看了几篇博客,跟着其他大佬的讲解学习了一下使用scrapy框架爬取网站信息,然后自己趁热打铁一波爬取一下豆瓣电影top250
运行环境
1. win7-64bit
2. python 3.5.3
可以看到该页面结构如下图
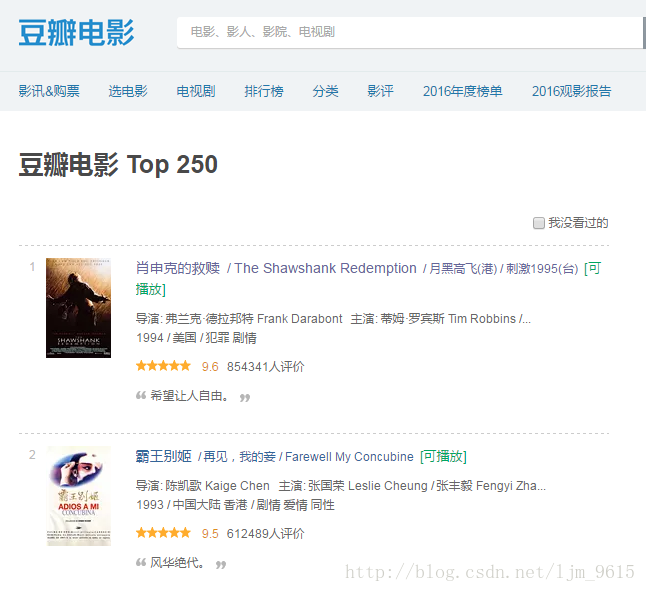
而要爬取的部分为
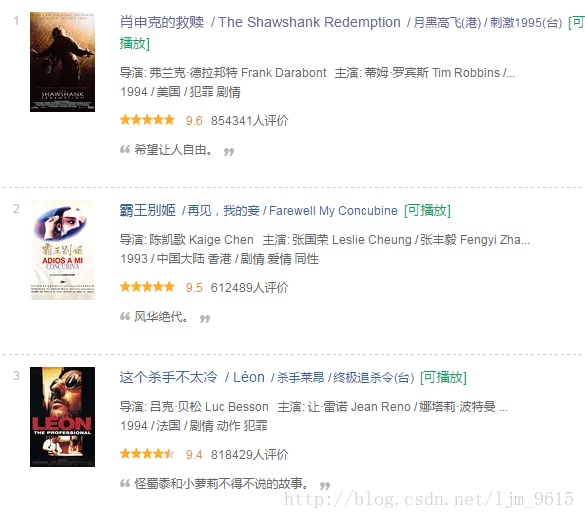
通过查看源代码,需要解析的代码就是这么一部分
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救赎" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>854341人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>创建项目
首先创建项目,cmd输入命令
scrapy startproject doubanmovie创建项目成功,项目目录结构如下图
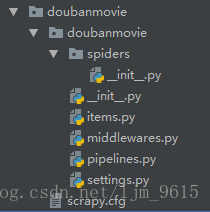
1. 在spiders文件夹下编写自己的爬虫
2. 在items中编写容器用于存放爬取到的数据
3. 在pipelines中对数据进行各种操作
4. 在settings中进行项目的各种设置。
爬虫定义
在spiders文件夹下创建文件MySpider.py
在MySpider.py中创建类DoubanMovie继承自scrapy.Spider,同时定义以下属性和方法
- name : 爬虫的唯一标识符
- start_urls : 初始爬取的url列表
- parse() : 每个初始url访问后生成的Response对象作为唯一参数传给该方法,该方法解析返回的Response,提取数据,生成item,同时生成进一步要处理的url的request对象
其中parse()方法内使用scrapy框架中的Selector对Response对象进行解析。初步写好的代码如下:
import scrapy
class DoubanMovie(scrapy.Spider):
# 爬虫唯一标识符
name = 'doubanMovie'
# 爬取域名
allowed_domain = ['movie.douban.com']
# 爬取页面地址
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
print(response.body)
尝试运行一下发现出现403错误

说明爬虫被屏蔽了,那么就要增加一个请求头部,模拟浏览器登录。
在settings文件中添加下面一行代码即可
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'接下来就可以成功运行。
Items定义
在doubanmovie文件夹下创建文件MovieItems.py,在该文件下编写存放爬取到的数据的容器
创建类MovieItem继承自scrapy.Item,定义各种属性,语句类似以下
name = scrapy.Field()写好的代码如下
import scrapy
class MovieItem(scrapy.Item):
# 电影名字
name = scrapy.Field()
# 电影信息
info = scrapy.Field()
# 评分
rating = scrapy.Field()
# 评论人数
num = scrapy.Field()
# 经典语句
quote = scrapy.Field()
# 电影图片
img_url = scrapy.Field()数据解析
目前在MySpider.py文件中只获得了Response对象,要从中提取各种信息,不得不对Response对象进行解析,这里选择使用scrapy框架中的Selector。
首先初始化selector
selector = scrapy.Selector(response)通过网站源代码解析出各个电影项
movies = selector.xpath('//div[@class="item"]')再声明一个item用于存放电影信息
item = MovieItem()之后对每个电影代码段进行解析,从中提取出所需信息存放在item中,由于电影名字有不同种语言类型,同时电影信息也不止一个字符串,如下
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span><p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>如果使用下列语句提取文本首个字符串会丢失信息
titles = movie.xpath('.//span[@class="title"]/text()').extract()[0].strip()
infos = movie.xpath('.//div[@class="bd"]/p/text()').extract()[0].strip()这里通过对list遍历获取全部信息
# 电影各种语言名字的列表
titles = movie.xpath('.//span[@class="title"]/text()').extract()
name = ''
for title in titles:
name += title.strip()
item['name'] = name此时parse()解析出各个电影信息,但是只是第一页,通过网页源代码发现
<span class="next">
<link rel="next" href="?start=25&filter="/>
<a href="?start=25&filter=" >后页></a>
</span>可以获取下一页的url,将其提取出来,通过yield处理继续爬取下一页面的电影信息。由于最后一页中下一页为空,在此处加一个判断即可
next_page = selector.xpath('//span[@class="next"]/a/@href').extract()[0]
url = 'https://movie.douban.com/top250' + next_page
if next_page:
yield scrapy.Request(url, callback=self.parse)整个parse()方法代码如下
def parse(self, response):
selector = scrapy.Selector(response)
# 解析出各个电影
movies = selector.xpath('//div[@class="item"]')
