某房地产网站数据分析纲要
一、某房地产网站数据分析-数据采集
二、某房地产网站数据分析-可视化
三、某房地产网站数据分析-数据分析
某房地产网站数据分析-数据采集
一、背景
二、反爬技术
三、项目代码介绍
一、背景
市场背景
2020年年初开端就因为疫情大部分产业都被迫停工休息,虽说对于房价而言,这几乎并不会影响很大,但具体情况需要通过数据来说话,这里最为重要的就是数据的获取上,如何才能在大数据时代,信息时代中走在前面,对于个人来说,房价水涨船高,怎么样去洞察地区的房价行情,减少买房时候的坑;对于房地产来说,如何才能合理分析市场的变化趋势,进一步的对房地产市场的把控,这都需要所用到的数据,并且对数据进行科学的分析,通过数据真实的反应客观的市场,客户的喜好。
个人背景
开始爬取该项目其实是面试的时候的笔试考核,但很不幸算是不通过,因为中途其他时间耽搁,也没有足够时间去做,毕竟是远程,但也是为了自己以后可以在缩短时间去完成这类题目,项目基于Python编程,仅供学习。
二、反爬技术
项目中爬取的网站为房天下,这里需要了解到的一个名称就是重定向,学过对应的编程语法的应该都了解,在这里可以简单理解为页面跳转,在进入分类筛选前,对页面的请求是可以正常请求,但进入分类筛选后,通过get获取到的数据并不能得到我们所需要的信息,通过抓包可以看到。
1 <div class="redirect" style="padding-top: 40px;"> 2 <p class="info" style="font-size: 18pt; margin-bottom: 8px;">自动跳转中<span class="second"></span>s...</p> 3 <a class="btn-redir" style="font-size: 14pt;" href="https://sz.esf.fang.com/housing/85__1_0_0_0_1_0_0_0/?rfss=1-9e9436b2bcaf98402e-7a">点击跳转</a> 4 </div>
所以这里需要进行解析处理一下,原本的URL,可以通过xpath或者find等获取重定向URL。
1 def get_url(old_url): 2 3 '''获得正确的url''' 4 5 r = requests.get(url=old_url, headers=headers) 6 7 if r'<title>跳转...</title>' in r.text: 8 9 soup = BeautifulSoup(r.text, 'lxml') 10 11 new_url = soup.find(name='a', class_= 12 'btn-redir'}).attrs['href'] 13 14 return new_url 15 16 return old_url
三、项目代码介绍
项目中使用的几乎大部分为BeautifulSoup和request两个库,所以语法中普遍使用为find、select这些bs4的查询进行html查找,甚至有用到正则匹配进行查找,数据为了后续使用pandas,采用了列表嵌套字典的保存方式。简单的讲一下find中的使用结合房天下html,以深圳福田住宅区二手房为例子。
全部小区的信息都包含在class="houseList"中,每一个id="houselist_B09_01"代表一个小区的信息,在其中的a标签中href属性就是该小区的链接,需要字符串拼接添加“https:”来得到完整的链接

1 try: 2 3 r = requests.get(url=true_url, headers=headers) 4 5 except: 6 7 time.sleep(3) 8 9 r = requests.get(url=true_url, headers=headers) 10 11 soup = BeautifulSoup(r.text, 'lxml') 12 13 house_num = len(soup.find_all('div',dataflag='bgcomare')) 14 15 for i in range(1, house_num): 16 17 if i < 10: 18 19 i = "0" + str(i) 20 21 reg_url.append('https:'+soup.find('div', id='houselist_B09_' + str(i)).find('a')['href'])
house_num其实是获取在当前页数中存在的小区数量,并且进行获取对应的小区URL进行拼接得到需要的完整URL,可以观察到对应的每一个都有个前缀是'houselist_B09_',根据筛选不同可能会不一样,需要自己查看一下。
同理,进入小区详细页面后可以看到对应的信息大部分都存在“小区详情”中,而且页面也是重定向,还是熟悉的配方熟悉的方法,但这里有个小坑,绝大部分小区详情的URL和原来URL是多了个字符串'/xiangqing/',但多看几个以及后面页数的时候你会发现,其实有写穿插了其他的字符串进去比如’/2/’或者’/ef/’方法还是一样的。

