本文章介绍的主要内容是在网页中搜寻到对应模块的参数值,以下将介绍利用BeautifulSoup来查询一个网站的访问量。
首先需要安装BeautifulSoup模块,我用的是Anaconda,已经附带安装了包括BeatifulSoup在内的第三方库。可以在.../Anaconda3/pkgs 文件夹中查看此模块的详细信息。
此外,需要对HTML语言有一定的了解。在此不做介绍。
以下是代码的实现:
----------------------
from bs4 import BeautifulSoup
from urllib import request
import re
res=request.urlopen("https://blog.csdn.net/qq_33810188")
soup=BeautifulSoup(res,"html.parser")
ullist=soup.findAll("div",attrs={"class":"grade-box clearfix"})
ullist1=soup.findAll("dd",attrs={"title":True})
ullist_rank=soup.findAll("dl",attrs={"title":True})
n=0
print(soup.title.string)
for index in ullist1:
n=n+1
uu=index.children
for child in uu:
if n==1:
print("访问量:",child)
if n==2:
print("积分值:",child)
n=0
for index in ullist_rank:
chil=index.children
for child in chil:
n=n+1
if n==24:
print("排名:",child.string)
----------------------
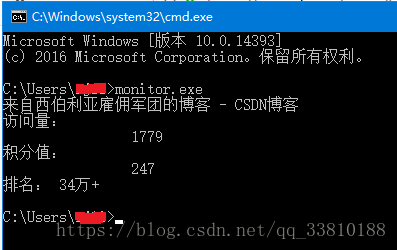
测试效果如下:

代码具体的实现原理,需要对HTML语言和BeautifulSoup有一定的了解。
例如下图,整个结构体在<div ..> ... </div>中,可以通过 div 和 class 进行检索

同理,内部的内容也可以通过不同的标签进行检索。
ullist_rank=soup.findAll("dl",attrs={"title":True}) 中True表示所有合法的语法,这样就可以不用固定title的值(title中的值有时可能是变量,例如<dd title="1751">中 1751 是一个变量,不利于检索)。

后续如果想将其打包成可执行文件exe,可以用pyinstaller模块,此模块需要安装,同样地,在cmd窗口输入 pip install Pyinstaller
安装完成后,可以用 pyinstaller --version 查看安装的版本。
此后,可以将cmd路径更改到需要进行打包的文件夹中,直接输入 pyinstaller *****.py,即可进行打包,完成后,在对应的子文件夹中可以生成exe文件,如下:
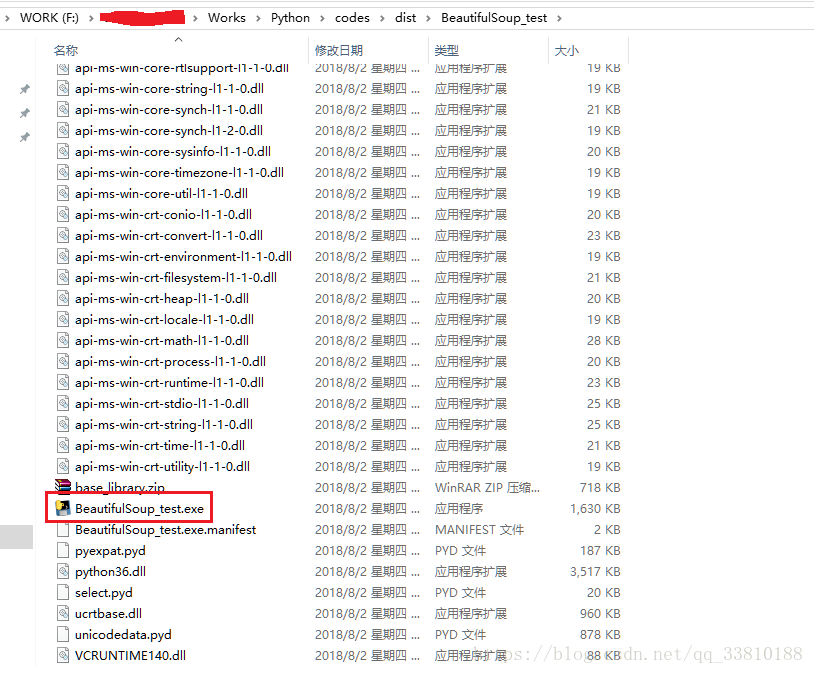
此exe文件同样可以利用cmd窗口运行(需要将文件夹路径加入系统环境Path中)