机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的,过拟合与欠拟合也可以用 Bias 与 Variance 的角度来解释,欠拟合会导致高 Bias ,过拟合会导致高 Variance ,所以模型需要在 Bias 与 Variance 之间做出一个权衡。
过拟合与欠拟合
使用简单的模型去拟合复杂数据时,会导致模型很难拟合数据的真实分布,这时模型便欠拟合了,或者说有很大的 Bias,Bias 即为模型的期望输出与其真实输出之间的差异;有时为了得到比较精确的模型而过度拟合训练数据,或者模型复杂度过高时,可能连训练数据的噪音也拟合了,导致模型在训练集上效果非常好,但泛化性能却很差,这时模型便过拟合了,或者说有很大的 Variance,这时模型在不同训练集上得到的模型波动比较大,Variance 刻画了不同训练集得到的模型的输出与这些模型期望输出的差异。
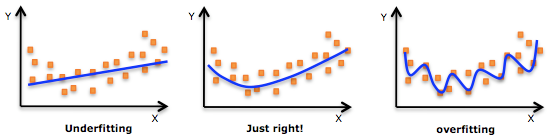
模型处于过拟合还是欠拟合,可以通过画出误差趋势图来观察。若模型在训练集与测试集上误差均很大,则说明模型的 Bias 很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap ,则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。
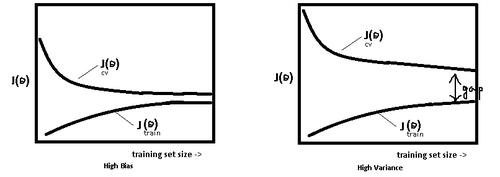
一般在模型效果差的第一个想法是增多数据,其实增多数据并不一定会有更好的结果,因为欠拟合时增多数据往往导致效果更差,而过拟合时增多数据会导致 Gap 的减小,效果不会好太多,多以当模型效果很差时,应该检查模型是否处于欠拟合或者过拟合的状态,而不要一味的增多数据量,关于过拟合与欠拟合,这里给出几个解决方法。
解决欠拟合的方法:
增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
尝试非线性模型,比如核SVM 、决策树、DNN等模型;
如果有正则项可以较小正则项参数 λ.
Boosting ,Boosting 往往会有较小的 Bias,比如 Gradient Boosting 等. 解决过拟合的方法:
Early stop(在模型训练过程中,提前终止)
增加训练数据可以有限的避免过拟合
正则化,常用的有 L1、L2 正则,而且 L1正则还可以自动进行特征选择,如果有正则项则可以考虑增大正则项参数 λ
Droup Out(以一定的概率使某些神经元停止工作,可以从ensemble的角度来看,顺便问下为啥Droup Out效果就是好呢?)
BatchNorm(对神经元作归一化)
交叉检验,通过交叉检验得到较优的模型参数;
特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间
Bagging ,将多个弱学习器 Bagging 一下效果会好很多,比如随机森林等; 交叉检验
当数据比较少是,留出一部分做交叉检验可能比较奢侈,还有只执行一次训练-测试来评估模型,会带有一些随机性,这些缺点都可以通过交叉检验克服,交叉检验对数据的划分如下:
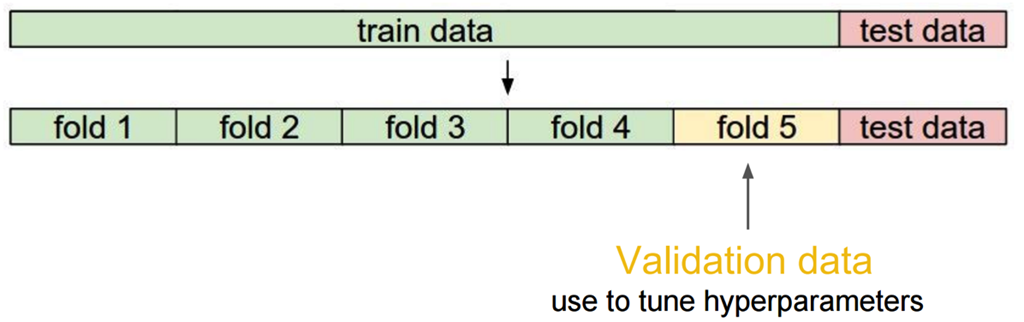
交叉检验的步骤:
将数据分类训练集、验证集、测试集;
选择模型和训练参数;
使用训练集训练模型,在验证集中评估模型;
针对不同的模型,重复2)- 3)的过程;
选择最佳模型,使用训练集和验证集一起训练模型;
使用测试集来最终测评模型。关于正则
在模型的损失函数中引入正则项,可用来防止过拟合,于是得到的优化形式如下:
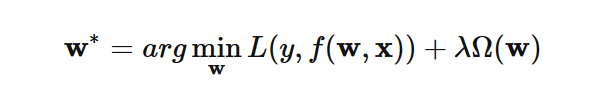
这里 Ω(w)即为正则项, λ 则为正则项的参数,通常为 Lp的形式,即:
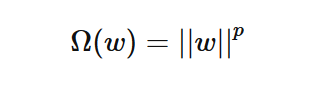
实际应用中比较多的是 L1
与 L2 正则,L1 正则是 L0 正则的凸近似,这里 L0 正则即为权重参数 w 中值为 0 的个数,但是求解 L0 正则是个NP 难题,所以往往使用 L1 正则来近似 L0 , 来使得某些特征权重为 0 ,这样便得到了稀疏的的权重参数 w。关于正则为什么可以防止过拟合,给出三种解释:
正则化的直观解释
对于规模庞大的特征集,重要的特征可能并不多,所以需要减少无关特征的影响,减少后的模型也会有更强的可解释性;L2
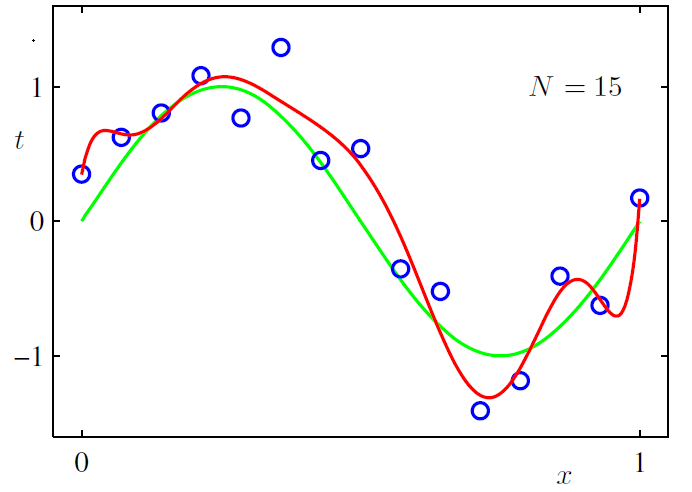
正则可以用来减小权重参数的值,当权重参数取值很大时,导致其导数或者说斜率也会很大,斜率偏大会使模型在较小的区间里产生较大的波动。加入L2 正则后,可使得到的模型更平滑,比如说下图所示曲线拟合,展示了加入L2 正则与不加 L2 的区别:
正则化的几何解释
我们常见的正则,是直接加入到损失函数中的形式,其实关于 L1 与 L2 正则,都可以形式化为以下问题:
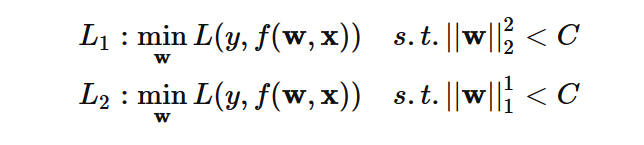
至于两种形式为什么等价呢,运用一下拉格朗日乘子法就好,这里也即通常说的把 w 限制在一个ball 里,对于 lp–ball 的形式如下图所示:
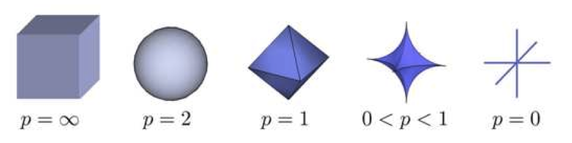
对于 L1 与 L2 正则,分别对应l1–ball 与 l2–ball ,为了方便看,这里给出 l1–ball 与 l2–ball 在二维空间下的图:
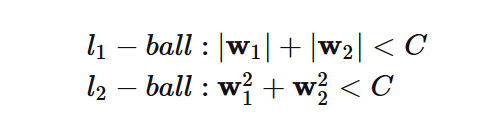
下图中的等高线即为模型的损失函数,上式中的两个约束条件则变成了一个半径为 C 的 norm-ball 的形式,等高线与 norm-ball 相交的地方即为最优解:

可以看到,l1−ball 和每个坐标轴相交的地方都有“角”出现,而目标函数除非位置非常好,大部分时候都会在角的地方相交。注意到在角的位置即导致某个维度为 0 ,这时会导致模型参数的稀疏,这个结论可自然而然的推广到高维的情形;相比之下,l2−ball就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。
正则化的贝叶斯解释
正则化的另一种解释来自贝叶斯学派,在这里可以考虑使用极大似然估计 MLE 的方式来当做损失函数,对于 MLE 中的参数 w
,为其引入参数为 α 的先验,然后极大化 likelihood × prior,便得到了 MLE 的后验估计 MAP 的形式:
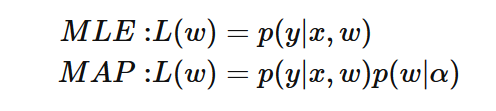
对于 L2 正则,是引入了一个服从高斯分布的先验,而对于 L1 正则,是引入一个拉普拉斯分布的先验,两个分布分别如下:
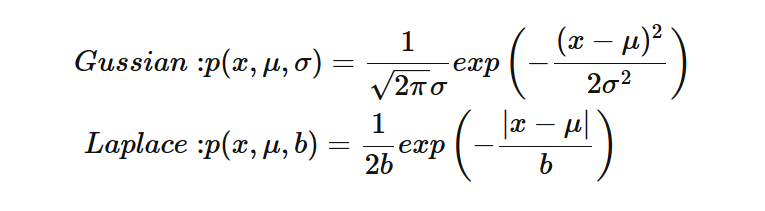
两种分布的概率密度的图形如下所示:
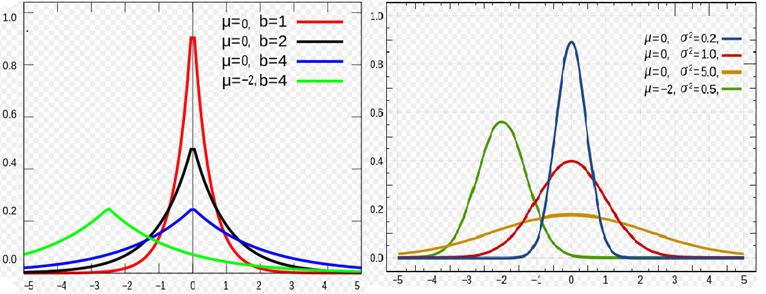
…
…
…
参考文献:
http://www.cnblogs.com/ooon/p/5522957.html
http://breezedeus.github.io/2014/11/15/breezedeus-feature-processing.html 特征组合
http://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting.html
http://blog.csdn.net/vividonly/article/details/50723852
https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization Quora 上的回答
http://freemind.pluskid.org/machine-learning/sparsity-and-some-basics-of-l1-regularization/
http://blog.csdn.net/zouxy09/article/details/24971995/
http://charlesx.top/2016/03/Regularized-Regression/ 正则化的 贝叶斯解释,另附详细的 MAP 计算PRML MLAPP(P432,P433)
http://blog.csdn.net/myprograminglife/article/details/43015835 对 mlapp 的翻译
http://www.di.ens.fr/~fbach/mlss08_fbach.pdf very nice ppt