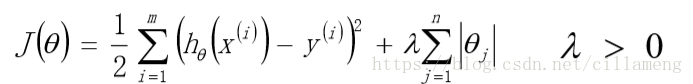1、什么是过拟合、欠拟合(图示法)
二者均是指在训练集上的表现
训练集的预测值,完全贴合训练集的真实值,称之为过拟合;
训练集的预测值,与训练集的真实值有不少的误差,称之为欠拟合;
如图示:
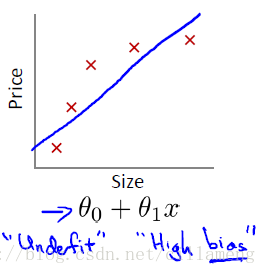
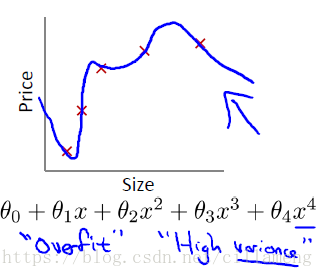
图片链子博客:https://blog.csdn.net/u011630575/article/details/71158656
2、如何评价是否是欠拟合、过拟合?(后续写)
3、如何解决
欠拟合:
根本原因:特征维度较少,导致拟合的函数无法满足训练集
导致的结果:训练集误差较大
解决办法:增加特征维度,进行多项式的扩展;使用集成学习方法(adaboost/xgboost);
过拟合:
根本原因:特征维度过多,导致拟合的函数,完美的匹配训练集;或者训练样本单一,样本不足;样本噪声干扰过大;
导致的结果:对新数据的预测结果较差
解决办法:1:减少特征维度;2:保留所有的特征,通过降低参数w的值,影响模型;3:增加训练数据集的大小;4;使用集成学习方法(随机森林)
4、解决办法在算法中的应用
针对欠拟合:
在pipeline的 PolynomialFeatures中设置模型采用几次多项式进行预测
针对过拟合:
线性回归中,通过引入不同的正则项(降低了参数W)形成了岭回归算法和lasso回归算法:
岭回归:
引用块内容
lasso回归: