"JGR-P2O: Joint Graph Reasoning based Pixel-to-Offset Prediction Network for 3D Hand Pose Estimation from a Single Depth Image"论文解析
论文链接:https://linkspringer.53yu.com/chapter/10.1007/978-3-030-58539-6_8
论文代码:https://github.com/fanglinpu/JGR-P2O
论文出处:ECCV2020
摘要
-
基于单目深度图像的SOAT的hand pose estimation方法都是基于密集预测(dense predictions)的,包括:立体像素到立体像素的预测(voxel-to-voxel predictions),点到点的回归(point-to-point regression),像素级的估计(pixel-wise estimations)。这些方法存在精度和效率之间的权衡问题。
-
本文针对单深度图的3D hand pose estimation问题,提出了一种基于像素预测的新方法。
-
主要思想有两个方面:
a)明确建模关节之间的依赖关系和像素与关节之间的关系,以更好地进行局部特征表示学习;
b)统一密集像素级偏移预测和直接联合回归端到端训练。 -
具体方法:
a) 首先提出了一个基于联合图推理模块的图卷积网络(GCN),对节点之间的复杂依赖关系进行建模,增强每个像素的表示能力。
b)然后,我们在图像平面和深度空间密集估计所有像素到关节的偏移量,并根据所有像素的预测结果加权平均计算关节位置,完全放弃了复杂的后处理操作。 -
提出的模型是在2D fully convolutional network (FCN)的backbone上实施的,仅有1.4M的参数。
-
在多个3D手姿估计基准上的广泛实验表明,本文提出的方法在单个NVIDIA 1080Ti GPU上以110帧/秒的速度高效运行的同时,获得了SOAT的精确度。
1. 简介
- 性能最好的基于深度学习的方法是基于检测( detection-based)的方法,它将三维手姿参数作为体积热图或扩展的3D热图与偏移向量场一起制定,并使用完全卷积网络(FCNs)或PointNet以密集预测的方式估计它们。
- 与直接将深度图像映射到3D手部姿势参数并严重遭受高度非线性映射问题的基于回归(regression-based )的对应方法相反,基于检测的方法可以通过位姿重参数化学习到更好的特征表示,已被证明对人体位姿估计和手部位姿估计都更有效。
- 我们提出了一种新的基于联合图推理的像素-偏移量预测网络(JGR-P2O),旨在从单一深度图像中直接回归关节位置。
- 具体来说,我们将三维手姿分解为关节的二维图像平面坐标和深度值,并对这些参数进行集成估计,充分利用了深度图像的2.5D特性。
- 该方法由两个关键模块组成:基于gcn的联合图推理模块和像素偏置预测模块。
