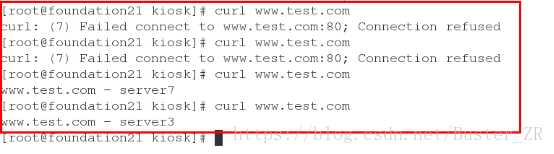
通过 红帽 rhcs 组件进行 nginx 的负载均衡
注:不支持在集群节点中使用NetworkManager。如果已经在集群节点中安装了 NetworkManager,应该删除或者禁用该程序。
1. RHCS 集群管理介绍
1. RHCS集群简介
RHCS(Red Hat Cluster Suite)集群是红帽官方提供的子集群套件,它整合了高可用集群、负载均衡集群、存储集群,从而为用户提供了完整的一套从前端到应用到存储的集群解决方案。通过RHCS集群提供的集群服务,可以为web,数据库等关键业务提供高效,稳定的运行环境。
2. RHCS的核心功能
负载均衡
RHCS的负载均衡集群通过LVS(Linux Virtual Server)来实现其功能,LVS是由前端的调度器与后端的RS节点组成,客户端的访问请求通过调度器根据算法及集群类型的不同将其调度至集群的RS节点,由调度器调度到的RS节点响应客户端请求。同时,LVS提供了故障转移功能,当集群中的RS节点中有任意一个或多个出现故障时,LVS会自动将故障节点下线,将分配到故障节点的客户端请求移到无故障节点运行;故障节点修复,又将重新加入集群继续工作,从而保证了服务的不中断运行。RHCS集群类型有DR,NAT,TUN,FULLNAT,可为各种复杂的网络环境提供不同的解决方案。
高可用