# 存放电影信息
item = MovieItem()
for movie in movies:
# 电影各种语言名字的列表
titles = movie.xpath('.//span[@class="title"]/text()').extract()
# 将中文名与英文名合成一个字符串
name = ''
for title in titles:
name += title.strip()
item['name'] = name
# 电影信息列表
infos = movie.xpath('.//div[@class="bd"]/p/text()').extract()
# 电影信息合成一个字符串
fullInfo = ''
for info in infos:
fullInfo += info.strip()
item['info'] = fullInfo
# 提取评分信息
item['rating'] = movie.xpath('.//span[@class="rating_num"]/text()').extract()[0].strip()
# 提取评价人数
item['num'] = movie.xpath('.//div[@class="star"]/span[last()]/text()').extract()[0].strip()[:-3]
# 提取经典语句,quote可能为空
quote = movie.xpath('.//span[@class="inq"]/text()').extract()
if quote:
quote = quote[0].strip()
item['quote'] = quote
# 提取电影图片
item['img_url'] = movie.xpath('.//img/@src').extract()[0]
yield item
next_page = selector.xpath('//span[@class="next"]/a/@href').extract()[0]
url = 'https://movie.douban.com/top250' + next_page
if next_page:
yield scrapy.Request(url, callback=self.parse)数据存储
目前选择将数据存放在json文件中,对数据库的处理在下篇博客有提到。scrapy爬虫数据存入mysql数据库
在doubanmovie文件夹下创建文件MoviePipelines.py,编写类MoviePipeline,重写方法process_item(self, item, spider)用于处理数据。
import json
class MoviePipeline(object):
def __init__(self):
# 打开文件
self.file = open('data.json', 'w', encoding='utf-8')
# 该方法用于处理数据
def process_item(self, item, spider):
# 读取item中的数据
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
# 写入文件
self.file.write(line)
# 返回item
return item
# 该方法在spider被开启时被调用。
def open_spider(self, spider):
pass
# 该方法在spider被关闭时被调用。
def close_spider(self, spider):
self.file.close()同时在settings文件中对pipeline进行注册
ITEM_PIPELINES = {
'doubanmovie.MoviePipelines.MoviePipeline': 1,
}其中数字1表示优先级,越低越优先。
存储完电影信息后,接下来存储电影图片。
存放图片要用到scrapy框架中的ImagesPipeline
在doubanmovie中新建文件ImgPipelines.py,编写类ImgPipeline继承自ImagesPipeline,然后重载方法
1. get_media_requests(self, item, info)
2. item_completed(self, results, item, info)
第一个方法从item中获得url并下载图片,返回一个Request对象,完成下载后,结果作为一个tuple(success, image_info_or_failure)发送给第二个方法。其中success是下载是否成功的bool,image_info_or_failure包括url、path和checksum三项。其中,path就是相对于IMAGES_STORE的路径(含文件名)。
整个文件代码如下
import scrapy
from scrapy.contrib.pipeline.images import ImagesPipeline
from scrapy.exceptions import DropItem
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item['image_url'])
def item_completed(self, results, item, info):
image_url = [x['path'] for ok, x in results if ok]
if not image_url:
raise DropItem("Item contains no images")
item['image_url'] = image_url
return item
同时在settings文件中注册并设置下载目录
ITEM_PIPELINES = {
'doubanmovie.MoviePipelines.MoviePipeline': 1,
'doubanmovie.ImgPipelines.ImgPipeline': 100,
}IMAGES_STORE = 'E:\\img\\'然而在爬取过程中又出现问题:Forbidden by robots.txt
在settings文件中将ROBOTSTXT_OBEY改为False,让scrapy不遵守robot协议,即可正常下载图片
第一个scrapy小项目完工,个人感觉难点在提取不同信息,以及针对爬取网站的各种保密机制采取措施。
目前只是小探一下scrapy框架,其强大的特性待日后慢慢发现研究
最后放上代码点击下载