背景
看小甲鱼视频时,在爬虫部分提到scrapy框架。于是找更多文章来读,碰巧在知乎上发现一个较好的教程:
Scrapy爬虫框架教程1–Scrapy入门
Scrapy爬虫框架教程2–爬取豆瓣电影TOP250
Scrapy爬虫框架教程3–调试(Debugging)Spiders
Scrapy爬虫框架教程4–抓取AJAX异步加载项
这个教程讲得还是挺详细的。一步一步跟着教程做,可以实现爬取豆瓣电影榜单的功能,掌握scrapy的基本用法。只是其中有两个小问题,我会在下面列出来。
我认为难点在于学会使用XPath函数,以及Scrapy框架源码。关于源码,这几篇文章讲的不错:
Scrapy源码分析
作者较详细地分析了Scrapy内部的模块构成,模块之间的协同方式,以及源码的细节。只有知道源码,才能在scrapy框架的基础上二次开发出更适合自己需求的框架,阅读源码也是最好的学习方式。
不仅这个系列,其他文章也写得很好,可以多看看。
环境
- Win10
- Pycharm 2018.3.1
- Scrapy 1.5.1
安装步骤不多说了,教程里有。安装过程中有一些坑,详情参考之前的博客内容。
安装Scrapy失败的解决方法
运行Scrapy时报win32api错误
实操
爬取豆瓣电影榜单TOP250
- 打开Pycharm,选择Terminal窗口,用cd命令进入要新建项目的文件夹,我的文件夹名字是spider;