- 联合图推理模块的目的是为每个像素学习更好的特征表示,这对密集预测至关重要。首先,对局部特征编码的全局信息进行汇总,生成关节特征;其次,通过图推理对关节间的依赖关系进行建模,获得更强的关节特征表示;最后,将进化节点的特征映射回局部特征,从而增强局部特征表示。
- 像素-偏移量预测模块密集估计图像平面和深度空间中所有像素到关节的偏移量。通过对所有像素预测的加权平均,计算出关节在图像平面空间和深度空间中的位置。
- 它可以产生中等密度的偏移向量场,也可以在关节位置的直接监督下进行完全的端到端训练,充分分享基于检测和基于回归的方法的优点。
- 本文的贡献和创新点:
(1)提出了一个端到端可训练像素-偏移量(pixel-to-offset)模块。利用深度图像的2.5D特性统一了密集像素级偏移预测和直接联合回归。
(2)提出了一个基于gcn的联合图推理模块,以显式建模关节之间的依赖关系和像素与关节之间的关系,以增强局部特征表示。
(3)我们对多种最常见的3D手姿估计基准进行了广泛的实验(ICVL, NYU , MSRA)。果表明,所提出的方法在仅约1.4M参数的情况下,在单个NVIDIA 1080Ti GPU上以110帧/秒的速度非常高效地运行,从而达到了新的最先进的精度。
2. Related work
2.1 基于回归的方法(Regression-based Methods)
- 基于回归的方法旨在直接回归三维手姿参数,如三维坐标或关节角度。
2.2 基于检测的方法(Detection-based Methods)
- 基于检测的方法通过为每个关节设置热图,实现密集的局部预测。
- 早期研究首先根据估计的二维热图检测关节在二维平面上的位置,然后通过复杂优化的后处理将其转换为三维坐标。
- 最近的研究直接从三维热图中检测三维关节位置,后处理更加简单。
2.3 分层和结构化方法(Hierarchical and Structured Methods)
- 这些方法旨在将手部相关性或构成约束纳入模型。层次化方法将手部关节划分为不同的子集,利用不同的网络分支提取每个子集的局部位姿特征。
- 结构化方法将手部的物理运动约束加到模型中,通过在CNN模型中嵌入约束层或者在loss函数中加入特定的约束来实现。
3. 方法介绍
3.1 Overview
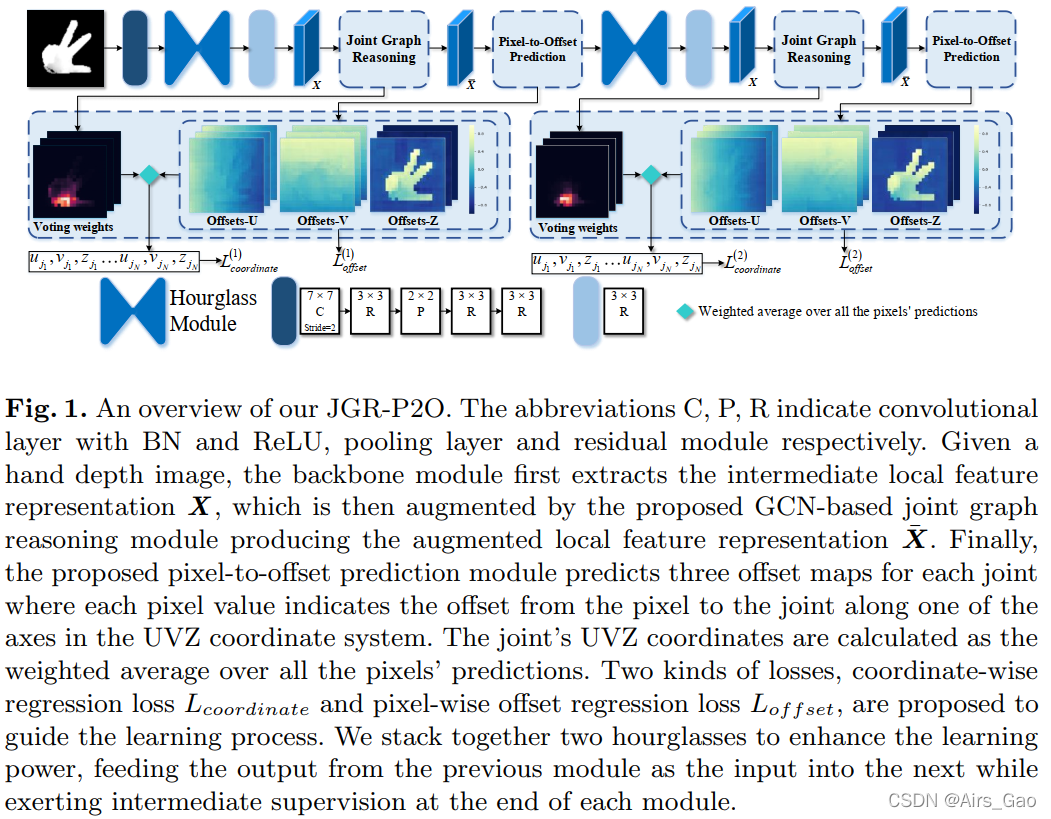
- 本文提出的JGR-P2O方法将三维手姿估计问题转化为密集像素到偏移量的预测,充分利用了深度图像的2.5D特性。
- 以深度图像为输入,输出图像中关节的位置(即uv坐标)和深度空间(即z坐标)。
- 如图1所示,使用高效的hourglass network作为骨干提取中间局部特征表示。然后,提出的joint graph reasoning module对关节之间的依赖关系和像素与关节之间的关系进行建模,增强了中间局部特征的表示。最后,pixel-to-offset module估计像素到关节的偏移量,并将所有像素的预测集合起来,得到最终关节的位置。
- 我们将两个沙漏叠加在一起,以增强学习能力,将前一个模块的输出作为输入输入到下一个模块,并在每个模块的最后发挥中间监督作用。