
18,9
四、代码运行效果

五、参考资料
鸣谢: