版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Nicht_sehen/article/details/88920061
简介
PCA:主成分分析(Principal components analysis)
主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(特征向量)与它们的权值(特征值),它提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(也即,这样降低维度必定是失去讯息最少的方法)。
其数学定义为: 一个正交化线性变换,把数据变换到一个新的坐标系统中,使得这一数据的任何投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
总结: PCA可以从数据中识别主要特征,通过将数据坐标轴旋转到数据角度上那些最重要的方向(方差最大),然后通过特征值分析,确定出需要保留的主成分个数,去除多余的信息和噪声,从而实现数据的降维,这个特点使得PCA可以处理一些特征较多的数据,例如人脸。
PCA主要算法
- 计算样本每个特征的平均值
- 用每个样本数据减去该特征的平均值;
- 求协方差矩阵;
- 找到协方差矩阵的特征值和特征向量;
- 对特征值和特征向量重新排列(特征值从大到小排列);
- 选取前n个特征作为主成分
- 利用投影矩阵,得到降维数据
Iris数据集处理
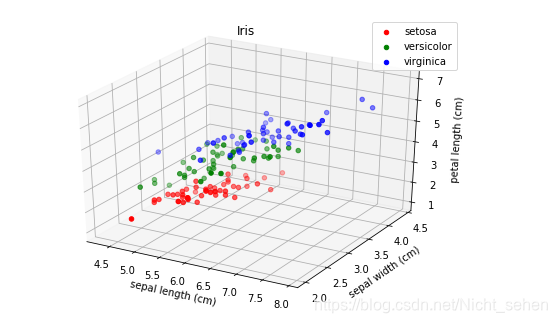
先画个3D图看一下
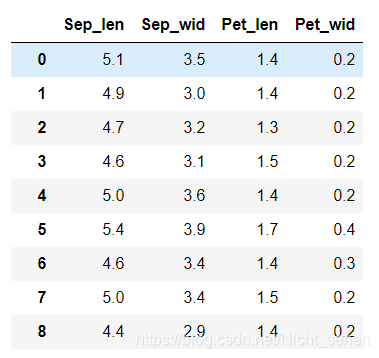
看一下数据集:(我是从本地导入)
import pandas as pd
df = pd.read_csv("C:/Users/Nicht_sehen/Desktop/IRIS.csv")
df_x = df.iloc[::,1:5] # 本地数据集有其他东西,进行了切片
df_y = df['Iris_type']
df_x
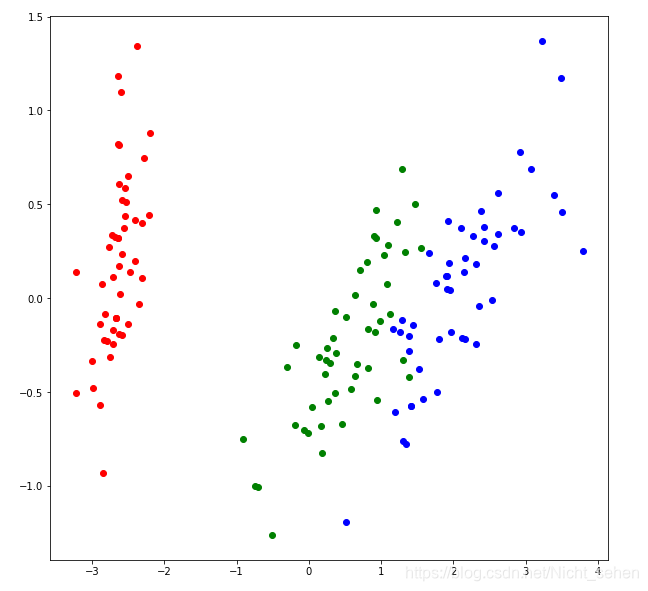
主成分分析:
代码如下:
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import numpy as np
pca = PCA(n_components = 2) #保留两个
df_1 = pca.fit_transform(df_x)
ax = plt.figure(figsize=(10,10))
index1=np.where(df_y== 'Iris-setosa')
index2=np.where(df_y== 'Iris-versicolor')
index3=np.where(df_y== 'Iris-virginica')
# labels=['setosa', 'versicolor', 'virginica']
plt.plot(df_1[index1][:,0],df_1[index1][:,1],'ro')
plt.plot(df_1[index2][:,0],df_1[index2][:,1],'go')
plt.plot(df_1[index3][:,0],df_1[index3][:,1],'bo')
降维后: