作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121691734
目录
前言:
本文探讨在深度学习领域,对输入数据进行编码的几种方式。
OneHot、ASCII、词向量word2vec等。
1. 直接数值编码
1.1 概述
直接使用原始的数据格式作为神经网络的输入数据X和标签数据Y。如:


1.2 应用范围
(1)线性拟合
- 输入数据X
- 标签数据Y
(2)图像分类
- 输入数据X (像素值),如每张图片的输入数据三维RGB值(3*224*224)
2. 归一化与Normalize编码
2.1 概述
不改变原有数据的形状,值改变原有数据的数值范围。
(1)归一化:所有的数据都被等顺序地压缩到【0,1】之间。

(2)Normalize:所有数据都被等顺序的压缩到正态分布线上的点。

2.2 应用范围
用于消除梯度爆炸、大数吃小数、数值溢出等情形。
3. 索引编码
3.1 概述
不管原始对象是什么数据格式,如字符串或图片等,都把他们先编码成一个特定的索引值。
如cat,编码成10, dog编码成11等等。
然后把编码后的索引值作为神经网络的输入。
3.2 应用
完成采用这种编码的场合比较少,通常作为中间过渡,先把某个对象,按照种类进行分类,每个分类赋予一个index索引值,以示分开。
然后再对索引值进行进一步的编码,如onehot编码或词向量编码。
二次编码后的数据,才用于神经网络的预测和训练。
4. OneHot数字编码
4.1 概述
独热编码即 One-Hot 编码,又称一位有效编码。
其方法是使用 N位来表示 N个状态的编码。
每个状态都有它独立的状态位,并且在任意时候,其中只有一位有效。
(1)输入数据的oneHot编码

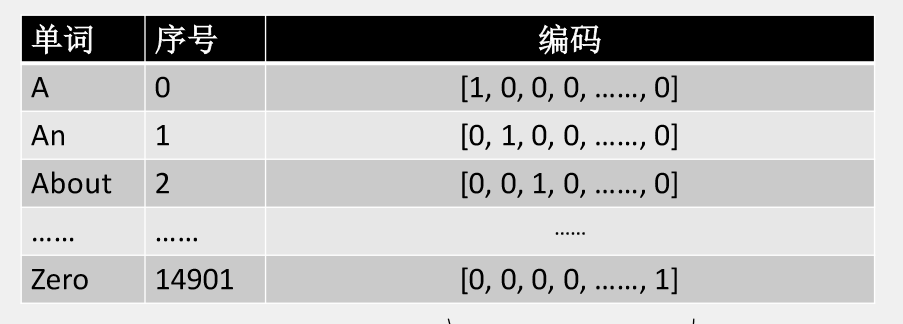
(2)分类标签的oneHot编码

这种情形,有多少种类就有多少bit的编码。
如10000种分类,就需要10000个bit存放一个对象的标签。
4.2 应用
这种方式,采用稀疏矩阵的方式存放数据,是比较浪费内存空间的。
主要应用于:每个输入对象之前是完全不相干的,每个对象之间,没有关联的,与输入顺序无关,是完全正交的场合。比如图片分类,就属于这种情形。
相邻的两张图片之间,没有任何语义上的关联。
5. ASCII编码
5.1 概述
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
这种方案,实际上先把字母按照顺序转换成索引index,然后对每个索引进行直接数值(0维)编码。
5.2 应用
主要应用对于英文字母(不是词)进行编码,每个字母的长度一个字节。

6. Unicode编码
6.1 概述
统一码,也叫万国码、单一码(Unicode)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
这种方案,实际上先把字母按照顺序转换成索引index,然后对每个索引进行直接数值(0维)编码。
unicode与ASCII原理是一样的,不同的是,它对所有国家的语言支持的基本“字”进行了统一索引编码。因此索引分类数量要远远大于ASCII编码的索引分类数量。

6.2 应用
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode用于多语言的编码,如汉字的编码,就可以采用unicode编码 。
7. 词向量编码:word2vec
7.1 概述

先对单词(有多个字母组成)进行分类,然后对分类后的单词进行编码。

由于单词与单词之间实际并不是完全独立的,比如Apple和Orange,这两个单词就是安全不相干的,而是都属于水果。
单词与图片的区别在于,词与词之间,并非完全独立,不相干,而是有一点的关联度,为了能够表达词与词之间的关联关系,就不能采用onehot编码了。
词向量编码,就是把一个个单词编码一个个索引值,然后把索引值编码成一个个一维的向量,每个一维向量的长度可以设定,通常在60~300之间。
常见的长度为300,即为长度为300的一维向量,或维度为1的300维度的向量, 与OneHot编码不同的是,每个数值是一个浮点数,这样每个单词就比编码成了形状为(1 * 300)的特征数据。
这个特征数据,唯一的标识了一个单词。比如有100万个单词,就有100万个不同的特征向量。
7.2 词向量的多维空间
如下是多维词向量空间的示意图:

从上图可以看出,不同的词,处于多维空间的不同的位置:
有些词,在多维空间中的综合距离相近,
有些词,在多维空间中的综合距离相差甚远。
有些词,在某些维度相差较近,如水果Apply与Apply公司,输入相同
有些词,在某些维度相差远,如水果Apply与Apply公司,语义完全不同。
7.3 词向量编码的好处
为什么采用词向量编码呢? 以100万个单词为例,这样的编码的好处:
(1)只用了300个维度的特征值(而不是OneHot的100万个位的数据),就可以标识无穷多的单词,相对于OneHot编码,节省了大量的内存空间。
(2)可以通过余弦距离获取两个单词词向量的关联程度。
如果两个单词,完全无关,则这两个单词的词向量的余弦距离为1.
如果两个单词,完全一样,则这两个单词的词向量的余弦距离为0.
两个单词的距离越小,则他们的相似度越高,关联性越大。
两个单词的距离越大,则他们的相似度越小,关联性越小。


7.4 词向量的热度图

热度图:展现的是,每个词的每个维度的数据值,通过颜色的方式展现出来。
然后通过观察两个向量颜色,来只管的比较两个单词的相似度。

从上图可以看出,man和boy在热度图上有很多一致的向量值,反应的是这两个词的相似度很高。
而water与boy的相似性就比较少。
7.5 词向量编码的实现
词向量的难点是:
(1)如何指派各个词向量每个维度的数值,(2)且要确保相似度相近的词的词向量的距离相对较小。
如果少量的词,如几十个,通过人工的方式来排列或指定是可以做到的,然而,如果词的数量高达几十万个,再通过人工的方式来厘清词与词的关系以及通过特定的词向量来体现,就不太可行了。
因此,每个单词的词向量的编码值,并非人为设定的,而是通过分析大量的文章,进行机器自动学习获得的。
后续会阐述,如何通过机器学习,从大量的文本数据中,学习各个单词的词向量。
7.6 应用
在自然语言处理中,为每个单词进行编码。单词与单词之间构成某种关联。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121691734