如今spark特别火,相信作为程序员的你也难以抵挡spark的魅力,俗话说万事开头难,学习spark需要一些准备工作,首先就是要搭建学习测试环境,spark非常人性化,一个简单的测试环境,只需要下载安装包,解压之后,运行spark_shell脚本就可以学习测试了,spark测试的经典页面如下图:
这样就以本地模式启动了spark,可以进行学习了。如果有条件,可以搭建一个集群,建议用docker来搭建,方便省时间。闲话就不多说了,直接进入主题。
RDD特征
想要入门spark,最重要的就是理解RDD的概念,RDD叫做弹性分布式数据集,是spark中核心的数据模型,spark的所有操作都是围绕RDD进行的。RDD有两个关键特点:
1)数据被分区
因为在大数据处理场景中,一份数据的一般很大,为了能够并行计算,需要把数据分区存储,就是把数据分散存储在多个节点上,RDD会保存数据分区信息,以便处理数据,每个RDD有个方法partitions,可以获取分区信息。在shell中,我加载本地一个文件val RDD = sc.textFile("file:///Users/test/Documents/test"),如下图所示会看到该文件加载到spark中有两个分区。意思这份数据被分成两个分区,来做并行计算。

2)RDD依赖性:
spark中主要处理过程是RDD的转化过程,怎么理解依赖性,假如RDD1通过某种计算(map,groupByKey)转换为RDD2,那么就认为RDD2依赖RDD1,在spark中依赖关系分为两种,一种是窄依赖,一种是宽依赖也叫shuffle 依赖。债依赖是一个子RDD只能有一个父RDD,宽依赖是一个子RDD有多个父RDD,我用图说明依赖关系。
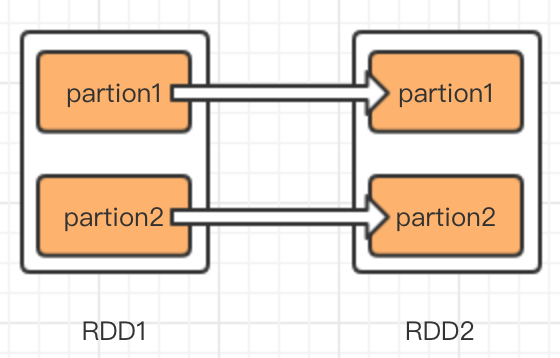
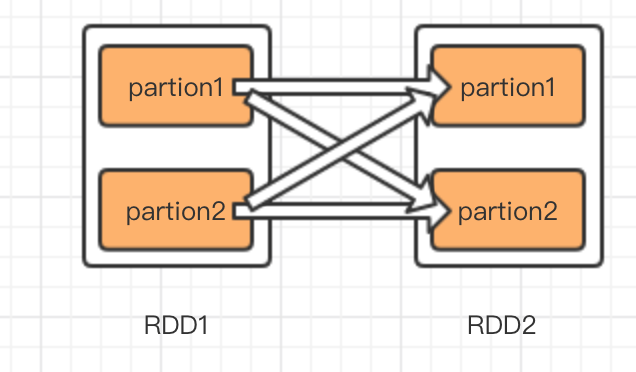
左图是窄依赖,右图是宽依赖,比如map就是一种窄依赖,特点是RDD转换分区之间互不影响,即使有一个转换失败了,也不影响其他转换,只需要恢复故障转换过程即可。而groupByKey就是一种宽依赖,如图右图,RDD2的partition1的生成,需要RDD1的partition1和partition2同时贡献数据,如果其中有哪一步partion转换失败了,那么整个转换过程需要重新执行。另外一点区别是,窄依赖的转换可以在集群的一个节点中完成,免去IO开销,而宽依赖的数据,来自所有的父partition,这就可能产生大量IO,所以宽依赖比窄依赖更加耗费资源。我在shell中执行val RDD1 = RDD.map(x=>x.split(",")),然后看RDD1的依赖属性,如下图依赖类型为OneToOneDependency,字面意思为1对1依赖。

