HBase其实就是一个数据库,无非就是存储和增删改查,那我们先从数据模型说起把
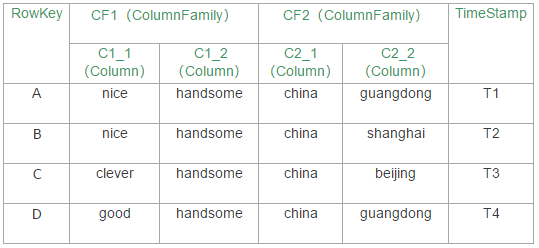
这里有一张表,是用关系型数据库的思维画出来的表,这样比较易于理解:
概念
Table(表格)
没啥说的,和关系型数据库一样,由多行组成
Row(行)
包含一个key和一个或者多个列。行按照RowKey字典序存储在表格中。
Column Family(列族)
可以理解为一组列的集合,HBase官方建议尽量的减少ColumnFamily的数量。
Column Qualifier(列)
一个 Column Family 下面有多个Column Qualifier,
Timestamp(时间戳)
时间戳是写在值旁边的一个用于区分值的版本的数据。可以开发者自己指定,默认情况下,时间戳表示的是当数据写入时RegionSever的时间点。
Cell(单元)
单元是由行、列族、列、值和代表值版本的时间戳组成的。举个例子:
A column=CF1:C1_1, timestamp=T1, value=nice实际模型
上面表的其中一行,在hbase shell 中显示实际是这样的。
hbase(main):006:0> scan 'table_name'
ROW COLUMN+CELL
A column=CF1:C1_1, timestamp=T1, value=nice
A column=CF1:C1_2, timestamp=T1, value=handsome
A column=CF1:C2_1, timestamp=T1, value=china
A column=CF1:C2_2, timestamp=T1, value=guangdong可见
- 稀疏列存储:如果RowKey=B;Column=C1_1 这一格是空的,不会造成存储空间碎片,只会少存一行
B column=CF1:C1_1, timestamp=T1, value=nice- 添加列方便:只需指定列名列族名,column=CF1:C1_1
- rowkey字典序排列
- 每个value都有一个时间戳
操作汇总
注意后方高能,是一些常用的命令,看完可以收藏一波。
增删改查
创建表
create '表名称', '列族名称1','列族名称2','列族名称N'添加记录/更新记录
put '表名称', '行名称', '列名称:', '值'查看记录
get '表名称', '行名称'查看表中的记录总数
count '表名称'删除记录
delete '表名' ,'行名称' , '列名称'删除一张表
先要屏蔽该表,才能对该表进行删除,第一步 disable '表名称' 第二步 drop '表名称'查看所有记录
scan "表名称" 查看某个表某个列中所有数据
scan "表名称" , {COLUMNS=>'列族名称:列名称'}过滤器
RowFilter
通过rowkey过滤,匹配出rowkey中含uncle的数据。
> scan 'table_name', FILTER=>"RowFilter(=,'substring:uncle')"通过rowkey过滤,匹配出rowkey等于uncle666的数据。
> scan 'table_name', FILTER=>"RowFilter(=,'binary:uncle666')"通过rowkey过滤,匹配出rowkey小于等于uncle666的数据。
> scan 'table_name', FILTER=>"RowFilter(<=,'binary:uncle666')"匹配从rowkey为uncle666开始读50行
> scan 'table_name',{COLUMNS=>['cf:column'],LIMIT => 50,STARTROW=>'uncle666'}匹配时间范围
> scan 'table_name',{COLUMNS=>['cf:column'],LIMIT => 50,TIMERANGE=>'1533530400000,1535930400000'}PrefixFilter
通过rowkey前缀过滤,匹配出rowkey前缀为666的数据。
> scan 'table_name', FILTER=>"PrefixFilter('666')"ValueFilter
通过value过滤,匹配出value含uncle的数据。
> scan 'table_name', FILTER=>"ValueFilter(=,'substring:uncle')"FamilyFilter
通过列簇过滤,匹配出列簇含f的数据。
> scan 'table_name', FILTER=>"FamilyFilter(=,'substring:f')"