spark核心之RDD
什么是RDD
RDD指的是弹性分布式数据集(Resilient Distributed Dataset),它是spark计算的核心。尽管后面我们会使用DataFrame、Dataset进行编程,但是它们的底层依旧是依赖于RDD的。我们来解释一下RDD(Resilient Distributed Dataset)的这几个单词含义。
弹性:在计算上具有容错性,spark是一个计算框架,如果某一个节点挂了,可以自动进行计算之间血缘关系的跟踪分布式:很好理解,hdfs上数据是跨节点的,那么spark的计算也是要跨节点的。数据集:可以将数组、文件等一系列数据的集合转换为RDD
RDD是spark的一个最基本的抽象(如果你看一下源码的话,你会发现RDD在底层是一个抽象类,抽象类显然不能直接使用,必须要继承它然后实现它内部的一些方法才可以使用,它代表了不可变的、元素的分区(partition)集合,这些分区可以被并行操作。假设我们有一个300万元素的数组,那么我们就可以将300万个元素分成3份,每一个份就是一个分区,每个分区都可以在不同的机器上进行运算,这样就能提高运算效率。
RDD支持很多操作,比如:map、filter等等,我们后面会慢慢介绍。当然,RDD在scala的底层是一个类,但是我们后面有时候会把RDD和RDD实例对象都叫做RDD,没有刻意区分,心里面清楚就可以啦。
RDD特性
RDD有如下五大特性:
RDD是一系列分区的集合。我们说了对于大的数据集我们可以切分成多份,每一份就是一个分区,可以每一个分区单独计算,所以RDD就是这些所有分区的集合。就类似于hdfs中的block,一个大文件也可以切分成多个blockRDD计算会对每一个分区进行计算。假设我们对RDD做一个map操作,显然是对RDD内部的每一个分区都进行相同的map操作。RDD会依赖于一系列其它的RDD。假设我们对RDD1进行操作得到了RDD2,然后对RDD2操作得到了RDD3,同理再得到RDD4。而我们说RDD是不可变的,对RDD进行操作会形成新的RDD,所以RDD2依赖于RDD1,RDD3依赖于RDD2,RDD4依赖于RDD3,RDD1 => RDD2 => RDD3 => RDD4,所以RDD在转换期间就如同流水线一样,RDD之间是存在依赖关系的。这些依赖关系是非常重要的,假设RDD1有五个分区,那么显然RDD2、3、4也是有五个分区的,假设在计算RDD3的时候RDD2的第三个分区数据丢失了,那么spark会通过RDD之间血缘关系,知道RDD2依赖于RDD1,那么会通过RDD1重新进行之前的计算得到RDD2第三个分区的数据,注意:这种情况只会计算丢失的分区的数据。所以我们说RDD具有容错性,如果第n个操作失败了,那么会从第n-1个操作重新开始。可选,针对于key-value类型的RDD,会有一个partitioner,来表示这个RDD如何进行分区,比如:基于哈希进行分区。如果不是这种类型的RDD,那么这个partitioner显然就是空了。可选,用于计算每一个分区最好位置。怎么理解呢?我们说数据和计算都是分布式的,如果该分区对应的数据在A机器上,那么显然计算该分区的最好位置就是A机器。如果计算和数据不在同一个机器或者说是节点上,那么我们会把计算移动到相应的节点上,因为在大数据中是有说法的,移动计算优于移动数据。所以RDD第五个特性就是具有计算每一个分区最好位置的集合。
图解RDD
spark在运行的时候,每一个计算任务就是一个task,另外:对于RDD而言,不是一个RDD计算对应一个task,而是RDD内部的每一个分区计算都会对应一个task。假设这个RDD具有5个分区,那么对这个RDD进行一个map操作,就会生成5个task。另外,分区的数据是可以进行persist(持久化)的,比如:内存、磁盘、内存+磁盘、多副本、序列化。
关于RDD计算,我们画一下图

SparkContext和SparkConf
在介绍RDD之前,我们需要了解一下什么SparkContext和SparkConf,因为我们肯定要先连接到spark集群,才可以创建RDD进行编程。
SparkContext是pyspark的编程入口,作业的提交,任务的分发,应用的注册都会在SparkContext中进行。一个SparkContext实例对象代表了和spark的一个连接,只有建立的连接才可以把作业提交到spark集群当中去。实例化了SparkContext之后才能创建RDD、以及我们后面会介绍的Broadcast广播变量。
SparkConf是用来设置配置的,然后传递给SparkContext。
对于创建一个SparkContext对象,首先我们可以通过pyspark模块来创建:
from pyspark import SparkContext
from pyspark import SparkConf
# setAppName是设置展示在webUI上的名字,setMaster表示运行模式
# 但是我们目前是硬编码,官方推荐在提交任务的时候传递。当然我们后面说,现在有个印象即可
conf = SparkConf().setAppName("satori").setMaster("local")
# 此时我们就实例化出来一个SparkContext对象了,传递SparkConf对象
sc = SparkContext(conf=conf)
# 我们就可以使用sc来创建RDD
# 总之记住:SparkContext是用来实例化一个对象和spark集群建立连接的
# SparkConf是用来设置一些配置的,传递给SparkContext其次我们通过shell进行操作,我们直接启动pyspark:
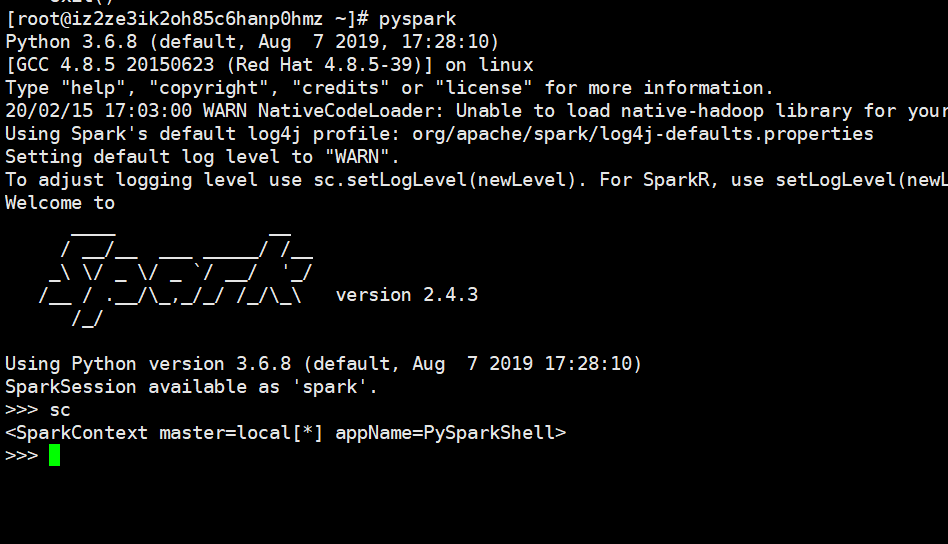
当我们启动之后,输入sc,我们看到pyspark shell直接为我们创建了一个默认的SparkContext实例对象,master叫做local[*](*表示使用计算机所以的核),appName叫做PySparkShell。我们在介绍RDD相关操作的时候,会先使用shell的方式进行演示,当然使用py脚本编程的时候也是一样的。另外,pyspark使用的是原生的Cpython解释器,所以像numpy、pandas之类的包,原生python可以导入的,在pyspark shell里面也是可以导入的。
我们通过sc.getConf()也能拿到对应的SparkConf实例对象。
那么我们可不可以在创建的时候手动指定master和name呢?答案显然是可以的。
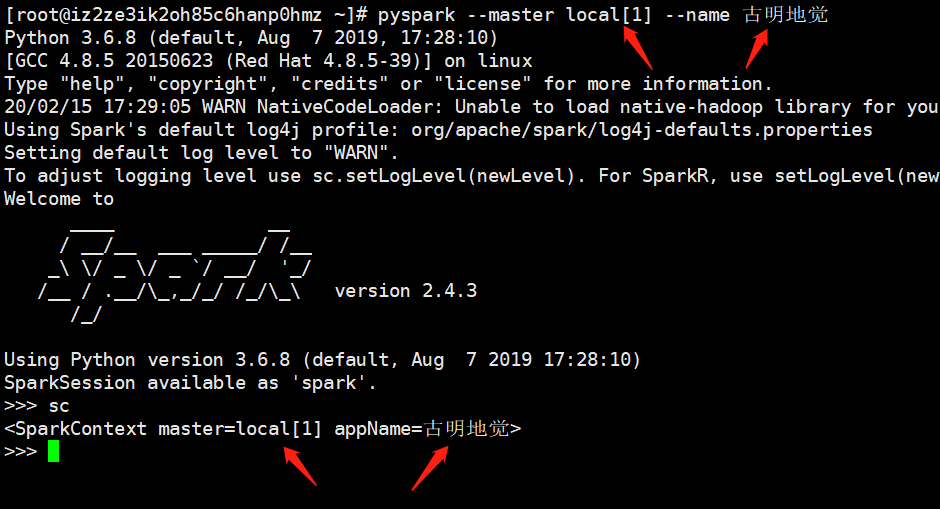
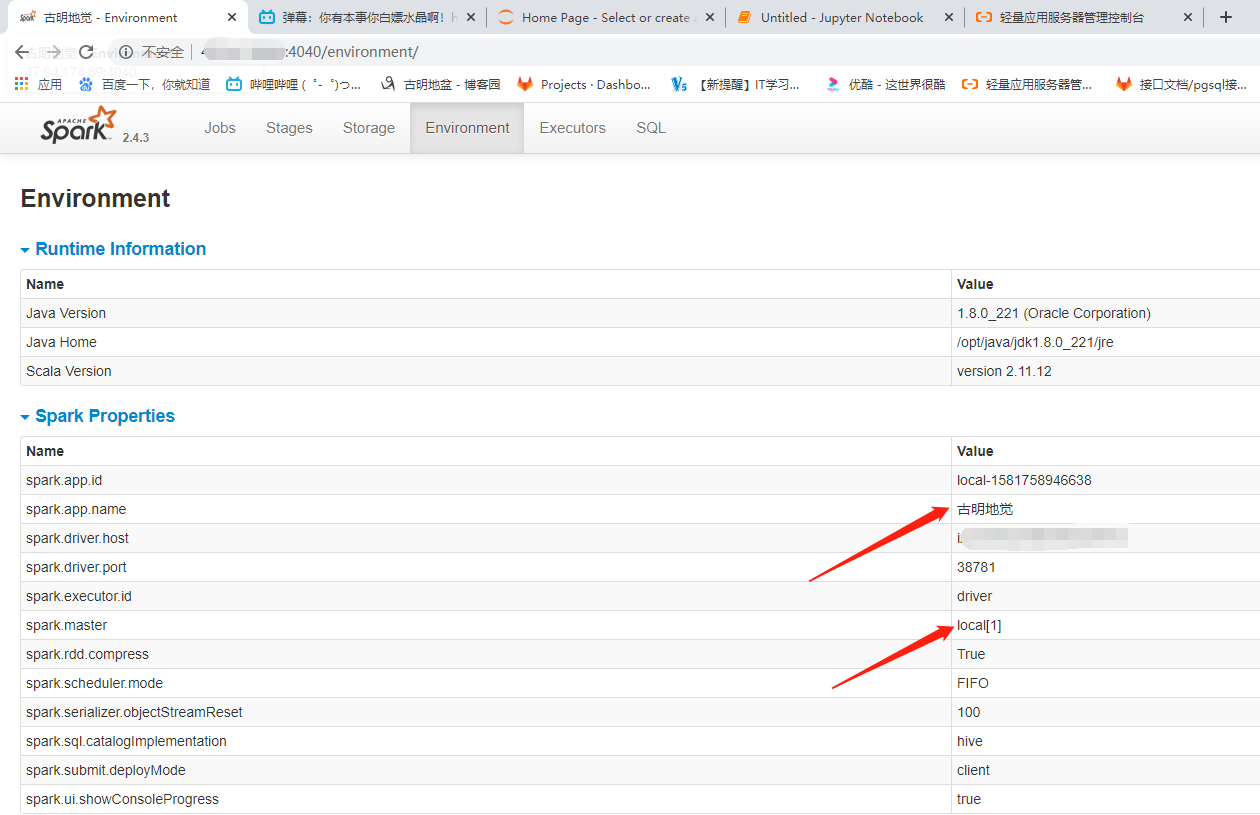
我们看到我们在创建的时候手动设置的master和name生效了,我们再通过webUI来看一下,pyspark的webUI默认是4040。
创建RDD
我们说RDD是spark的核心,那么如何创建一个RDD呢?答案显然是通过SparkContext实例对象,因为上面已经说了。你可以通过编写py文件的方式(我们后面会说)、手动创建一个SparkContext实例对象,也可以通过启动pyspark shell,直接使用默认为你创建好的,对,就是那个sc。由于SparkContext实例对象操作方式都是一样的,所以我们目前就先使用pyspark shell来进行编程。后面我们会说如何通过编写脚本的方式进行spark编程,以及作业如何提交到spark上运行。
通过sc(为了方便,sc就代指了SparkContext实例对象)创建RDD有两种方式。
将一个已经存在的集合转成RDD通过读取存储系统里面的文件,转成RDD。这个存储系统可以是本地、hdfs、hbase、s3等等,甚至可以是mysql等关系型数据库。
下面我们就来代码操作如何创建RDD,注意:现在我们是在pyspark shell中进行操作的。所以sc是创建好的,不要看到了sc觉得纳闷,为什么变量没定义就可以使用;还有由于是交互式环境,我们也不需要print,如果是可打印的,会自动打印。
从已经存在的集合创建
>>> data = range(10)
>>> rdd1 = sc.parallelize(data) # 调用sc.parallelize方法,可以将已经存在的集合转为RDD
>>> data
range(0, 10)
>>> rdd1 # 输出得到的是一个RDD对象
PythonRDD[1] at RDD at PythonRDD.scala:53
>>> rdd1.collect() # 如果想输出的话,调用collect方法,这些后面会说。
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> # 进行map操作得到rdd2
>>> rdd2 = rdd1.map(lambda x: x + 1)
>>> rdd2.collect()
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> # 进行reduce操作
>>> rdd2.reduce(lambda x, y: x + y)
55
>>> # 这些RDD相关的操作函数我们后面会说,但是从python的内置函数map、reduce显然也能明白是干什么的我们看一下web界面

上面显示了三个任务,为什么是三个,我们后面会说。另外我们通过parallelize创建RDD的时候是可以指定分区的。
>>> rdd3 = sc.parallelize(data, 5)
>>> rdd3.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> 虽然结果没有变化,但是我们来看一下web界面。
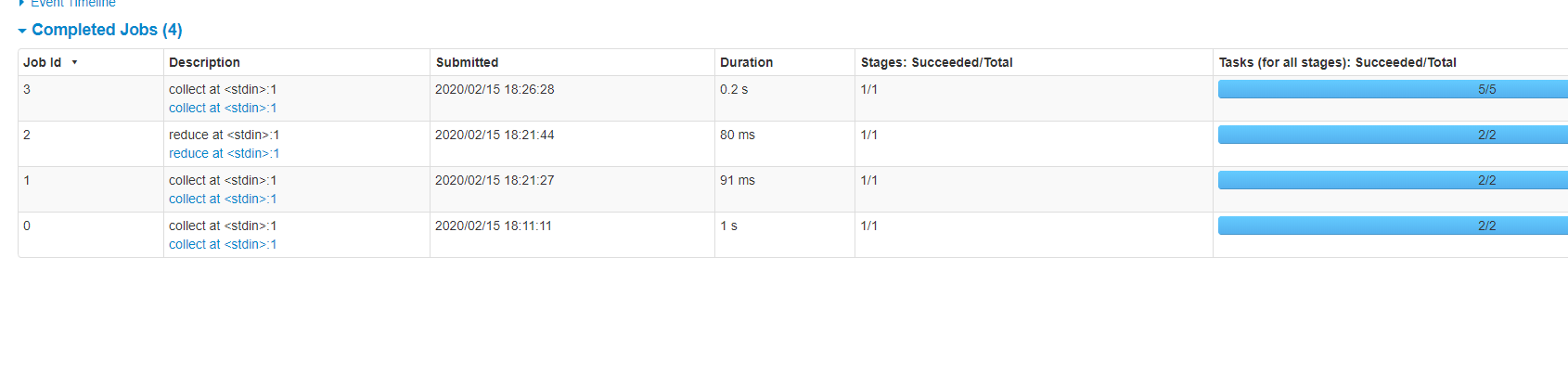
我们看到任务数量变成了5,因为指定了5个分区,至于下面的2,说明默认是两个分区。因为分区可大可小,如果每一个节点的cpu只执行一个分区可能有点浪费,如果跑的快的、或者分区的数据集比较少的,很快就跑完了,那么容易造成资源浪费,因此spark官方建议每隔CPU对应2到4个分区,这样可以把资源充分利用起来。至于具体设置多少个,这个就取决于实际项目、以及规定的处理时间、节点对应的机器性能等等,所以如果你根据业务找到了比较好的分区个数,那么就传递给parallelize的第二个参数即可。
从存储系统里面的文件创建
我们还可以读取存储系统里面的文件来创建RDD。我们演示一下从本地读取文件、和从hdfs上读取文件。
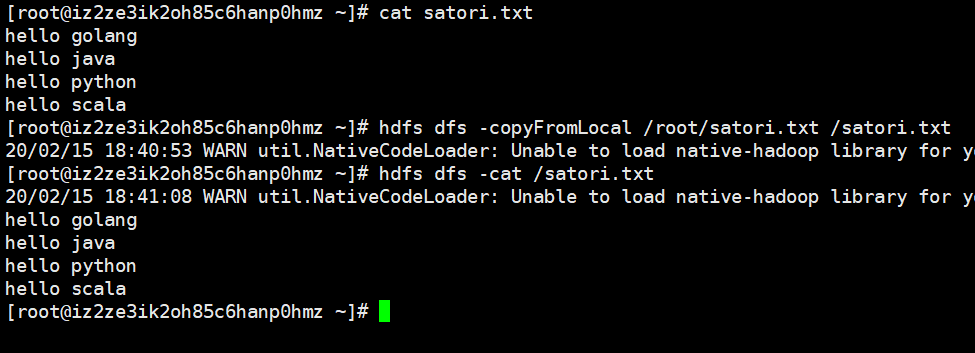
在本地创建一个satori.txt,内容如下,并上传到hdfs上面。
>>> # 读取文件使用textFile,接收一个文件路径,当然同时也可以指定分区
>>> # 我们可以从本地读取,读取的格式为"file://文件路径"
>>> rdd1 = sc.textFile("file:///root/satori.txt")
>>> rdd1.collect() # 我们看到默认是以\n分隔的
['hello golang', 'hello java', 'hello python', 'hello scala']
>>>
>>> # 从hdfs上读取,格式为"hdfs://ip:port文件路径",port就是hdfs集群上的端口,就是你在core-site.xml里面设置的
>>> rdd2 = sc.textFile("hdfs://localhost:9000/satori.txt", 4)
>>> rdd2.collect()
['hello golang', 'hello java', 'hello python', 'hello scala']
>>>
>>> rdd2.map(lambda x: len(x)).collect()
[12, 10, 12, 11]
>>> rdd2.map(lambda x: len(x)).reduce(lambda x, y: x + y)
45
>>> 我们看到通过textFile读取外部文件的方式创建RDD也是没有问题的,但是需要注意的是:如果你是spark集群,并且还是通过本地文件的方式,那么你要保证所有节点上相同路径都存在该文件。
我目前都是单节点的,当然对于学习来讲单节点和多节点都是差不多的,不可能因为用的多节点,语法就变了,只是多节点在操作的时候要考虑到通信、资源等问题。比如:我们这里读取的是本地的/root/satori.txt,这就表示访问本地的/root/satori.txt文件,如果你搭建的是集群,那么你要保证每个节点都存在/root/satori.txt,否则节点根本获取不到这个数据。因此这种情况需要也别注意了,所以在学习语法的时候我个人不建议搭建spark集群(也就是所谓的standalone模式),公司生产上面也很少使用这种模式,当然不是没有,只是很少,绝大部分都是跑在yarn上面的。关于spark的运行模式,资源管理以及调度、我们后面也会慢慢聊。
因此解决办法就是把文件拷贝到每一个节点上面,或者使用网络共享的文件系统。
另外textFile不光可以读取文件,还可以读取目录:/dir、模糊匹配:/dir/*.txt、以及读取gz压缩包都是支持的。
除了textFile,还可以使用wholeTextFiles读取目录。
wholeTextFiles:接收一个目录,会把里面所有的文件内容读取出来,以[("文件名", "文件内容"), ("文件名", "文件内容")...]的格式返回
>>> sc.wholeTextFiles("hdfs://localhost:9000/").collect()
[('hdfs://localhost:9000/satori.txt', 'hello golang\nhello java\nhello python\nhello scala\n')]
>>> # 我这里/目录下面只有一个文件,把文件内容全部读取出来了我们现在知道如何读取文件转化为RDD,那么我们如何将RDD保存为文件呢?可以使用saveAsTextFile
>>> data = [1, 2, 3, 4, 5]
>>> rdd1 = rdd.map(lambda x: f"古明地觉{x}号")
>>> # 默认是本地,当然也可以指定file://
>>> rdd1.saveAsTextFile("/root/a.txt")
>>> # 保存到hdfs上面
>>> rdd1.saveAsTextFile("hdfs://localhost:9000/a.txt")
但是我们发现保存的a.txt并不是一个文件,并不是说把整个rdd都保存一个文件,这个是由你的分区决定的。保存的是一个目录,文件在目录里面,我们看到有两部分,因为是两个分区。
>>> data = [1, 2, 3, 4, 5]
>>> # 这里我们创建rdd的时候,指定5个分区
>>> rdd = sc.parallelize(data, 5)
>>> rdd1 = rdd.map(lambda x: f"古明地觉{x}号")
>>> # 保存为b.txt,显然这个b.txt是个目录
>>> rdd1.saveAsTextFile("/root/b.txt")
>>> 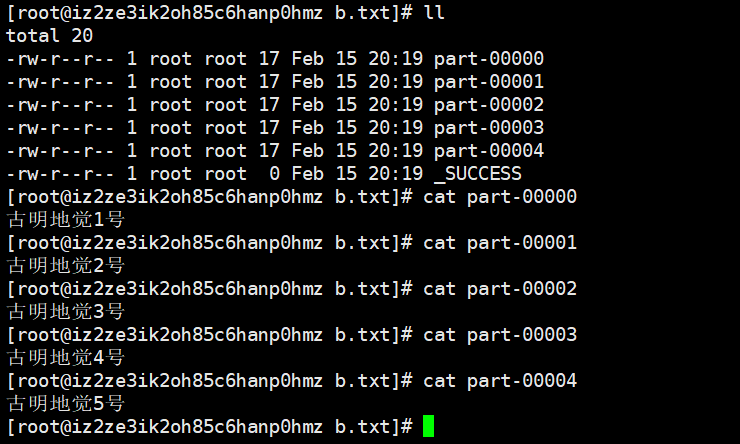
结果跟我们预想的是一样的,有多少个分区就会有多少个part,因为spark是把每个分区单独写入一个文件里面。至于hdfs我们就不用演示了,一样的,算了还是看看吧。

spark应用程序开发以及运行
我们目前是通过pyspark shell进行操作的,显然这仅仅是用来做测试使用的,我们真正开发项目肯定是使用ide进行操作的(vim、notepad你也给我当成是ide,Σ(⊙▽⊙"a)。下面我们就来看看如何使用python开发一个spark应用程序,并且运行它。这里我在Windows上使用pycharm开发,注意:但是python解释器配置的我阿里云上python3,pycharm是支持这个功能的,远程连接服务器上的python环境,所以我们在Windows上操作的python是linux上的python。
import os
import platform
print(os.name) # posix
print(platform.system()) # Linux
print(os.listdir("/"))
"""
['home', 'run', 'tmp', 'opt', 'usr', 'lost+found', 'srv', 'lib', '.autorelabel',
'proc', 'mnt', 'boot', 'lib64', 'dev', 'redis6379.log', 'sbin', 'sys', 'root',
'bin', 'media', 'etc', 'var', 'data']
"""还有一种简便的方法,你在服务器上启动一个jupyter notebook,然后再Windows上通过浏览器打开、输入token远程连接也是可以的。当然如果需要编写的py文件比较多就不推荐了,如果只是学习的话还是可以的。
from pyspark import SparkContext
from pyspark import SparkConf
# 创建SparkConf实例:设置的是spark相关的参数信息
# 我们这里只设置appName,master默认就好,当然名字设置不设置也无所谓啊
conf = SparkConf().setAppName("satori")
# 传入conf,创建SparkContext对象。另外master、appName也是可以在SparkContext里面单独设置的
sc = SparkContext(conf=conf)
data = [1, 2, 3, 4, 5]
rdd1 = sc.parallelize(data)
# 不在shell里面了,我们需要print才能看到结果
print(rdd1.collect()) # [1, 2, 3, 4, 5]
# 好的习惯,编程结束之后stop掉,表示关闭与spark的连接
# 否则当你再次创建相同的SparkContext实例的时候就会报错
# 会提示你:Cannot run multiple SparkContexts at once; existing SparkContext(app=satori, master=local[*]
sc.stop()我们这里是通过pyspark模块执行是成功的,那么我们也可以编写一个py文件提交到spark上面运行。
提交方式:pyspark-submit --master xxx --name xxx py文件
from pyspark import SparkContext
from pyspark import SparkConf
# 这里我们不再设置master和appName(name)了,还记得我们之前说过吗?
# 官方不推荐这种硬编码的模式,而是通过提交任务的时候指定
conf = SparkConf()
# 既然如此,那么我们就不再需要这个SparkConf了,这里我们写上但是不传递到SparkContext里
sc = SparkContext()
data = [1, 2, 3, 4, 5]
rdd1 = sc.parallelize(data)
print(rdd1.collect()) # [1, 2, 3, 4, 5]
sc.stop()上面的代码我们起名为test1.py,然后提交该作业:spark-submit --master local[*] --name 古明地觉 /root/test1.py
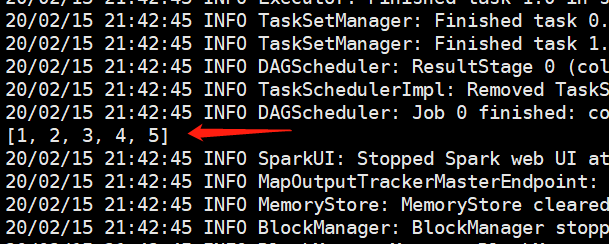
我们提交之后,执行是成功了的,但是输出的东西灰常多,程序的结果就隐藏在中间。
那么问题来了,如果我有很多文件怎么办?要是标准库里面的包我们可以导入,但如果是我们自己写的依赖怎么提交呢?首先多个文件(目录)里面一定存在一个启动文件,用来启动整个程序。假设这个启动文件叫start.py(当然启动文件一定在项目的最外层,如果在项目的包里面,那么它就不可能成为启动文件),那么把除了start.py的其它文件(目录)打包成一个zip包或者egg,假设叫做dependency.egg,那么执行的时候就可以这么执行:
spark-submit --master xxx --name xxx --py-files dependency.egg start.py
如果我们写的程序需要从命令行中传递参数,那么直接跟在start.py(启动文件)后面就行。
关于输出结果,我们只截取了一部分,详细信息可以自己慢慢查看。以及spark-submit支持的其它参数,也可以通过spark-submit --help来查看,不过很多都用不到,因为spark-submit不仅可以提交python程序,还可以提交java等其它程序,里面的很多参数是为其它语言编写的程序准备的,python用不到。
RDD相关操作
我们已经知道如何创建一个RDD、以及使用python开发spark程序并提交运行,那么下面我们来看看RDD都能进行哪些操作。我们读取数据转成RDD之后肯定是要进行操作的,我们之前看到了map、reduce、collect等操作,但是除了这些,RDD还支持很多其他的操作,我们来看一下。
RDD的操作分为两种:transformation和action。
transformation:从一个RDD转换成新的RDD这个过程就是transformation,比如map操作action:对RDD进行计算得到一个值的过程叫做action,比如collect。
直接看可能不好理解,我们来举个例子。我们对一个RDD进行map操作得到了新的RDD,但是这个RDD它并不是具体的值。我们对RDD进行collect操作的时候,才会把值返回回来。实际上,所有的transformation都是惰性的,意思是我们进行map操作的时候,RDD只是记录了这个操作,但是它并没有具体的计算,当我们进行collect求值的时候才会真正的开始进行计算。
>>> data = [1, 2, 3, 4, 5]
>>> rdd = sc.parallelize(data)
>>> rdd1 = rdd.map(lambda x: str(x) + "~~~")
>>> rdd2 = rdd1.map(lambda x: "~~~" + x)
>>>
>>> rdd2.collect()
['~~~1~~~', '~~~2~~~', '~~~3~~~', '~~~4~~~', '~~~5~~~']
>>> 我们对rdd进行操作得到rdd1,rdd1得到rdd2,像这种对一个RDD操作得到新的RDD的过程我们称之为transformation,它是惰性的(lazy),这些过程并不会真正的开始计算,只是记录了相关的操作。当我们对于rdd2进行collect操作、要获取值的时候,才会真正的开始计算,会从最初的rdd开始计算,这个过程我们称之为action。
下面我们就来举例说明RDD的相关操作:
map
map:接收一个函数,会对RDD里面每一个分区的每一个元素都执行相同的操作。话说,能用pyspark的编程的,我估计这些说了都是废话。因此如果有些函数和python的内置函数比较类似的,我就不说那么详细了。
>>> rdd1 = sc.parallelize([1, 2, 3, 4, 5])
>>> # 给里面每一个元素都执行加1的操作
>>> rdd1.map(lambda x: x+1).collect()
[2, 3, 4, 5, 6] filter
filter:类似Python中的filter,选择出符合条件的
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8]
>>> rdd = sc.parallelize(numbers)
>>> rdd.filter(lambda x: x > 3).collect()
[4, 5, 6, 7, 8]
>>>
>>> rdd.filter(lambda x: x % 2 == 0).collect()
[2, 4, 6, 8]flatMap
flatMap:和map不同的是,map是输出一个值返回一个值,而flatMap是输入一个值,返回一个序列、然后将这个序列打开,我们举例说明。
>>> word = ["satori"]
>>> # 函数接收什么,返回什么,所以还是原来的结果
>>> sc.parallelize(word).map(lambda x: x).collect()
['satori']
>>> # 接收一个值,返回一个序列,然后会自动将这个序列打开
>>> sc.parallelize(word).flatMap(lambda x: x).collect()
['s', 'a', 't', 'o', 'r', 'i']
>>>
>>> # split之后是一个列表,对于map,那么返回的就是列表
>>> words = ["hello mashiro", "hello satori"]
>>> sc.parallelize(words).map(lambda x: x.split(" ")).collect()
[['hello', 'mashiro'], ['hello', 'satori']]
>>> # 但对于flatMap来说,会将这个列表打开
>>> sc.parallelize(words).flatMap(lambda x: x.split(" ")).collect()
['hello', 'mashiro', 'hello', 'satori']
>>> 所以从名字上看,flatMap相比map多了一个flat,也是很形象的,flat表示平的,操作上就是直接将列表打开,不再嵌套。另外我们看到我们将很多操作都写在了一行,这是没有问题的,如果操作比较多,我们鼓励写在一行,这叫做链式编程。当然如果为了直观,你也可以分为多行来写,反正transformation也是懒加载。
groupByKey
groupByKey:这个语言表达有点困难,我们直接看一个例子。
>>> val = [("a", "hello"), ("a", "how are you"), ("b", "who am i"), ("a", 4)]
>>> rdd = sc.parallelize(val)
>>>
>>> rdd.groupByKey().collect()
[('b', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe37b8>), ('a', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe3630>)]
>>> rdd.groupByKey().map(lambda x: (x[0], list(x[1]))).collect()
[('b', ['who am i']), ('a', ['hello', 'how are you', 4])]
