一、深度学习与深层神经网络
维基百科对深度学习的定义:一类通过多层非线性变换对高复杂性数据建模算法的合集。又由于深层神经网络是实现“多层非线性变换”最常用的一种方法,所以在实际中基本上可以认为深度学习就是深层神经网络的代名词。深度学习有两个非常重要的特性-----多层和非线性。
1、线性模型的局限性
在线性模型中,模型的输出为输入的加权和。线性模型的最大特点就是任意线性模型的组合仍然还是线性模型。而现实世界中,绝大部分的问题都是无法线性分割的,所以这是线性模型的局限性。
2、激活函数实现去线性化
之前介绍的神经元结构的输出为所有输入的加权和,这导致整个神经网络是一个线性模型。如果将每个神经元(也就是神经网络中的节点)的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的了。这个非线性函数就是激活函数。
下图为加入了激活函数和偏置项后的神经元结构: 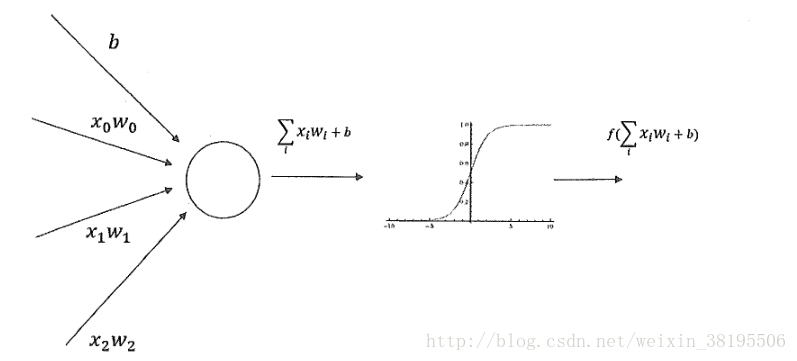
神经网络结构加上激活函数和偏置项后的前向传播算法的数学定义为:
相比于传统的神经网络主要有两个改变:
第一是增加了偏置项(bias),偏置项是神经网络中非常常用的一种结构。
第二是每个节点的取值不再是单纯的加权和。每个节点的输出在加权和的基础上还做了一个非线性变换。
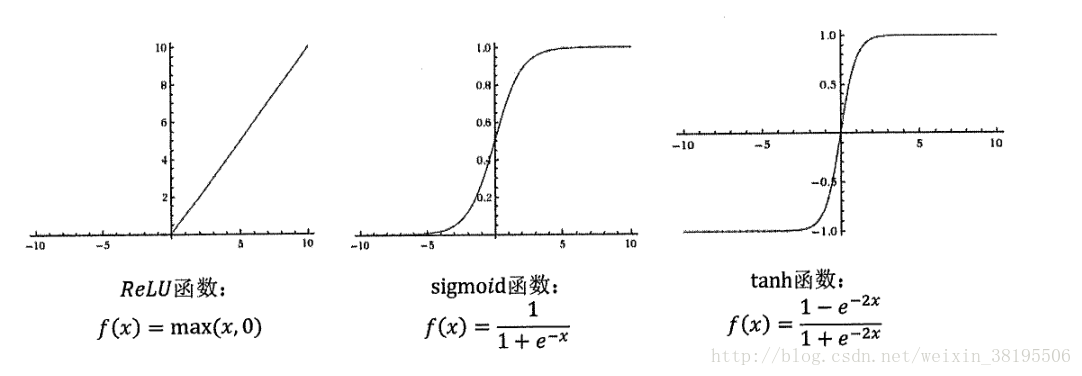
以下是几种常用的非线性激活函数的函数图像:
ReLu函数基本代替了sigmoid函数了,因为sigmoid函数很容易引起梯度消失,导致过拟合。
这些激活函数图像都不是一条直线,所以通过这些激活函数,每一个节点不再是线性变换,于是整个神经网络就不再是线性的了。
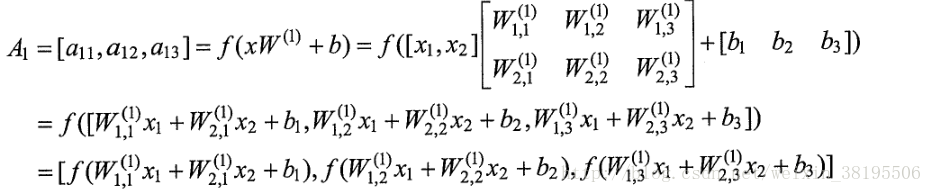
下图是加入了偏置项和ReLu激活函数之后的神经网络结构: 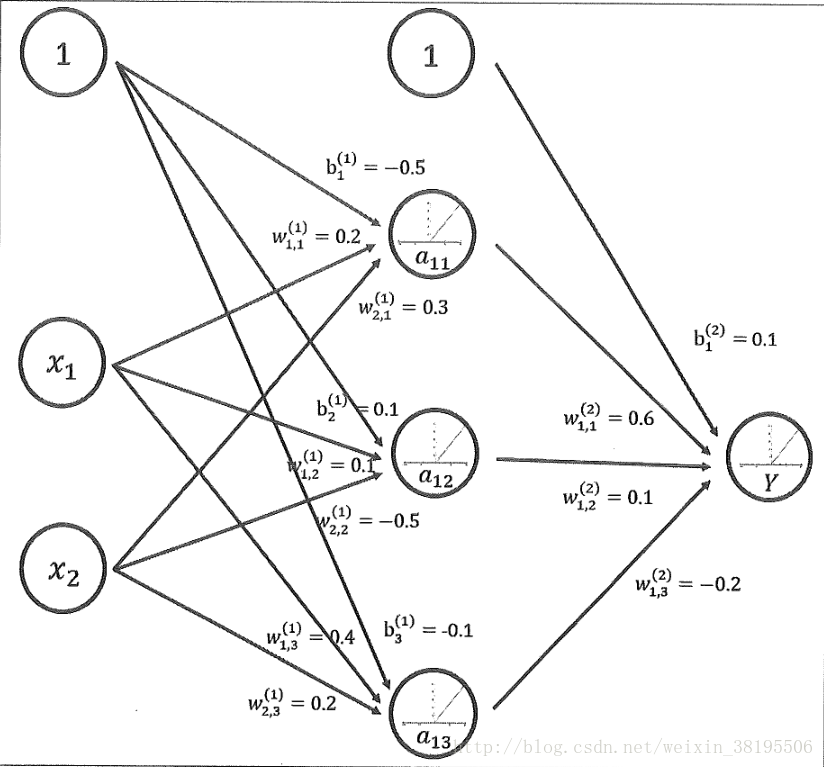
偏置项被设置为一个输出永远为1的节点(通常设置为1或者0,一般为常数项)。
新的神经网络模型前向传播算法的计算方法为:
隐藏层:
输出层:
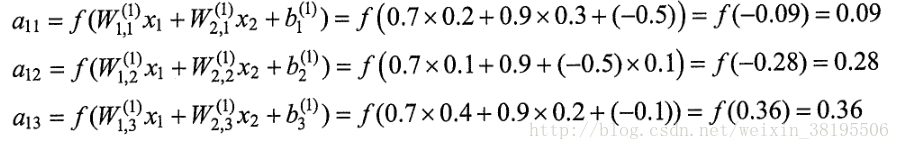
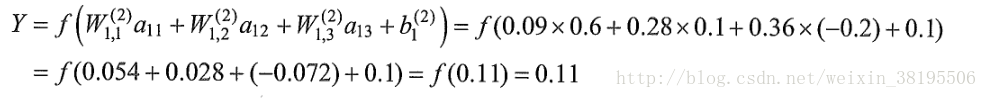
目前Tensorflow提供了七种不同的非线性激活函数,tf.nnrelu、tf.sigmoid、tf.tanh是比较常用的几个。当然,Tensorflow也支持使用自己定义的激活函数。
以下代码展示了如何通过TensorFlow实现上图中神经网络的前向传播算法
a = tf.nn.relu(tf.matmul(x,w1)+biases1)