RHCS的高可用集群中的高可用服务在无故障情况下,可运行于任意节点,通过定义组资源或者各种约束关系,将提供同一类服务的资源运行在同一个节点,当提供服务的节点故障或分裂时,集群可通过仲裁设备(非必须)判定资源运行于哪个节点,即拥有法定票数多的一方继续运行集群服务,而故障的或不拥有法定票数的一方则作下线处理。保证了服务的不中断运行。
3. RHCS的核心功能
- 集群管理器CMAN
Cluster Manager,简称CMAN,是一个分布式集群管理工具,它运行在集群的各个节点上,为RHCS提供集群管理任务。CMAN用于管理集群成员、传递节点间心跳信息。它通过监控每个节点的运行状态来了解节点成员之间的关系,当集群中某个节点出现故障,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。cman之上有ccs和fencs两个组件。- 资源组管理器rgmanager
通过定义的集群资源,来管理这些资源,被管理的资源包括故障切换域的定义、资源(如 IP 地址)和服务。它也定义了群集服务和群集服务的故障切换行为。- 集群配置文件管理CCS
其默认配置文件为/etc/cluster/cluster.conf,运行于集群中各节点,当某一节点的配置信息发生改变时,使同一集群内的其他节点的配置文件发生相应变化。- 保护设备Fencs
当 CMAN 决定某个节点已经发生故障,它将告知其他群集基础结构组件。在收到通知后,fenced 将保护(fence)故障节点。其他群集基础结构组件将决定采取什么行动,也就是说,它们执行任何必需的恢复。例如,当 DLM 和 GFS 被告知节点故障时,将暂停活动,直到它们检测到 fenced 已经完成对故障节点的保护。当确认故障节点已经被保护时,DLM 和 GFS 会执行恢复。DLM 释放对失败节点的锁定;GFS 恢复故障节点的日志。GNBD也是Fencs的一个组件。- 分布式锁管理器DLM
分布式锁管理器管理集群中挂载使用GFS的节点来同步它们对共享资源的访问,它运行于每一个集群节点,是集群中所有节点共享锁文件。CLVM使用锁管理器来同步对LVM卷和卷组(也对共享存储)的更新。- 集群文件系统GFS
GFS 是允许集群内所有节点可同时访问某个共享的块设备的集群文件系统。GFS 是一个原生(native)文件系统,它直接和 Linux 内核文件系统接口的 VFS 层进行通信。GFS 使用分布式元数据和多个日志来优化群集操作。要维护文件系统的完整性,GFS 使用一个锁管理器来协调 I/O。当节点修改了 GFS 文件系统上的数据,这个改动马上为使用这个文件系统的其他群集节点可见。同时,GFS使整个群集只需安装一次应用程序或补丁,并可使集群内多个节点的服务对数据可以并行读/写操作。- 集群配置管理工具Conga
Conga是新的基于网络的集群配置工具。它是web界面管理的,由luci和ricci组成,luci可以安装在一台独立的计算机上,也可安装在节点上,用于配置和管理集群,ricci是一个代理,安装在每个集群节点上,luci通过ricci和集群中的每个节点通信。