>>> 我们看到使用groupByKey的rdd,是一个由[(x1, y1), (x2, y2), (x3, y3)...]这样的序列(当然里面不一定是元组、列表也是可以的)转化得到的,然后使用groupByKey会将元组里面第一个值相同的聚合到一起,就像我们看到的那样,只不过得到的是一个可迭代对象,我们需要转化为list对象。这个功能特别适合word count,也就是词频统计,再来看一个例子。
>>> words = ["hello mashiro", "hello world", "hello koishi"]
>>> rdd = sc.parallelize(words)
>>> # 先进行分隔
>>> rdd1 = rdd.flatMap(lambda x: x.split(" "))
>>> rdd1.collect()
['hello', 'mashiro', 'hello', 'world', 'hello', 'koishi']
>>> # 给每个词都标上一个1,因为它们每个词都出现了1次
>>> rdd2 = rdd1.map(lambda x: (x, 1))
>>> rdd2.collect()
[('hello', 1), ('mashiro', 1), ('hello', 1), ('world', 1), ('hello', 1), ('koishi', 1)]
>>>
>>> # 使用groupByKey将值相同的汇聚到一起
>>> rdd3 = rdd2.groupByKey()
>>> rdd3.collect()
[('mashiro', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe3828>), ('world', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe3128>), ('koishi', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe3c50>), ('hello', <pyspark.resultiterable.ResultIterable object at 0x7fa0aefe3470>)]
>>> # 变成list对象
>>> rdd4 = rdd3.map(lambda x: (x[0], list(x[1])))
>>> rdd4.collect()
[('mashiro', [1]), ('world', [1]), ('koishi', [1]), ('hello', [1, 1, 1])]
>>> # 进行求和,即可得到每个词出现的次数。当然求和的话可以直接使用sum,没必要先变成list对象
>>> rdd5 = rdd4.map(lambda x: (x[0], sum(x[1])))
>>> rdd5.collect()
[('mashiro', 1), ('world', 1), ('koishi', 1), ('hello', 3)]
>>>
>>> 还记得之前说的链式编程吗?其实这个词频统计很简单,工作上是没必要写这么多行的。
>>> words = ["hello mashiro", "hello world", "hello koishi"]
>>> rdd = sc.parallelize(words)
>>> rdd.flatMap(lambda x: x.split(" ")).map(lambda x: (x, 1)).groupByKey().map(lambda x: (x[0], sum(x[1]))).collect()
[('mashiro', 1), ('world', 1), ('koishi', 1), ('hello', 3)]
所以groupByKey非常适合词频统计,这里面不接收参数,调用这个方法RDD需要是一个列表或者元组、里面嵌套多个列表或者元组(包含两个元素),然后把索引为0的值相同的聚合在一起。
reduceByKey
调用reduceByKey方法的rdd对应的数据集和groupByKey是一样的,我们一旦看到ByKey,就应该想到序列里面的元素要是一个有两个元素的序列,然后第一个元素相同的分发到一起。但是它和groupByKey不同的是,groupByKey不接收参数,然后直接把第一个元素相同聚合在一起,而reduceByKey会比groupByKey多一步,因为它需要接受一个函数,会自动将分发到一起的值(原来所有序列的第二个元素)进行一个计算。举例说明:
>>> words = ["hello mashiro", "hello world", "hello koishi"]
>>> rdd = sc.parallelize(words)
>>> rdd.flatMap(lambda x: x.split(" ")).map(lambda x: (x, 1)).groupByKey().map(lambda x: (x[0], sum(x[1]))).collect()
[('mashiro', 1), ('world', 1), ('koishi', 1), ('hello', 3)]
>>>
>>> rdd.flatMap(lambda x: x.split(" ")).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y).collect()
[('mashiro', 1), ('world', 1), ('koishi', 1), ('hello', 3)]