y = tf.nn.relu(tf.matmul(a,w2)+biases2)
从上面代码可以看出,TF可以很好地支持使用了激活函数和偏置项的神经网络。
3、多层网络解决异或运算
感知机可以简单地理解为单层的神经网络,前文提到的加入了偏置项和激活函数的神经元结构就是感知机的网络结构。感知机会先将输入进行加权和,然后通过激活函数最后得到输出,这个结构就是一个没有隐藏层的神经网络,但是感知机是无法模拟异或运算的。要想解决异或问题,必须加入隐藏层,所以说,深度神经网络实际上有组合特征提取的功能,这个特征对于解决不易提取特征向量的问题(比如图片识别、语音识别等)有很大帮助。这也是深度学习在这些问题上更加容易取得突破性进展的原因。
二、损失函数定义
神经网络模型的效果以及优化的目标是通过损失函数(loss function)来定义的。
1、经典损失函数
交叉熵(cross entropy)
交叉熵刻画了两个概率分布之间的距离,它是分类问题中使用比较广的一种损失函数。给定两个概率分布p和q,通过q来表示p的交叉熵为:
如何将神经网络前向传播得到的结果也变成概率分布呢?Softmax回归就是一个非常常用的方法。
Softmax回归本身可以作为一个学习算法来优化分类结果,但在Tensorflow中,Softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络的输出变成一个概率分布。假设原始的神经网络的输出为y1,y2,...,yny1,y2,...,yn,那么经过Softmax回归处理之后的输出为:
Tensorflow实现交叉熵
cross_entropy = -tf.reduce_mean(
y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))
)- 1
- 2
- 3
其中y_代表正确结果,y代表预测结果,tf.clip_by_value函数可以将一个张量中的数值限制在一个范围之内,tf.log完成对张量中所有元素依次求对数,* 实现两个矩阵元素之间直接相乘(矩阵乘法需要使用tf.matmul函数来完成)。
因为交叉熵一般会与Softmax回归一起使用,所以Tensorflow对这两个功能进行了统一封装,并提供了tf.nn.softmax_cross_entropy_with_logits函数。比如可以直接通过下面的代码来实现使用了softmax回归之后的交叉熵损失函数:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)- 1
均方误差(MSE)
对于回归问题,最常用的损失函数是均方误差(MSE):
其中 yiyi 为一个batch中第i个数据的正确答案,而 y′y′ 为神经网络给出的预测值。一下代码展示了如何通过Tensorflow实现均方误差损失函数:
mse = tf.reduce_mean(tf.square(y_ - y))2、自定义损失函数
通过自定义损失函数的方法,我们可以使得神经网络优化的结果更加接近实际问题的需求。例如我们在预测商品销售问题中使用的损失函数:
在Tensorflow中可以通过以下代码实现这个损失函数:
loss = tf.reduce_sum(tf.select(tf.greater(v1, v2),
(v1 - v2) * a, (v2-v1) * b))- 1
- 2
tf.greater的输入是两个张量,此函数会比较这两个张量中每一个元素的大小,并返回比较结果。
tf.select函数有三个参数,第一个为选择条件,当选择条件为True时,tf.select函数会选择第二个参数中的值,否则使用第三个参数中的值。
在定义了损失函数之后,下面一个简单的神经网络程序来讲解如何利用自定义损失函数:
loss_less = 1
loss_more = 10
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_) * loss_more, (y_ - y) * loss_less))
train_step = tf.train.AdamOptimizer(0.001).minimize(loss)
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 5000
for i in range(STEPS):
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print("After %d training step(s), w1 is: " % (i))
print sess.run(w1), "\n"
print "Final w1 is: \n", sess.run(w1)三、神经网络优化算法
1、梯度下降算法

 ;
;
;
;
 初始值就在local minimum的位置,则会如何变化?
已经在local minimum位置,所以derivative 肯定是0,因此不会变化;
初始值就在local minimum的位置,则会如何变化?
已经在local minimum位置,所以derivative 肯定是0,因此不会变化;
 值,则cost function应该越来越小;
值?
值,如果cost function变小了,则ok,反之,则再取一个更小的值;
值,则cost function应该越来越小;
值?