1 def get_house_deep_url(old_url): 2 3 '''获得小区的详请URL''' 4 5 # old_url ='https://doushihuayuan.fang.com/' 6 7 true_url = get_true_url(old_url) 8 9 r = requests.get(url=true_url, headers=headers,proxies=proxies) 10 11 r.encoding = 'gb2312' 12 13 soup = BeautifulSoup(r.text, 'lxml') 14 15 deep_url = 'https:' + soup.find('li',id='kesfxqxq_A01_03_01').a['href'] 16 17 #print(deep_url) 18 19 #print(type(deep_url)) 20 21 return deep_url
最后关于对应信息的获取,因为做法都一样,所以只说一个其他都依葫芦画瓢即可:
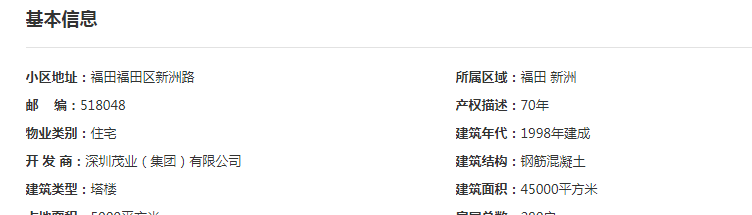

1 r = requests.get(url=true_url, headers=headers,proxies=proxies) 2 3 time.sleep(3) 4 5 r.encoding = 'gb2312' 6 7 soup = BeautifulSoup(r.text, 'lxml') 8 House_info = soup.find('div', class_='inforwrap clearfix').find_all('dd') 9 for item in House_info: 10 11 if item.find('strong').get_text() == '小区地址:': 12 13 address = item.get('title') 14 15 House_dict['小区地址']=address 16 17 House_list.append(address) 18 19 #print(address)
最后附上代码模块的说明
1 #!/urs/bin/env python 2 3 # -*- conding: utf-8 -*- 4 5 # @Author : Senci 6 7 # @Time : 2020/3/6 14:45 8 9 # @File : house-data.py 10 11 12 13 代码功能模块说明: 14 15 main--------------主要入口函数 16 17 | ---------------return--------运行完成结束程序 18 19 ip_proxy----------检查代理get_ip返回ip是否正常 20 21 | ---------------return----proxies,代理ip字典{'http': proxy_ip} 22 23 | ----ip_num,ip更换个数 24 25 | ----Error004_status,是否为044异常代码,决定是否提前关闭程序 26 27 get_num-----------获取页数 28 29 | ---------------return-----pag_num,页数,int格式 30 31 getUrls-----------获取小区详细URL 32 33 | ---------------return-----reg_url_list,所有小区的URL,list格式 34 35 get_house_info----获取小区的详细信息 36 37 | ---------------return-----House_All,返回一个小区的所有信息,字典格式,详细格式见下方 38 39 get_deep_url------获得小区的详请URL 40 41 | ---------------return-----deep_url, 小区的详请的URL 42 43 dic2pd------------数据转换为pandas 44 45 | ---------------return-----House_DF,所有数据的dataframe数据格式 46 47 pd2csv------------存储csv文件 48 49 | ---------------return-----没有返回参数或变量,生成CSV文件 50 51 run_log-----------日志生成 52 53 | ---------------return-----没有返回参数或变量,生成txt文件 54 55 get_true_url------url重定向解析 56 57 | ---------------return-----获得解析后的新url 58 59 get_map_info------地图地理位置获取 60 61 | ---------------return-----map_info,列表,包含x,y两个维度 62 63 64 65 ==================================================================================== 66 67 main.file_name 交互部分,保存测CSV文件名称,保存到当前路径 68 69 get_num.true_url 为需要爬取网站的原始url,例如:https://sz.esf.fang.com/housing/85__1_0_0_0_1_0_0_0/ 70 71 getUrls.url 为规则匹配的url格式,可以根据需要修改,这里为福田区,住宅选项 72 73 main.pag_num 为爬取页数,可以认为赋值,也可以不修改 74 75 ==================================================================================== 76 77 House_All = { 78 79 'url':'空', 80 81 '小区名称': '空', 82 83 '别名':'空', 84 85 '本月均价':'空', 86 87 '小区地址':'空', 88 89 '行政区': '空', 90 91 '片区': '空', 92 93 '邮编': '空', 94 95 '产权描述': '空', 96 97 '物业类别': '空', 98 99 '建筑年代': '空', 100 101 '开发商': '空', 102 103 '建筑类型': '空', 104 105 '建筑面积': '空', 106 107 '占地面积': '空', 108 109 '房屋总数': '空', 110 111 '楼栋总数': '空', 112 113 '绿化率': '空', 114 115 '容积率': '空', 116 117 '物业费': '空', 118 119 '停车位': '空', 120 121 '交通状况': '空', 122 123 '周边信息': '空', 124 125 '地理位置': '空', 126 127 '更新时间': '空' 128 129 } 130 131 ====================================================================================