2. 进行集群配置
1 为各 nginx 节点服务器进行 Conga组件安装
另一个节点也进行同样安装
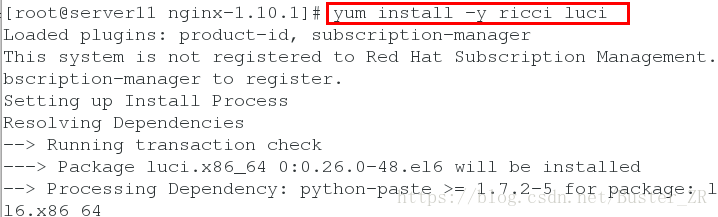
进行 ricci 密码的设定
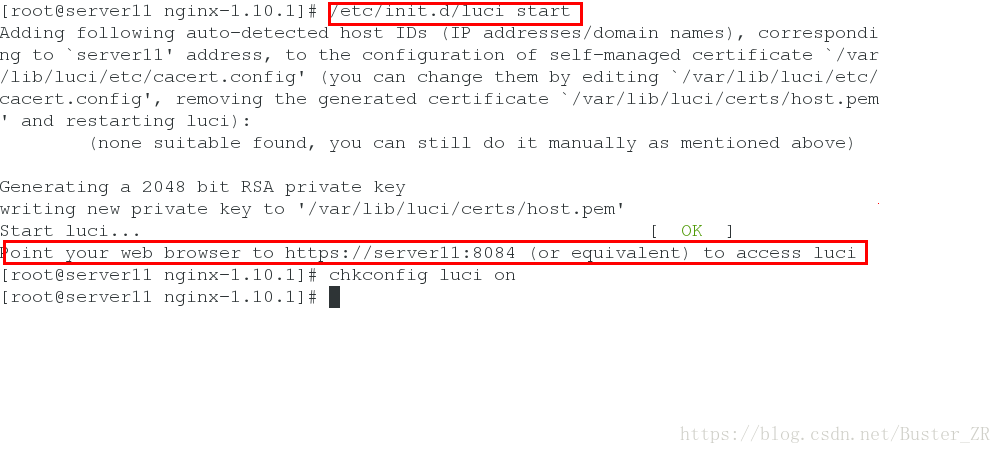
开启ricci服务,并设置开机自启

开启 luci 服务,其端口为 8084 ,可通过 访问 https://172.25.21.11:8084 来进行 luci 服务的登录
进入登录页面,用户名密码为luci 所在用户的用户名密码

登录成功如下:
2. 进行集群配置
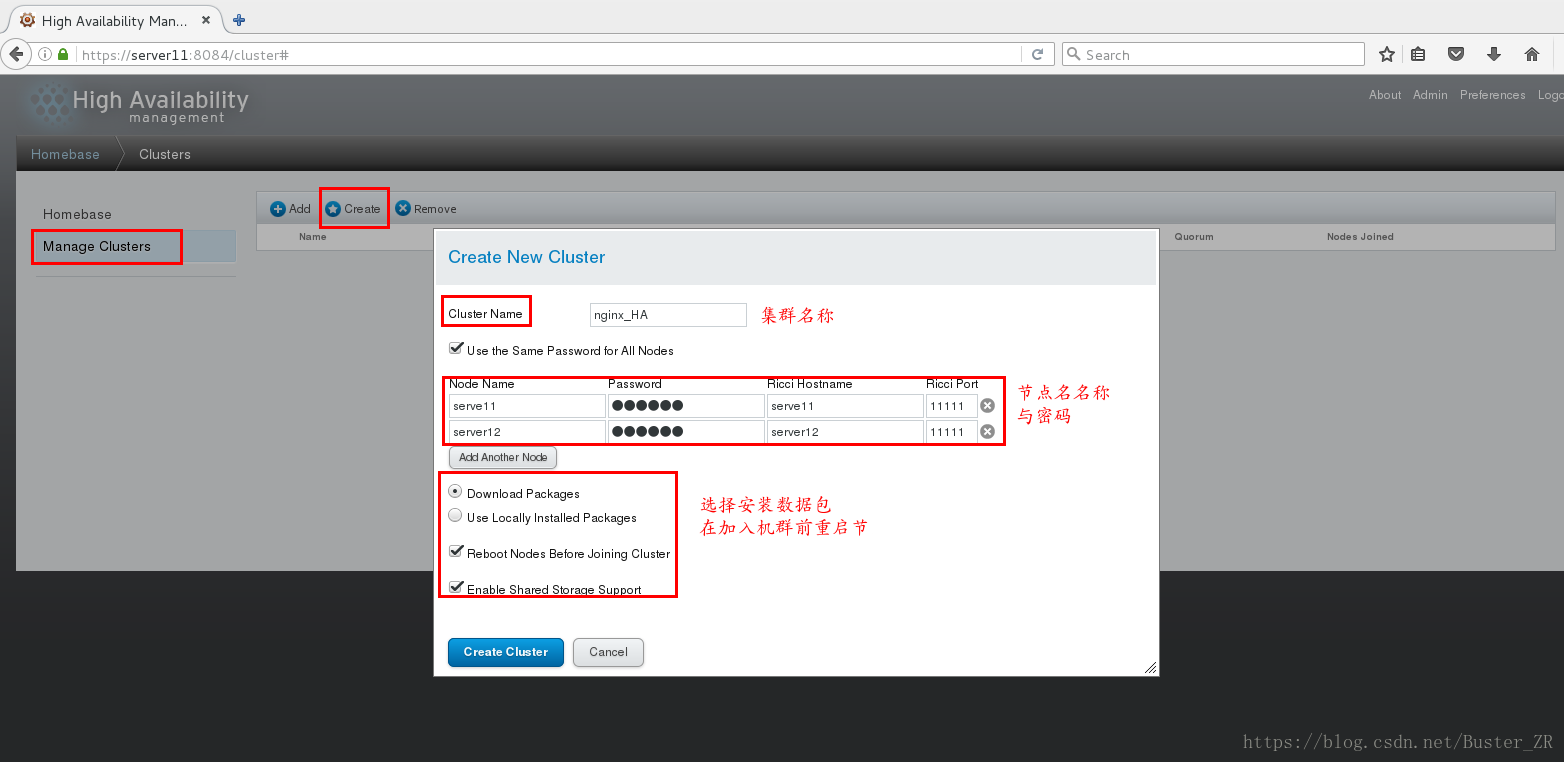
1 添加集群:
添加各个节点的名称,密码,为ricci 密码,并勾选相应的选项
添加成功如下:
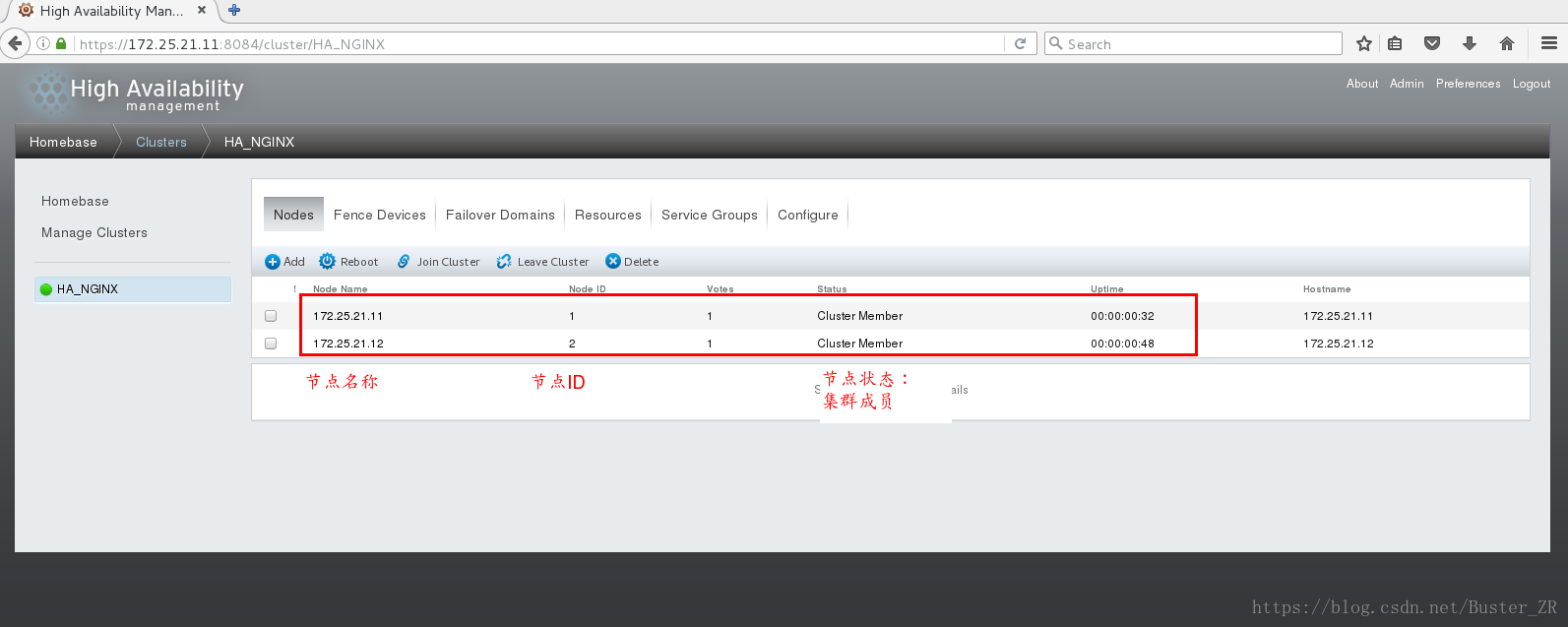
添加成功后,可查看节点状态
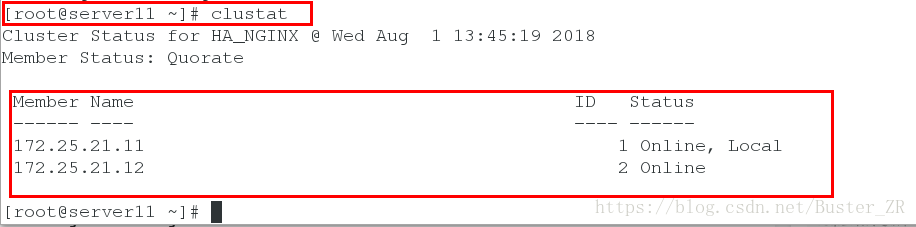
2 进行fence的安装
再次强调一下 fence
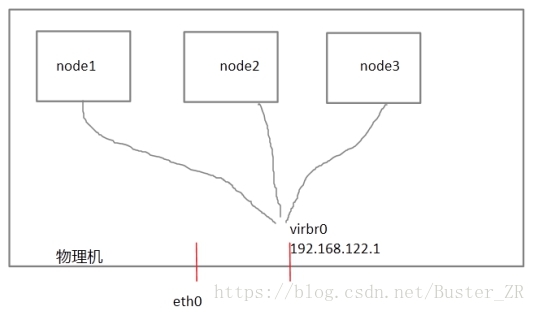