值,如果cost function变小了,则ok,反之,则再取一个更小的值;


2、学习率的设置
学习率决定了参数每次更新的幅度,如果幅度过大,可能导致参数在极优值的两侧来回移动,相反,当学习率过小时,虽然能保证收敛性,但是这会大大降低优化速度,我们会需要更多轮的迭代才能达到一个比较理想的优化效果。因此,学习率既不能过大,也不能过小。为了解决学习率不能过大不能过小的问题,TensorFlow提供了灵活的学习率设置方法:指数衰减法
tensorflow.train.exponential_decay(learing_rate,global_step,decay_steps,decay_rate,staircase=False,name=None)- 1
Args:
- learning_rate : 初始学习率,类型为float32 或 float63的张量或者python number类型
- global_step : 一个全局的当前迭代次数,类型为int32 或 int64的张量或者python number类型,不能为负
- decay_steps : 衰减速度,类型为int32 或 int64的张量或者python number类型,必须为正
- decay_rate : 衰减率,类型为float32 或 float63的张量或者python number类型
- staircase : 类型为boolean,通过设置它选择不同的衰减方式,默认为False表示连续衰减,True表示阶梯状衰减
- name : 类型为string,操作的名称
Return:
衰减的学习率
这个函数将指数衰减函数应用于初始化学习率,它使用一个名称为global_step变量去计算衰减学习率,可以将一个在迭代中自增的TensorFlow变量传给它。
这个函数返回一个衰减学习率,计算方式如下:
decayed_learning_rate = learing_rate * decay_rate^(global_step / decay_steps)- 1
如果参数staircase为True,global / decay_steps 转化为一个整数。
Example:每10000轮一个0.96的速度衰减一次
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1#通过exponential_decay函数生成学习率
learning_rate = tf.exponential_decay(starter_learning_rate, global_step,100000, 0.96, staircase=True)#使用指数衰减的学习率。在minimize函数中传入global_step将自动更新global_step参数,从而使得学习率也得到相应更新。
optimizer = tf.GradientDescent(learning_rate)
optimizer.minimize(...my loss..., global_step=global_step)3、过拟合问题
正则化
所谓的过拟合问题指的是当一个模型很复杂时,它可以很好的“记忆”每一个训练数据中的随机噪音的部分而忘记了要去“学习”训练数据中通用的趋势。
为了避免过拟合问题,一个非常常用的方法就是正则化。也就是在损失函数中加入刻画模型复杂程度的指标。假设用于损失函数的为J(θ)J(θ),那此时不直接优化J(θ)J(θ),而是优化J(θ)+λR(w)J(θ)+λR(w)。其中R(w)R(w)刻画的是模型的复杂度,而λλ表示的是模型复杂损失在总损失中的比例。这里的θθ表示的是一个神经网络中所有的参数,它包括边上的权重ww和偏置项bb。一般来说模型复杂度只由权重表示。常用的刻画模型复杂度的函数R(w)R(w)有两种,一种是L1正则化,另一种是L2正则化。这两种都是通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声。这两种正则化的区别是首先L1正则化会让参数变得稀疏(指会有更多参数变为0),而L2正则化则不会(因为参数的平方后会让小的参数变得更小,大的参数变得更大,同样起到了特征选取的功能,而不会让参数变为0)。其次是L1正则化计算不可导,而L2的正则化损失函数可导。
以上是一些简单的正则化基础,下面是神经网络的搭建:
当网络复杂的时候定义网络的结构部分和计算损失函数的部分可能不在一个函数中,这样通过简单的变量这种计算损失函数就不方便了。此时可以使用Tensorflow中提供的集合,它可以在一个计算图(tf.Graph)中保存一组实体(比如张量)。以下是通过集合计算一个5层的神经网络带L2正则化的损失函数的计算过程。
下面都是基于jupyter notebook 的代码:
- 生成模拟数据集。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
data = []
label = []
np.random.seed(0) # 设置随机数生成时所用算法开始的整数值
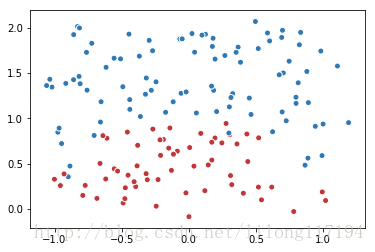
# 以原点为圆心,半径为1的圆把散点划分成红蓝两部分,并加入随机噪音。
for i in range(150):
x1 = np.random.uniform(-1,1) # 随机生成下一个实数,它在 [-1,1) 范围内。
x2 = np.random.uniform(0,2)
if x1**2 + x2**2 <= 1:
data.append([np.random.normal(x1, 0.1),np.random.normal(x2,0.1)])
label.append(0)
else:
data.append([np.random.normal(x1, 0.1), np.random.normal(x2, 0.1)])
label.append(1)
data = np.hstack(data).reshape(-1,2) # 把数据转换成n行2列
label = np.hstack(label).reshape(-1, 1) # 把数据转换为n行1列
plt.scatter(data[:,0], data[:,1], c=label,cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
结果:
