这个例子给新人参考爬虫思路和scrapy框架的使用吧……
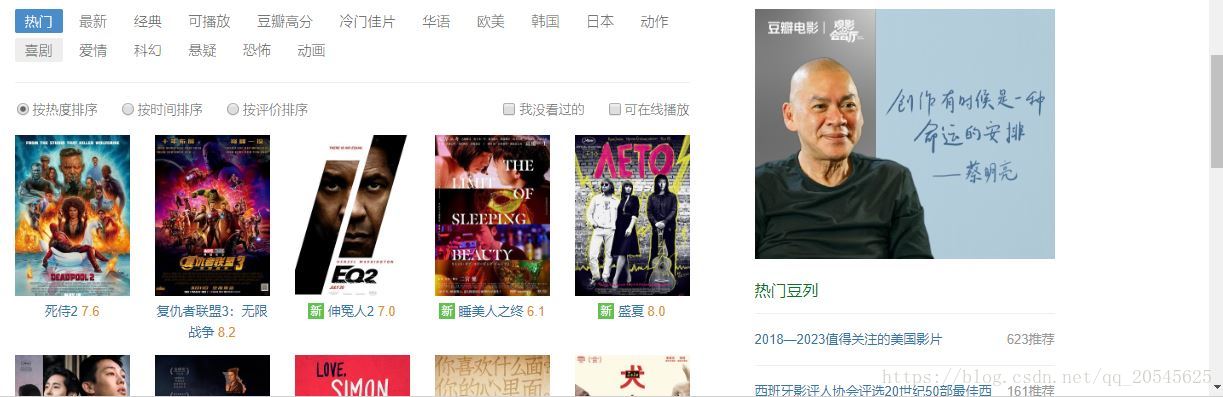
很明显tag是类别标签,page_limit是显示电影最大数,page_start 是偏移量(类似)
通过抓包可以抓到一个json电影的页面
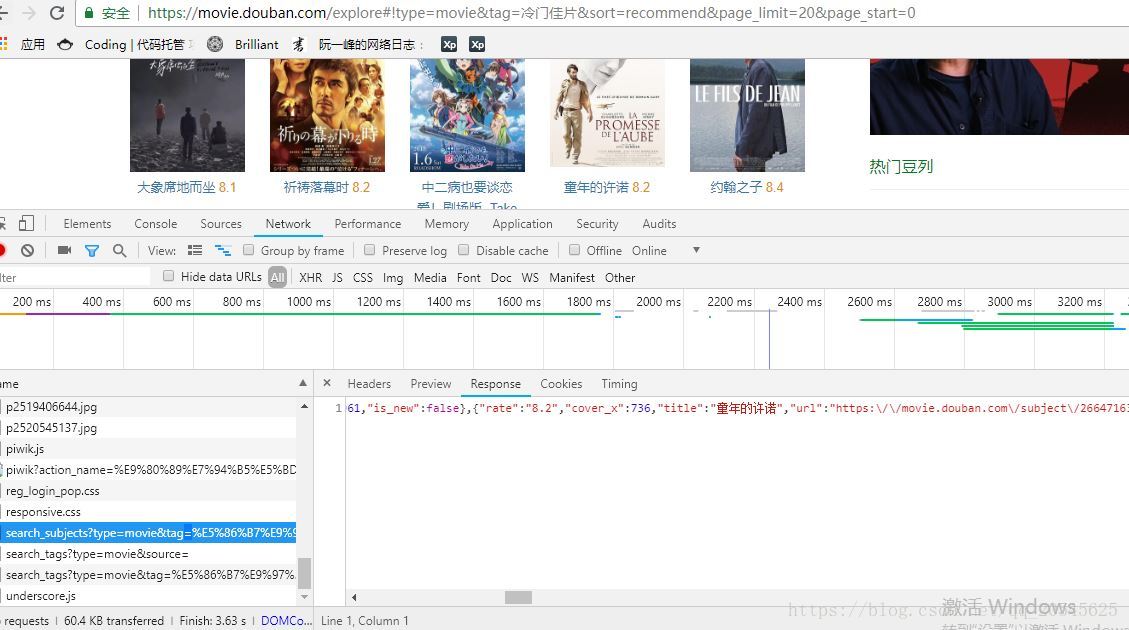
用这个链接通过控制偏移量和标签和抓包进行获取信息
实现代码如下:
# -*- coding: utf-8 -*-
import scrapy
from douban_movie.items import DoubanMovieItem
import time
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
page_count = 100000 #爬取page_count*20的电影数据
def start_requests(self):
time.sleep(1)
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag={type}&sort=time&page_limit=20&page_start={count}'
# type_list = map(lambda x : urllib.urlencode(x),
# [u'华语',u'欧美',u'韩国',u'日本',u'动作',u'喜剧',u'爱情',u'科幻',u'喜剧',u'爱情',u'科幻',u'悬疑',u'恐怖',u'治愈'])
type_list = [u'华语',u'欧美',u'韩国',u'日本',u'动作',u'喜剧',u'爱情',u'科幻',u'喜剧',u'爱情',u'科幻',u'悬疑',u'恐怖',u'治愈']
for t in type_list:
self.movie_type = t
for i in range(self.page_count):
yield scrapy.Request(url.format(type=t,count=i*20))
def parse(self, response):
items = DoubanMovieItem()
data_list = json.loads(response.text)
for data in data_list[u'subjects']:
items['title'] = data[u"title"] #这里获取标题
items['rate'] = data[u"rate"] #这里获取评分
# scrapy.Request(url=data[u'url'], callback=self.text_parse)
# items['simple_text'] =
items['type'] = self.movie_type
yield items
# def text_parse(self,response):
# yield response.xpath('//div[@id="link-report"]/span/text()').extract_first().strip()
爬取完内容后就写一下管道代码(我是用mongdb保存的)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class DoubanMoviePipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
def __init__(self, mongoip, mongoport):
self.mongoip = mongoip
self.mongoport = mongoport
def process_item(self, item, spider):
self.db.movie_set.insert({u'电影名' : item['title'],
u'评分' : item['rate'],
u'电影类型' : item['type']
# u'内容简介' : item['simple_text']
})
return item
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.get('MONGO_URL'),
crawler.settings.get('MONGO_PORT'))
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongoip, self.mongoport)
self.db = self.client.douban
这样就可以了吗?当然不行,可是要抓取上万数据的,过多的访问请求会让服务器暂时ban了你的IP,所以我们要设置代理(在下载中间件控制)
class DoubanMovieDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def __init__(self,pool_ip,pool_port):
self.proxypool_ip = pool_ip
self.proxypool_port = pool_port
self.port = 23333
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls(pool_ip = crawler.settings.get('PROXY_SERVER_IP'),
pool_port = crawler.settings.get('PROXY_SERVER_PORT')
)
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