每个节点之间互相发送探测包进行判断节点的存活性。一般会有专门的线路进行探测,这条线路称为“心跳线”(上图直接使用eth0线路作为心跳线)。假设node1的心跳线出问题,则node2和node3会认为node1出问题,然后就会把资源调度在node2或者node3上运行,但node1会认为自己没问题不让node2或者node3抢占资源,此时就出现了脑裂(split brain)。
此时如果在整个环境里有一种设备直接把node1断电,则可以避免脑裂的发生,这种设备叫做fence或者stonith(Shoot The Other Node In The Head爆头哥)。
在物理机里virsh是通过串口线管理guestos的,比如virsh destroy nodeX,这里我们把物理机当成fence设备。
在物理机安装 fence 相关组件:
Yum install fence-* -y
安装完成,执行下述操作
fence_virtd -c 进行对配置文件内容的选定


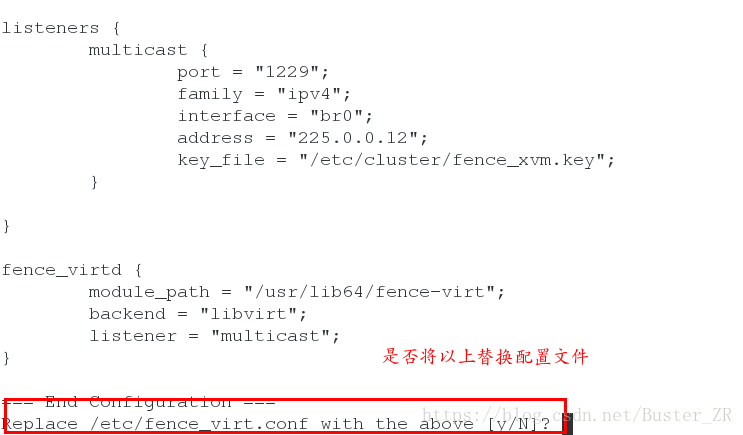
建立密钥,并建立放置其的目录

重启服务: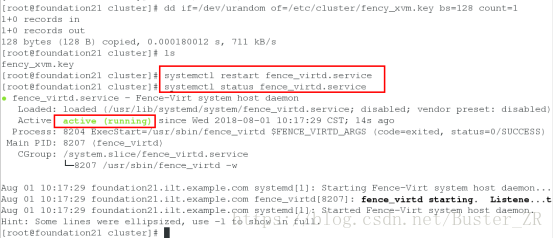
将密钥传递给各节点
Scp /etc/cluster/fency_xvm.key root@172.25.21.11:/etc/cluster
Scp /etc/cluster/fency_xvm.key root@172.25.21.12:/etc/cluster3 添加 fence 设备
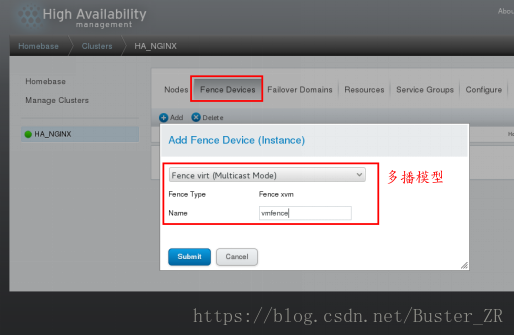
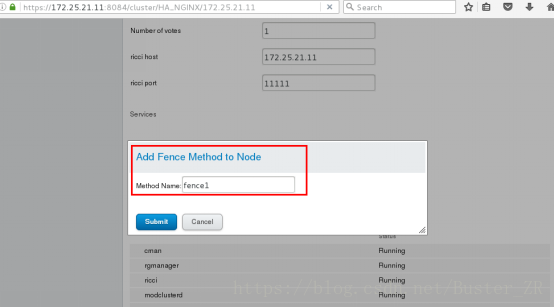
为节点添加 fecne 方法(为两个节点均添加)
为方法添加实例
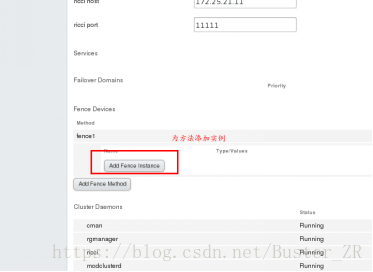
实例的域名是对应节点的 UUID
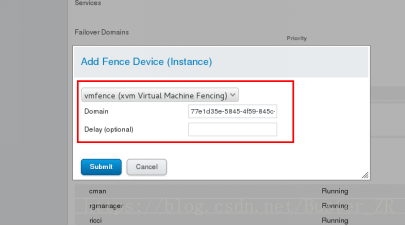
添加成功后如下:
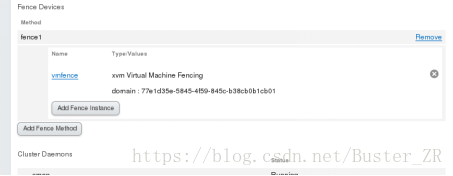
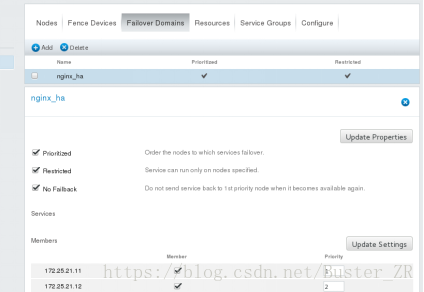
4 添加故障切换域:
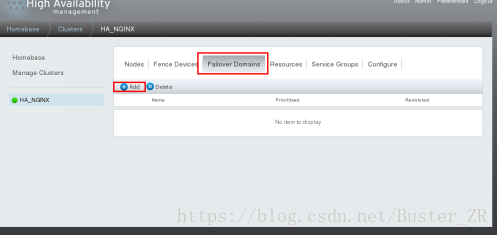
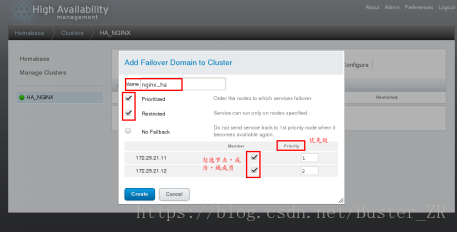
添加成功后:
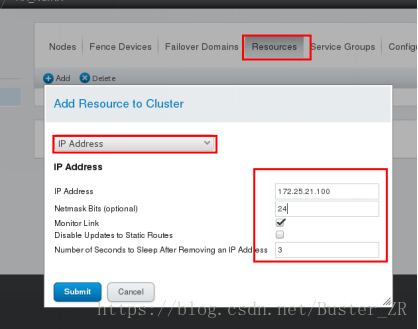
5 为集群添加资源
添加VIP
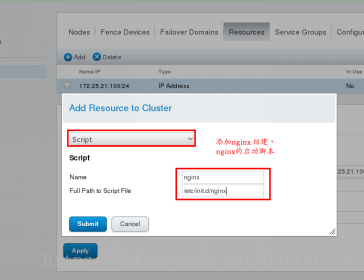
添加启动脚本
Nginx 启动脚本需要自己编写,并移动到 /etc/init.d下,并赋予可执行权限
6 为集群添加服务组,添加服务组之前,关闭两节点的 nginx 服务
否则无法正常启动服务组,因为此服务集群工作类似于原子性,原子性指事务的一个完整操作。操作成功则提交,失败则回滚,即一件事要做就做完整,要么就什么都不做
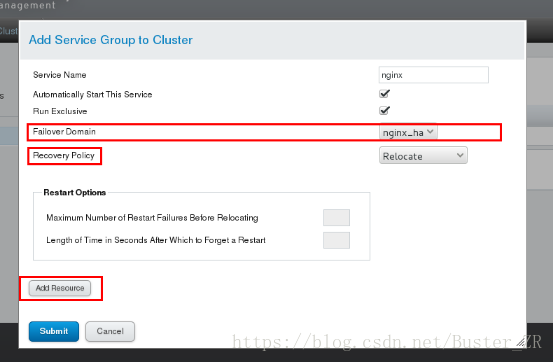
为服务组添加资源
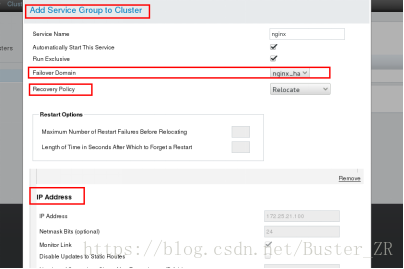
全局资源 ip addres 和 scripts 脚本
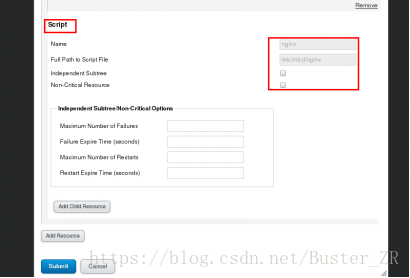
提交后步骤如下
服务组添加成功后选择start 启动
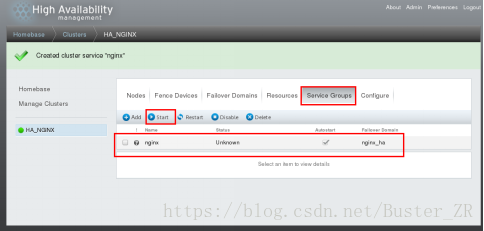
启动之后,显示如下,在设定优先级高的结点上启动
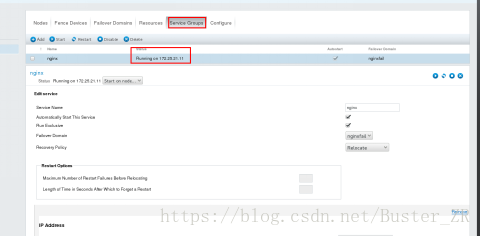
在节点启动后查看如下:
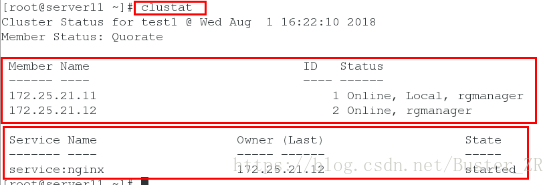
可进行节点切换,将服务转移到另一个节点
- 其高可用体现在:
启动服务组后,自动启动服务组运行所在节点的nginx服务,若是改节点服务宕掉,自动将服务切换到另一个节点,
Fence 会将宕掉的主机进行断电,服务会全部移动到另一个节点上,宕掉的节点回再次启动
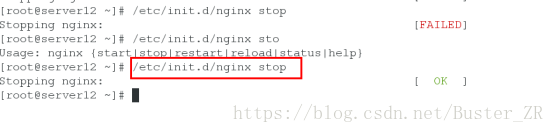
切换服务时:
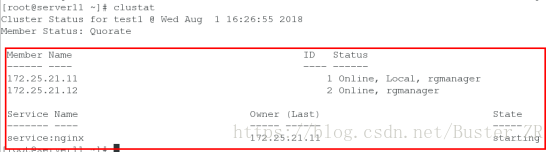
进行nginx 负载均衡时,节点切换的间隔,和切换后后端服务器,nginx负载均衡的效果