#2. 定义一个获取权重,并自动加入正则项到损失的函数。
def get_weight(shape, lambda1):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32) # 生成一个变量
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var)) # add_to_collection()函数将新生成变量的L2正则化损失加入集合losses
return var # 返回生成的变量
#3. 定义神经网络。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
sample_size = len(data)
# 每层节点的个数
layer_dimension = [2,10,5,3,1]
# 神经网络的层数
n_layers = len(layer_dimension)
# 这个变量维护前向传播时最深层的节点,开始的时候就是输入层
cur_layer = x
# 当前层的节点个数
in_dimension = layer_dimension[0]
# 循环生成网络结构
for i in range(1, n_layers):
out_dimension = layer_dimension[i] # layer_dimension[i]为下一层的节点个数
# 生成当前层中权重的变量,并将这个变量的L2正则化损失加入计算图上的集合
weight = get_weight([in_dimension, out_dimension], 0.003)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension])) # 偏置
cur_layer = tf.nn.relu(tf.matmul(cur_layer, weight) + bias) # 使用Relu激活函数
in_dimension = layer_dimension[i] # 进入下一层之前将下一层的节点个数更新为当前节点个数
y= cur_layer
# 在定义神经网络前向传播的同时已经将所有的L2正则化损失加入了图上的集合,这里是损失函数的定义。
mse_loss = tf.reduce_sum(tf.pow(y_ - y, 2)) / sample_size # 也可以写成:tf.reduce_mean(tf.square(y_ - y`))
tf.add_to_collection('losses', mse_loss) # 将均方误差损失函数加入损失集合
# get_collection()返回一个列表,这个列表是所有这个集合中的元素,在本样例中这些元素就是损失函数的不同部分,将他们加起来就是最终的损失函数
loss = tf.add_n(tf.get_collection('losses'))
# 4. 训练不带正则项的损失函数mse_loss。
# 定义训练的目标函数mse_loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(mse_loss)
TRAINING_STEPS = 40000
with tf.Session() as sess:
tf.global_variables_initializer().run() # 初始化所有的变量
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, mse_loss: %f" % (i,sess.run(mse_loss, feed_dict={x: data, y_: label})))
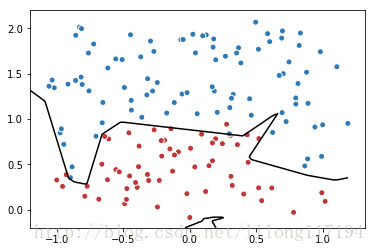
# 画出训练后的分割曲线
xx, yy = np.mgrid[-1.2:1.2:.01, -0.2:2.2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape)
plt.scatter(data[:,0], data[:,1], c=label, cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
运行结果:
After 0 steps, mse_loss: 0.588501
After 2000 steps, mse_loss: 0.039796
After 4000 steps, mse_loss: 0.018524
After 6000 steps, mse_loss: 0.018494
After 8000 steps, mse_loss: 0.018374
After 10000 steps, mse_loss: 0.018358
After 12000 steps, mse_loss: 0.018356
After 14000 steps, mse_loss: 0.018355
After 16000 steps, mse_loss: 0.016440
After 18000 steps, mse_loss: 0.013988
After 20000 steps, mse_loss: 0.013142
After 22000 steps, mse_loss: 0.012886
After 24000 steps, mse_loss: 0.012700
After 26000 steps, mse_loss: 0.012550
After 28000 steps, mse_loss: 0.006441
After 30000 steps, mse_loss: 0.006439
After 32000 steps, mse_loss: 0.006438
After 34000 steps, mse_loss: 0.006438
After 36000 steps, mse_loss: 0.006445
After 38000 steps, mse_loss: 0.006438- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
#5. 训练带正则项的损失函数loss。
# 定义训练的目标函数loss,训练次数及训练模型
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
TRAINING_STEPS = 40000