self.sck.sendto(233,(self.proxypool_ip,self.proxypool_port))
request.meta['proxy'] = self.sck.recv()
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
self.sck = socket.socket(socket.AF_INET, socket.SOCK_DGRAM, 0)
self.sck.bind(('127.0.0.1',self.port))
代理池我是通过爬取别人的代理网站获取代理服务器,然后再通过UDP传输代理服务器IP
我的代理池代码如下:
扫描二维码关注公众号,回复:
2608653 查看本文章

# coding:UTF-8
import requests
# from multiprocessing import Pool,Process
import threading
import socket
from random import choice
from lxml import etree
proxy_list = []
port = 14382
ip = '127.0.0.1'
proxy_max = 2
max_page = 1000 #爬约1000页的数据
proxies = {
'http': 'http://{ip}:{port}',
'https': 'http://{ip}:{port}'
}
headers = {
'user-agent' : 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
}
url = 'https://www.kuaidaili.com/free/intr/%d/'
test_url = 'http://tool.chinaz.com'
def get_proxy_spider():
page_num = 1
response = requests.get(url=url%page_num,headers=headers)
html = etree.HTML(response.text)
thread_pool = []
Proxies_list = html.xpath('//tbody/tr')
while len(proxy_list) <= proxy_max and page_num < max_page:
for p in Proxies_list:
proxy = {'http' : proxies['http'].format(ip=p.xpath('td[@data-title="IP"]/text()')[0],
port = p.xpath('td[@data-title="PORT"]/text()')[0]),
'https' : proxies['https'].format(ip=p.xpath('td[@data-title="IP"]/text()')[0],
port = p.xpath('td[@data-title="PORT"]/text()')[0])
}
thread_pool.append(threading.Thread(target=test_proxy,args=(proxy,)))
[thread.start() for thread in thread_pool]
page_num += 1 #get new page
next_response = requests.get(url=url%page_num,headers=headers)
html = etree.HTML(next_response.text)
Proxies_list = html.xpath('//tbody/tr')
thread_pool = [] #清空线程
def test_proxy(proxies):
if len(proxy_list) >= proxy_max:
return None
try:
requests.get(url = test_url,headers = headers, proxies = proxies,timeout = 5.0)
#print proxies,'Can get url.Add to list...'
except requests.RequestException,e :
pass
else:
proxy_list.append(proxies['http'])
def start_service(proxylist): #开启socket 服务向数据获取
try :
sck = socket.socket(socket.AF_INET,socket.SOCK_DGRAM,0)
sck.bind((ip,port))
while True:
data,src_addr = int(sck.recvfrom(4))
if data == 233:
sck.sendto(choice(proxylist),tuple(src_addr.split(':')))
except socket.errno,e:
print 'Server open up false...\n',e
if __name__ == '__main__':
print 'Start thread to get...'
get_proxy_spider()
print 'Ok...'
print proxy_list
print 'Start UDP server....'
print 'ip:%s,port:%s'%(ip,port)
start_service()
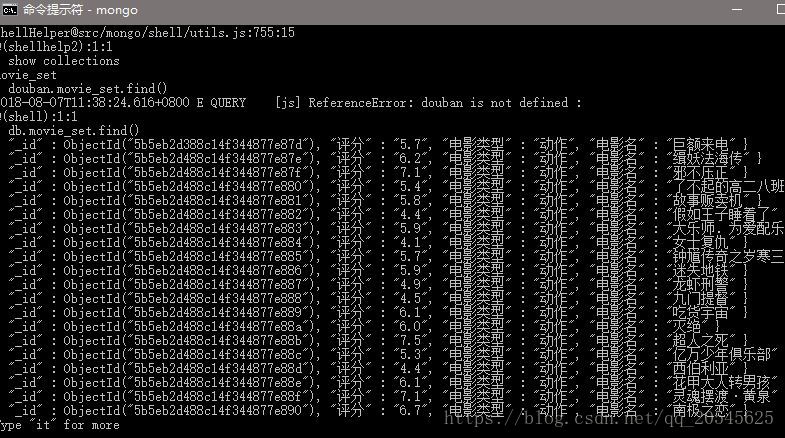
爬取结果如图:
转载请注明作者!