从统计推断讲起
统计推断是根据样本信息对总体分布或总体的特征数进行推断,事实上,这经典学派对统计推断的规定,这里的统计推断使用到两种信息:总体信息和样本信息;而贝叶斯学派认为,除了上述两种信息以外,统计推断还应该使用第三种信息:先验信息。下面我们先把是那种信息加以说明。
- 总体信息:总体信息即总体分布或总体所属分布族提供的信息。譬如,若已知“总体是正态分布”等等
- 样本信息:即所抽取的样本的所有特征信息。
- 先验信息:如果我们把抽取样本看作做一次试验,则样本信息就是试验中得到的信息。但实际中,人们在试验之前对要做的问题在经验上和资料上总是已经有所了解的。譬如之前文章中的那个例子,问在公园中随便看到一个穿凉鞋的人是男生还是女生,男女生穿凉鞋的概率可能不同,这叫做类条件概率,而男女生的比例就是先验概率。
在之前介绍最后后验估计时已经很清楚的讲了MAP与MLE的区别,MAP就是贝叶斯估计的方法之一。贝叶斯学派的MAP方法与频率学派的MLE方法的不同之处就在于先验信息的使用。
贝叶斯估计核心问题
这里定义已有的样本集合为,而不是之前的
。样本集合
中的样本都是从一个 固定但是未知 的概率密度函数
中独立抽取出来的,要求根据这些样本估计
的概率分布,记为
,并且使得
尽量的接近
,这就是贝叶斯估计的核心问题。
贝叶斯估计常用方法
被称作后验分布(后验概率),使用它估计
有三种常用的方法:
- 使用后验分布的密度函数最大值点作为
的点估计的最大后验估计(MAP)。
- 使用后验分布的中位数作为
- 使用后验分布的均值作为
用的最多的是后验期望估计,它一般也直接简称为贝叶斯估计,即为.
贝叶斯定理:
边缘概率(又称先验概率)是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
贝叶斯定理是关于随机事件A和B的条件概率和边缘概率的一则定理。
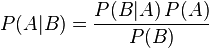
在参数估计中可以写成下面这样:
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
在贝叶斯定理中,每个名词都有约定俗成的名称:
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率(在B发生的情况下A发生的可能性),也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)
按这些术语,Bayes定理可表述为:
后验概率 = (似然函数*先验概率)/标准化常量,也就是说,后验概率与先验概率和似然函数的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes定理可表述为:
后验概率 = 标准相似度*先验概率
一个简单的例子
贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。极大似然估计和极大后验概率估计,都求出了参数的值,而贝叶斯估计则不是,贝叶斯估计扩展了极大后验概率估计MAP(一个是等于,一个是约等于)方法,它根据参数的先验分布
和一系列观察
,求出参数
的后验分布
,然后求出
的期望值,作为其最终值。另外还定义了参数的一个方差量,来评估参数估计的准确程度或者置信度。
贝叶斯估计:从分布的总体信息和参数的先验知识以及样本信息出发。
不同于ML估计,不再把参数看成一个未知的确定变量,而是看成未知的随机变量,通过对第
类样本
的观察,使概率密度分布
转化为后验概率
,再求贝叶斯估计。
假设:将待估计的参数看作符合某种先验概率分布的随机变量。
基本原理:

我们期望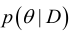
值处有一个尖峰。
贝叶斯估计的本质:贝叶斯估计的本质是通过贝叶斯决策得到参数的最优估计,使得总期望风险最小。

损失函数:通常规定函数是一个二次函数,即平方误差损失函数:
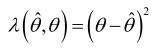
可以证明,如果采用平方误差损失函数,则θ的贝叶斯估计值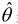
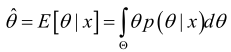
同理可得,在给定样本集D下,θ的贝叶斯估计值是:
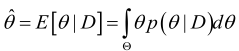
贝叶斯估计算法:

贝叶斯估计的增量学习
为了明确的表示样本集合中有
个样本,这里采用记号:
。根据前一个公式,在
的情况下有:
注:因为每次抽样之间是独立的,所以前次抽样与第
次抽样是独立的。
可以很容易得到:
当没有观测样本时,定义,为参数
的初始估计。然后让样本集合依次进入上述公式,就可以得到一系列的概率密度函数:
,这一过程称为参数估计贝叶斯递归法,也叫贝叶斯估计的增量学习。这是一个在线学习算法,它和随机梯度下降法有很多相似之处。
参考文章: