缺失值处理方法汇总
本文链接:https://blog.csdn.net/weixin_47058355/article/details/128866686
前言
看了下网络上做完整的数据清洗方法总结的人不多,这几年刚好学的各类方法都有点杂乱,因此自己做个总结,算是方便自己,也帮助别人,也希望大家看到错误,能在评论区或者私信说一下,互相探讨学习一下。
一、查看缺失值比例
常见的查看缺失值方法,第一种计算缺失值比例
queshi_bili=((data_train.isnull().sum())/data_train.shape[0]).sort_values(ascending=False).map(lambda x:"{:.2%}".format(x)) #queshibili是数据名 data_train是训练集数据
queshi_bili

第二种是使用describe()函数
data_train.describe()

二、基于统计的缺失值处理方法
缺失值的处理方法我一般分为两种,一种是基于统计学的填补方法,另外一种是基于机器学习的填补方法。
后续以data_train当中的 其他流动资产这个特征为例
2.1 删除
一些缺失值比例过大的数据还是需要将其删除的,缺失值填补也仅仅只是基于当前数据进行预测,计算的,存在一定误差。但填补的数据过多,反而只会带来误差。
del data['列名']

按照比例进行删除,这里是按照80%的比例进行删除
t = int(0.8*data_train.shape[0]) # 确定删除的比例下,占数据多少
data_train_shanchu = data_train.dropna(thresh=t,axis=1)#保留至少有 t 个非空的列
data_train_shanchu

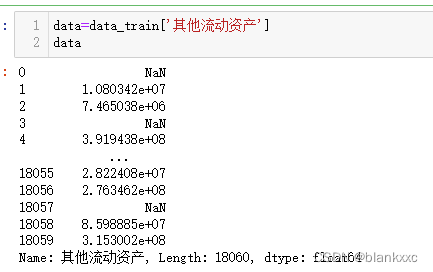
2.2 填充固定值
将缺失值都填充为给定常数
data.fillna(0, inplace=True) # 填充 0 第一个参数控制填充的常数
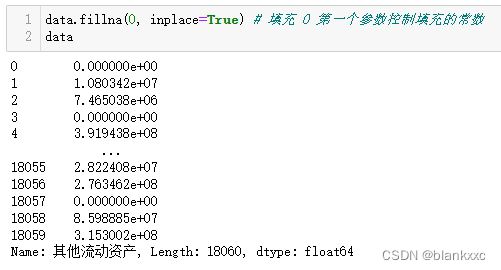
也可以通过字典的形式,进行固定值填充,所给字典不够填充的,就还是处于缺失值状态
data.fillna({
0:1000, 1:100, 2:0, 4:5})
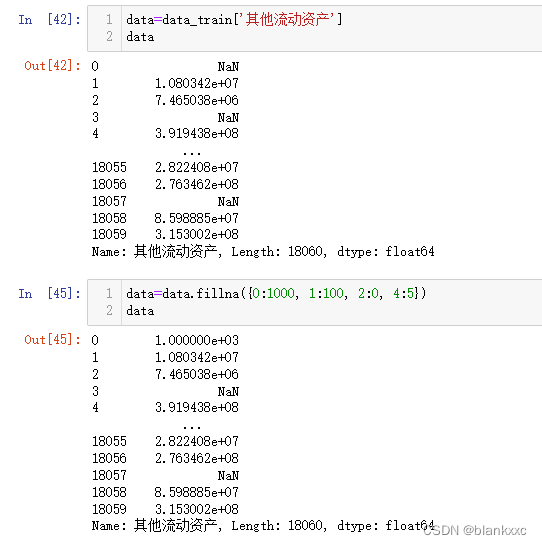
2.3 填充中位数、平均数、众数
这三个数代码相近,只需要将函数改为其他的即可。图片是以平均数填充为例
data.fillna(data.mean(),inplace=True) # 填充均值
data.fillna(data.median(),inplace=True) # 填充中位数
data.fillna(data.mode(),inplace=True) # 填充众数
2.4 插值法填充,前值或者后值填充
插值法原理是将缺失值的数据的上下两个数据相加除以2,也就是取平均,缺点是如果前面没有值和后面没有值,都将会导致缺失值依然存在。
data = data.interpolate()#上下两个数据的均值进
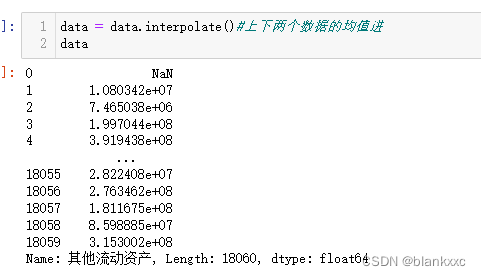
填充前面值或者后面值,填充缺失值的上一个数据或者下一个数据,缺点与插值法相同,缺点是如果前面没有值和后面没有值,都将会导致缺失值依然存在。(图片以前值为例)
data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值

三、基于机器学习的缺失值填充
采用的机器学习算法对于缺失值进行填充,从精度上是优于统计方法的填充,但是相对的需要付出的算力和时间是远远大于统计方法的。
这里仅仅对代码实现作为一个演示,其中的算法原理,可以自行搜索。
3.1 基于knn算法进行填充
from fancyimpute import KNN
data_train_knn = pd.DataFrame(KNN(k=6).fit_transform(data_train_shanchu)#这里的6是对周围6个数据进行欧式距离计算,得出缺失值的结果,可以自行调整
columns=data_train_shanchu.columns)
data_train_knn
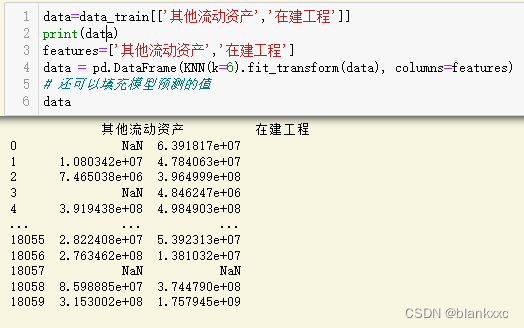
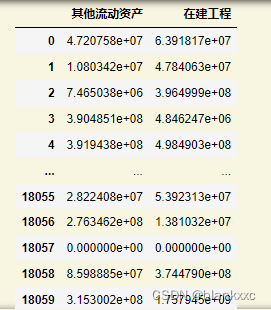
3.2 基于随机森林进行填充
使用随机森林进行缺失值填补,其他像lightgbm,xgboost都是可行的,这里以随机森林为例子
操作就是将其他特征作为数据 然后对缺失的数据进行填补,得到缺失值
from sklearn.ensemble import RandomForestRegressor
#利用随机森林树进行填补缺失值
train_data = train_data[['其他流动资产', '货币资金', '资产总计']]
df_notnull = train_data.loc[(train_data['其他流动资产'].notnull())]
df_isnull = train_data.loc[(train_data['其他流动资产'].isnull())]
X = df_notnull.values[:,1:]
Y = df_notnull.values[:,0]
# use RandomForestRegression to train data
RFR = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
RFR.fit(X,Y)
predict = RFR.predict(df_isnull.values[:,1:])
predict

总结
大概目前的话,常用的缺失值处理方法就这些,后续的话我会接着更新其他的数据清洗的方法。我就不设置付费专栏啦,希望对各位有帮助!