近期学了下python爬虫,利用requests模块爬取了妹子图上的图片,给单身狗们发波福利,哈哈!顺便记录一下第一次发博客。
话不多说,进入正题
- 开发环境
- python 3.6
- 涉及到的库
- requests
- lxml
先上一波爬取的截图

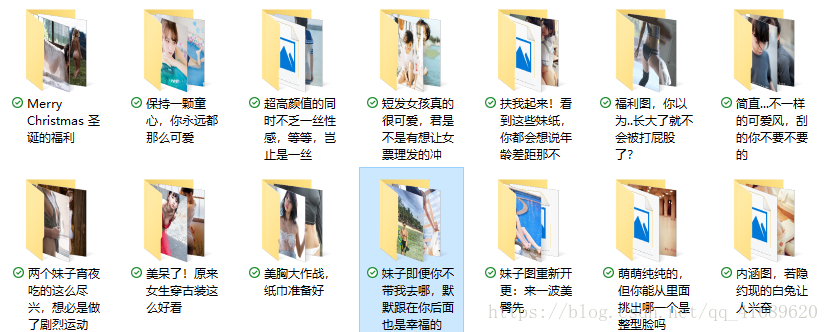
网站首页
每一页有很多个系列,每个系列有10张图左右,爬虫程序以图片写的文字为目录,存储每张图片
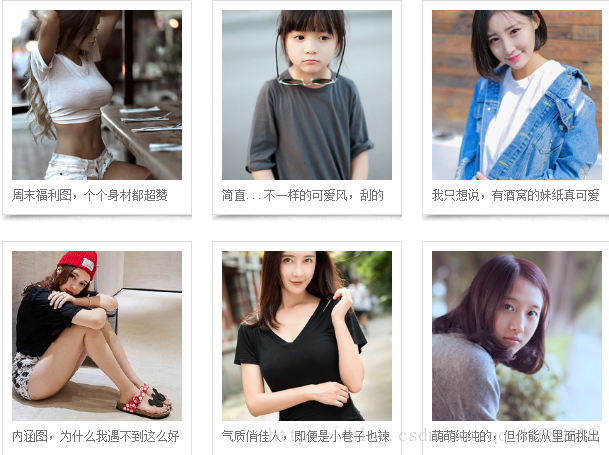
图片爬取
- 获取网页链接(url)
第一页链接的地址为:http://www.meizitu.com/a/more_1.html,通过观察发现,第二页的链接地址只需要将数字1改为2即可 - 获取每个分类下每张图片的链接地址
xpath表达式是爬虫常用的一个工具,通过request模块获取的内容需要利用lxml模块下的etree方法才可以通过xpath表达式提取内容
图片的链接提取表达式为:
li_list = html.xpath("//ul[contains(@class, 'wp-list')]/li")
img_url = li.xpath(".//a/@href")[0] if len(li.xpath(".//a/@href"))>0 else None- 提取图片内容并保存
得到每张图片的链接地址以后,通过requests模块获取图片内容并保存
for i in range(len(img_list)):
file_path = "./imgs/"+img_tag+"/"+str(i)+".jpg"
print(file_path)
print("开始保存图片{}\n".format(i), img_list[i])
with open(file_path, "wb") as f:
f.write(requests.get(img_list[i],headers=self.headers, timeout=10).content)
print("保存成功!")由于每一页的图片比较多,提取一页已经足够,通过参数page_num可以设定要爬去的页数
图片为二进制文件,保存图片的方法为:
for i in range(len(img_list)):
file_path = "./imgs/"+img_tag+"/"+str(i)+".jpg"
print(file_path)
print("开始保存图片{}\n".format(i), img_list[i])
with open(file_path, "wb") as f:
f.write(requests.get(img_list[i],headers=self.headers, timeout=10).content)
print("保存成功!")程序运行的效果
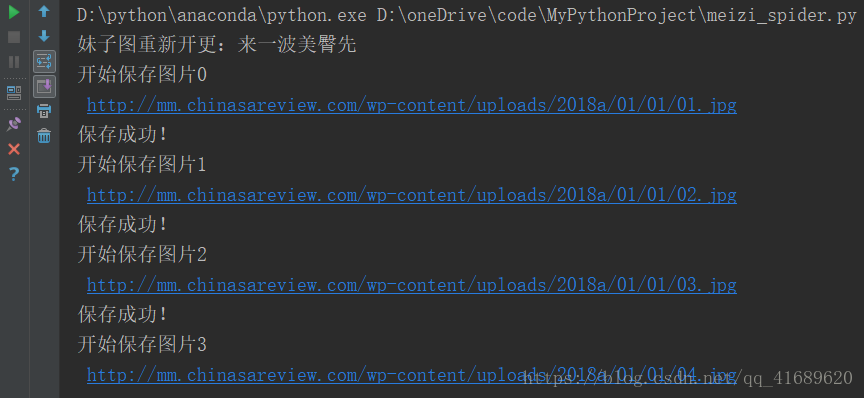
最后附上源代码
# -*- coding: utf-8 -*-
"""
--------------------------------------------------------
# @Version : python3.6
# @Author : wangTongGen
# @File : meizi_spider.py
# @Software: PyCharm
# @Time : 2018/8/19 18:32
--------------------------------------------------------
# @Description:this is programed to spider mei_zi_tu
--------------------------------------------------------
"""
import os
import requests
from lxml import etree
class MeiZiSpider(object):
# 初始化函数
def __init__(self, page_num):
self.page_num = page_num #定义要爬取的网页数
self.start_url = "http://www.meizitu.com/a/more_{}.html" #爬虫的起始地址
#添加请求头,模拟浏览器访问
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"}
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
# 获取爬虫网页列表
def get_url_list(self):
return [self.start_url.format(i+1) for i in range(self.page_num)]
# 获取response并转化为xpath表达式可以解析的格式
def parse_url(self, url):
html_str = requests.get(url, headers=self.headers).content.decode("gbk")
html = etree.HTML(html_str)
return html
# 获得每个分类下每张图片的url
def get_img_url_list(self, html):
li_list = html.xpath("//ul[contains(@class, 'wp-list')]/li")
for li in li_list:
img_tag = li.xpath(".//b/text()")[0] if len(li.xpath(".//b/text()"))>0 else None
if img_tag is None:
img_tag = li.xpath(".//a/text()")[0]
detail_url = li.xpath(".//a/@href")[0] if len(li.xpath(".//a/@href"))>0 else None
if detail_url is not None:
print(img_tag)
if not os.path.exists("./imgs/" + img_tag):
os.mkdir("./imgs/" + img_tag)
self.parse_detail(detail_url, img_tag)
# 利用每张图片的url获得图片并保存到本地
def parse_detail(self, detail_url, img_tag):
html = self.parse_url(detail_url)
img_list = html.xpath("//div[@id='picture']/p/img/@src")
for i in range(len(img_list)):
file_path = "./imgs/"+img_tag+"/"+str(i)+".jpg"
print("开始保存图片{}\n".format(i), img_list[i])
with open(file_path, "wb") as f:
f.write(requests.get(img_list[i],headers=self.headers, timeout=10).content)
print("保存成功!")
# 爬虫主函数
def run_spider(self):
# 获取url列表
url_list = self.get_url_list()
# 逐次爬取
for url in url_list:
html_str = self.parse_url(url)
self.get_img_url_list(html_str)
if __name__ == '__main__':
# 定义要爬取的页面数(1--71)
page_num = 1
# 构造一个爬虫对象
mei_zi = MeiZiSpider(page_num)
# 运行爬虫
mei_zi.run_spider()