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
sess.run(train_op, feed_dict={x: data, y_: label})
if i % 2000 == 0:
print("After %d steps, loss: %f" % (i, sess.run(loss, feed_dict={x: data, y_: label})))
# 画出训练后的分割曲线
xx, yy = np.mgrid[-1:1:.01, 0:2:.01]
grid = np.c_[xx.ravel(), yy.ravel()]
probs = sess.run(y, feed_dict={x:grid})
probs = probs.reshape(xx.shape)
plt.scatter(data[:,0], data[:,1], c=label,cmap="RdBu", vmin=-.2, vmax=1.2, edgecolor="white")
plt.contour(xx, yy, probs, levels=[.5], cmap="Greys", vmin=0, vmax=.1)
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行结果:
After 0 steps, loss: 0.705000
After 2000 steps, loss: 0.056949
After 4000 steps, loss: 0.045995
After 6000 steps, loss: 0.041472
After 8000 steps, loss: 0.040165
After 10000 steps, loss: 0.039961
After 12000 steps, loss: 0.039916
After 14000 steps, loss: 0.039912
After 16000 steps, loss: 0.039912
After 18000 steps, loss: 0.038334
After 20000 steps, loss: 0.038128
After 22000 steps, loss: 0.037962
After 24000 steps, loss: 0.037932
After 26000 steps, loss: 0.037921
After 28000 steps, loss: 0.037918
After 30000 steps, loss: 0.037910
After 32000 steps, loss: 0.037908
After 34000 steps, loss: 0.037910
After 36000 steps, loss: 0.037907
After 38000 steps, loss: 0.037905- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
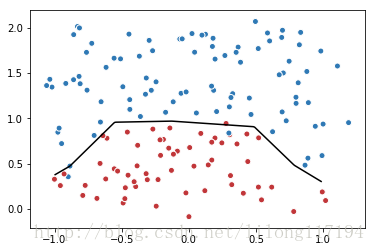
以上是代码的具体运行过程和运行结果。
4、滑动平均模型
在TensorFlow中提供了tf.train.ExponentialMovingAverage 来实现滑动平均模型,在采用随机梯度下降算法训练神经网络时,使用其可以提高模型在测试数据上的健壮性(robustness)。
TensorFlow下的 tf.train.ExponentialMovingAverage 需要提供一个衰减率decay。该衰减率用于控制模型更新的速度。该衰减率用于控制模型更新的速度,ExponentialMovingAverage 对每一个待更新的变量(variable)都会维护一个影子变量(shadow variable)。影子变量的初始值就是这个变量的初始值,
上述公式与之前介绍的一阶滞后滤波法的公式相比较,会发现有很多相似的地方,从名字上面也可以很好的理解这个简约不简单算法的原理:平滑、滤波,即使数据平滑变化,通过调整参数来调整变化的稳定性。
在滑动平滑模型中, decay 决定了模型更新的速度,越大越趋于稳定。实际运用中,decay 一般会设置为十分接近 1 的常数(0.999或0.9999)。为了使得模型在训练的初始阶段更新得更快,ExponentialMovingAverage 还提供了 num_updates 参数来动态设置 decay 的大小:
用一段书中代码带解释如何使用滑动平均模型:
import tensorflow as tf
v1 = tf.Variable(0, dtype=tf.float32)//初始化v1变量
step = tf.Variable(0, trainable=False) //初始化step为0
ema = tf.train.ExponentialMovingAverage(0.99, step) //定义平滑类,设置参数以及step
maintain_averages_op = ema.apply([v1]) //定义更新变量平均操作
with tf.Session() as sess:
# 初始化
init_op = tf.global_variables_initializer()
sess.run(init_op)
print sess.run([v1, ema.average(v1)])
# 更新变量v1的取值
sess.run(tf.assign(v1, 5))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
# 更新step和v1的取值
sess.run(tf.assign(step, 10000))
sess.run(tf.assign(v1, 10))
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
# 更新一次v1的滑动平均值
sess.run(maintain_averages_op)
print sess.run([v1, ema.average(v1)])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
output:
[0.0, 0.0]
[5.0, 4.5]
[10.0, 4.5549998]
[10.0, 4.6094499]