而我在shell中执行,val RDD2 = RDD.flatMap(x=>x.split(",")).map(x=>(x,1)).groupByKey() ,这时再看RDD2的依赖属性,如下图:

可以看到,RDD2的依赖属性是ShuffleDependency,指宽依赖,因为GroupByKey需要依赖于父RDD的所有分区。
RDD转换和动作
在清楚的RDD的特征之后,RDD的转换和动作也就相对于好理解了,转换即RDD到RDD之间的计算过程,比如map,flatMap等等,转换的特点是执行转换的代码,并不立刻进行转换,一直到最后一步动作发生的时候,才会真正执行转换。动作(Aciton),就是获取最后的结果,就想一条指令一样,发射出去,引发整个过程的运转。比如irst(),take(),collect(),这些都是动作。一旦这些动作执行之后,才会引发真个过程的发生。没什么好讲的,在明白了spark中,最核心的数据模型RDD之后,那么围绕RDD可以立刻写出一个helloworld,单词计数。
第一步:加载数据,生成第一份RDD。
val wordLine = sc.textFile("file:///Users/test/README.md");
查看分区数:wordLine.partitions.length =2
第二步:生成窄依赖words,进行map转换
val words = wordLine.flatMap(x => x.split());
查看分区数:words.partitions.length=2 证明是一对一转换,数据变化为单词组成的数据
第三步:生成窄依赖wordsTuple,增加每个单词的计数,
val wordTuple = words.map(x => (x,1));
查看分区数:wordTyple.partitions.length=2证明是一对一转换,数据变化为(单词,数量)组成的数据,但这个数据还没有做累加
第四步:生成宽依赖wordCounts,累加每个元组
val wordCounts = wordTuple.reduceByKey((x,y)=>x+y)
第五步:发生动作(action),保存文件
wordCount.saveAsTextFile("file:///test/result");
查看保存的文件内容:
part-00000 和 part-00001是两个分区的数据,保存成的文件。可以用命令保存成一个,默认情况是结果有多少分区就保存多少个。
文件内容如下:
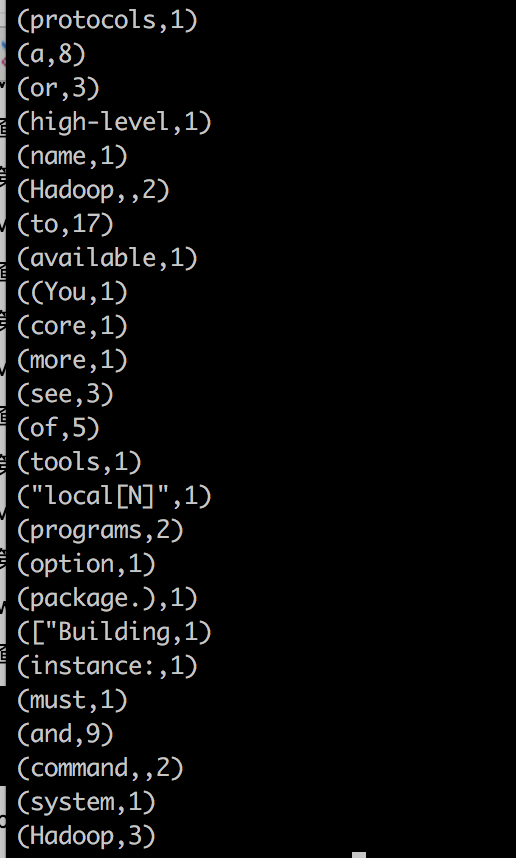
结果,只用空格做了分词,还可以有许多其他分隔符,具体情况具体看吧,只是做了简单一个helloworld。
了解了RDD之后,很多操作和原理就更好懂一点,由于时间原因就不多说了,大家晚安。