和groupByKey对比的话,还是很清晰的。
sortByKey
sortByKey:从名字能看出来,这个是排序用的,按照索引为0的元素进行排序。
>>> words = [('c', 2), ('a', 1), ('b', 3)]
>>> rdd = sc.parallelize(words)
>>>
>>> rdd.sortByKey().collect()
[('a', 1), ('b', 3), ('c', 2)]
>>>
>>> rdd.sortByKey(False).collect()
[('c', 2), ('b', 3), ('a', 1)]
>>> # 把元祖里面的两个元素想象成字典的key: value,ByKey自然是根据Key来进行操作
>>> # 可显然我们是想根据value来进行排序,根据出现次数多的进行排序。所以我们可以先交换顺序,排完了再交换回来
>>> rdd.map(lambda x: (x[1], x[0])).sortByKey().map(lambda x: (x[1], x[0])).collect()
[('a', 1), ('c', 2), ('b', 3)]
>>> rdd.map(lambda x: (x[1], x[0])).sortByKey(False).map(lambda x: (x[1], x[0])).collect()
[('b', 3), ('c', 2), ('a', 1)]
>>> # 默认从小到大排,False则表示逆序、从大到小排union
union:合并两个RDD
>>> rdd1 = sc.parallelize([1, 2, 3])
>>> rdd2 = sc.parallelize([11, 22, 33])
>>> # 很简单,就是将两个RDD合并
>>> rdd1.union(rdd2).collect()
[1, 2, 3, 11, 22, 33]
>>> # 甚至和自身做union也是可以的
>>> rdd1.union(rdd1).collect()
[1, 2, 3, 1, 2, 3]distinct
distinct:去重,我们看到这有点像sql啊。其实spark还支持spark sql、也就是写sql语句的方式进行编程。我们后面、或者下一篇博客会说。
>>> rdd = sc.parallelize([11, 11, 2, 22, 3, 33, 3]).distinct()
>>> # 不过去重之后貌似没什么顺序了
>>> rdd.collect()
[2, 22, 11, 3, 33]join
join:熟悉sql的估计肯定不陌生,join有以下几种:inner join、left join、right join、outer join。这个操作join的RDD和xxxByKey对应的RDD应该具有相同的数据格式,对,就是[(x1, y1), (x2, y2)...]这种格式。
有时候光说不好理解,看例子就能很容易明白。
>>> rdd1 = sc.parallelize([("name", "古明地觉"), ("age", 16), ("gender", "female")])
>>> rdd2 = sc.parallelize([("name", "古明地恋"), ("age", 15), ("place", "东方地灵殿")])
>>>
>>> # join默认是内连接,还是想象成key: value,把两个RDD的key相同的汇聚在一起
>>> # 如果不存在相同的key,那么舍弃
>>> rdd1.join(rdd2).collect()
[('name', ('古明地觉', '古明地恋')), ('age', (16, 15))]
>>>
>>> # 以左RDD为基准,如果右RDD没有与之匹配的则为None,比如rdd1的"gender"在rdd2中不存在,所以置为None
>>> rdd1.leftOuterJoin(rdd2).collect()
[('name', ('古明地觉', '古明地恋')), ('gender', ('female', None)), ('age', (16, 15))]
>>>
>>> # 同理以右RDD为基准,当然啦,顺序还是从左到右的,里面的元素显示rdd1的元素,再是rdd2的元素
>>> rdd1.rightOuterJoin(rdd2).collect()
[('name', ('古明地觉', '古明地恋')), ('age', (16, 15)), ('place', (None, '东方地灵殿'))]
>>>
>>> # 全连接,不用我说了
>>> rdd1.fullOuterJoin(rdd2).collect()
[('name', ('古明地觉', '古明地恋')), ('gender', ('female', None)), ('age', (16, 15)), ('place', (None, '东方地灵殿'))]
zip
zip:类似于python中的zip,但是要求两个RDD的元素个数以及分区数必须一样。
>>> rdd1 = sc.parallelize(['a', 'b', 'c'])
>>> rdd2 = sc.parallelize([1, 2, 3])
>>>
>>> rdd1.zip(rdd2).collect()
[('a', 1), ('b', 2), ('c', 3)]