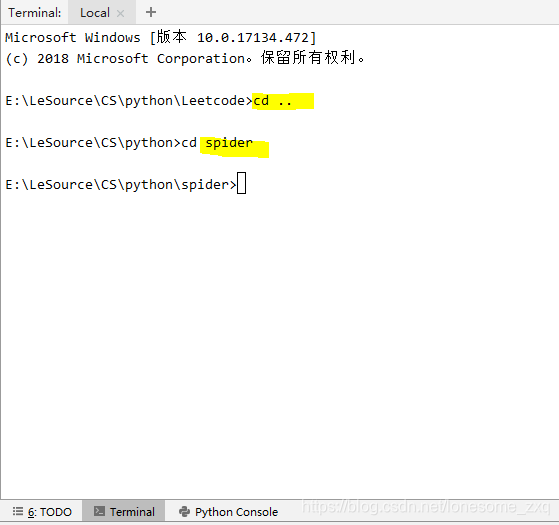
- 输入scrapy startproject scrapyspider命令,创建一个新项目scrapyspider;

- 用Pycharm打开新建的项目,file->open,打开新建的项目。

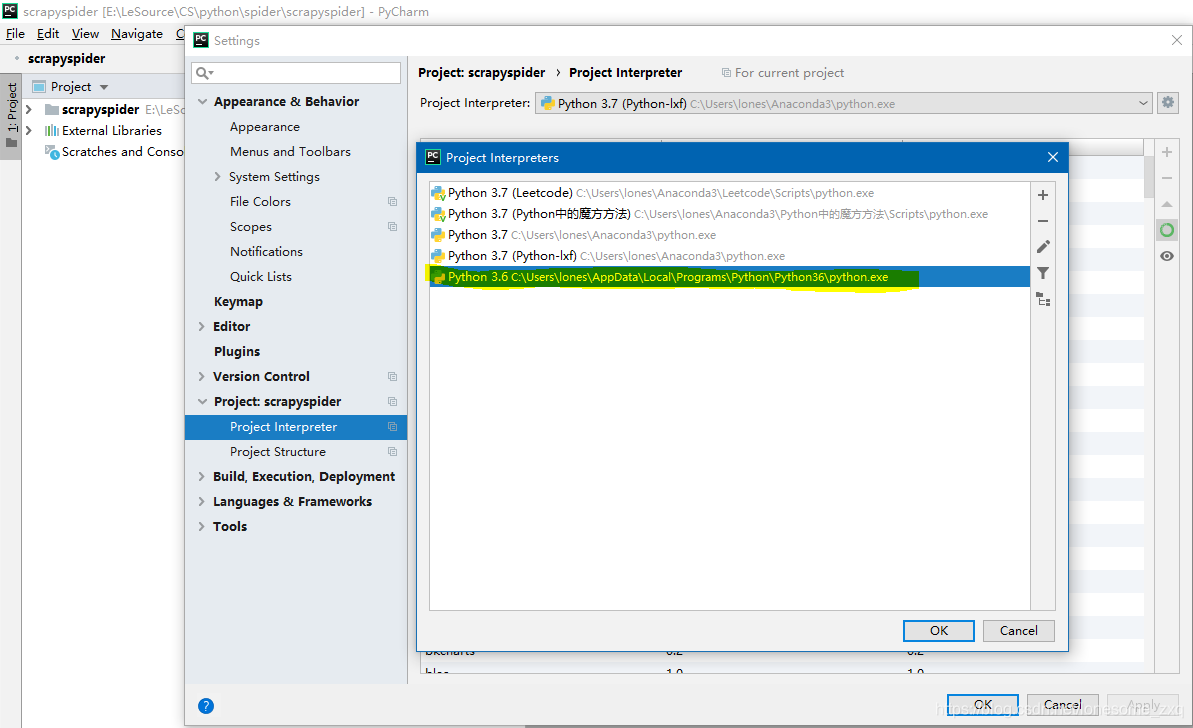
- 为项目配置Interpreters。注意:此Interpreters中应当已安装scrapy module。选择OK,然后apply。
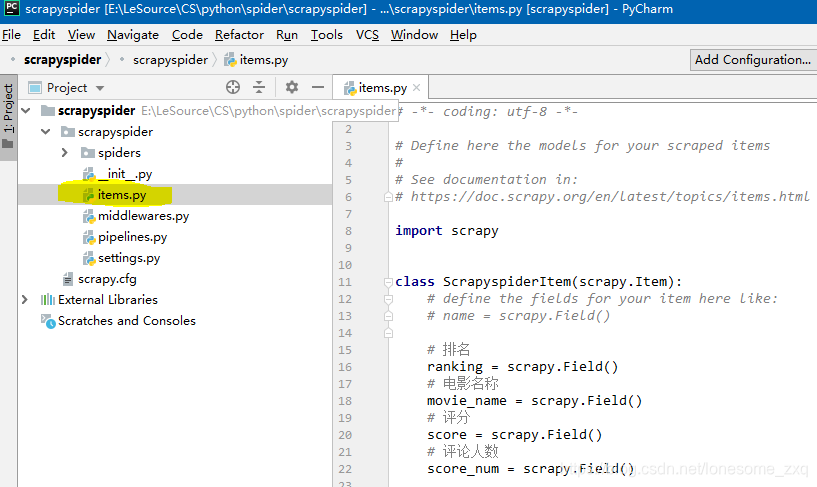
- 展开项目文件夹。每个文件的含义请参考教程,这里不做详细解释。打开items文件。
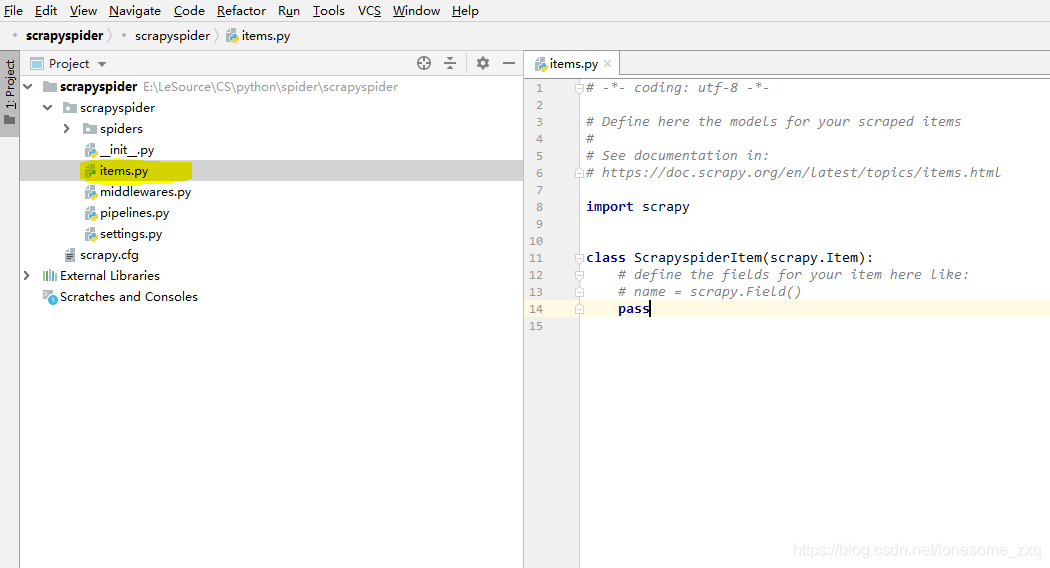
- 我们一共要抓取榜单中的4项数据,在items中声明四个容器。
源码如下:
import scrapy
class ScrapyspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
score_num = scrapy.Field()
- 展开spiders文件夹,在文件夹中新建douban_spider.py
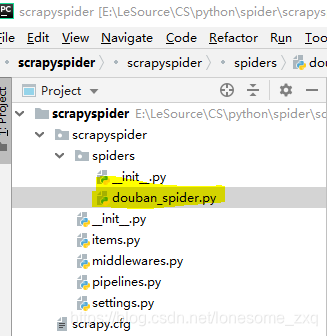
- 在其中根据业务需求编写源码。
源码如下: