概述
L1和L2正则项本质上是对参数进行先验分布假设,具体来说L1对应拉普拉斯先验,L2对应高斯先验。
ML与MAP的不同
maximum likelihood (ML) 极大似然估计:
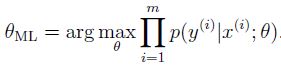
MAP (maximum a posterior) 最大后验概率估计:
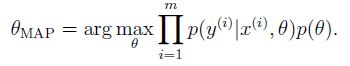
即 进行了先验假设。
拉普拉斯分布
L1正则化对应假设每个参数服从均值为0的拉普拉斯分布。
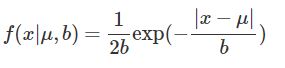
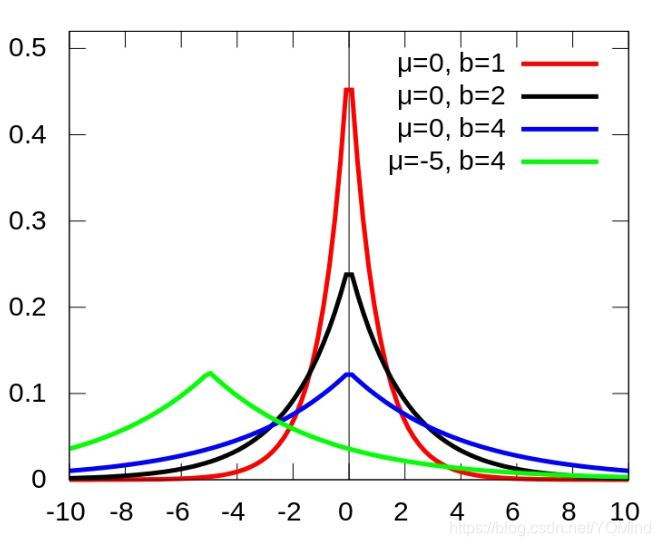
b越小,越陡。
L1和L2不同
L1更倾向于获得稀疏解,因此还可以用于特征选择
L2更倾向于解在0附近
理由:
从先验概率分布角度解释:
由上面的拉普拉斯分布图可以看出,拉普拉斯分布是尖尖的分布,而高斯分布较平缓。因此拉普拉斯分布比高斯分布更集中在0这个点上。
从梯度角度考虑
L1给予了更大的下降力度,从而更快收敛到稀疏点。
[1] https://www.cnblogs.com/dylan9/p/8716839.html
[2] https://zhuanlan.zhihu.com/p/50142573