>>> zipWithIndex
zipWithIndex:对单个RDD操作的,会给每个元素加上一层索引,从0开始自增。
>>> rdd1 = sc.parallelize(['a', 'b', 'c'])
>>> rdd1.zipWithIndex().collect()
[('a', 0), ('b', 1), ('c', 2)]以上就是一些常用的transformation操作,我们说RDD转换得到新的RDD这个过程叫做transformation,它是惰性的,只是记录了操作,但是并没有立刻进行计算。当遇到action操作时(计算具体的值,比如collect、reduce、当然还有其它action操作,我们后面会说),才会真正进行计算。那么下面我们再来看看一些不是很常用的transformation操作。
mapPartitions
mapPartitions:这个是对每一个分区进行map
>>> rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
>>> # 函数参数x不再是rdd的每一个元素,而是rdd的每一个分区
>>> # 这个不能写return,要写yield,或者返回一个可迭代的对象,会自动获取里面的所有元素
>>> def f(x): yield sum(x)
...
>>> # 三个分区,显然一个分区两个元素,那么会把每个分区的所有元素进行相加
>>> rdd.mapPartitions(f).collect()
[3, 7, 11]
>>> # sum(x)不是一个可迭代的,我们需要放在一个列表里面,或者定义函数使用yield也行
>>> # 会自动遍历返回的可迭代对象,把元素依次放到列表里面
>>> rdd.mapPartitions(lambda x: [sum(x)]).collect()
[3, 7, 11]mapPartitionsWithIndex
mapPartitionsWithIndex:还是对每一个分区进行map,但是会多出一个索引
>>> rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
>>> rdd.mapPartitionsWithIndex(lambda index, x: (index, sum(x))).collect()
[0, 3, 1, 7, 2, 11]
列表中的0 1 2表示分区索引。
intersection
intersection:union是将两个RDD合并,其实是取两者的并集,intersection则是取交集,subtract则是取差集。
>>> rdd1 = sc.parallelize([1, 2, 3])
>>> rdd2 = sc.parallelize([1, 22, 3])
>>> rdd1.intersection(rdd2).collect()
[1, 3]
>>> rdd1.subtract(rdd2).collect()
[2]sortBy
sortBy:我们之前说过sortByKey会默认按照key来排序,sortBy需要我们自己指定,可以按照key也可以按照value
>>> rdd = sc.parallelize([('a', 1), ('c', 2), ('b', 3)])
>>> rdd.sortBy(lambda x: x[0]).collect()
[('a', 1), ('b', 3), ('c', 2)]
>>> rdd.sortBy(lambda x: x[1]).collect()
[('a', 1), ('c', 2), ('b', 3)]
>>>
>>> rdd.sortBy(lambda x: x[0], False).collect()
[('c', 2), ('b', 3), ('a', 1)]
>>> rdd.sortBy(lambda x: x[1], False).collect()
[('b', 3), ('c', 2), ('a', 1)]
>>> coalesce
coalesce:改变RDD的分区数。分区数会影响作业的并行度,因此会视作业的具体情况而定。这个方法第一个参数接收要改变的分区个数,第二个参数是shuffle,默认为False,表示重新分区的时候不进行shuffle操作,此时效率较高;如果指定为True,表示重分区的时候进行shuffle操作,此时效果等价于下面要介绍的repartition,效率较低。关于什么是shuffle操作,我们后面会说。
>>> rdd = sc.parallelize(range(10), 5)
>>> # 使用该函数可以查看分区数
>>> rdd.getNumPartitions()
5
>>> # 改变分区数,变成3
>>> rdd1 = rdd.coalesce(3)
>>> rdd1.getNumPartitions()
3
>>> # 分区数只能变少,不能变多
>>> rdd2 = rdd1.coalesce(4)
>>> rdd2.getNumPartitions()
3
>>> repartition
repartition:该方法也是对RDD进行重新分区,其内部使用shuffle算法,并且分区可以变多、也可以变少,如果是减少分区数,那么推荐使用coalesce。
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> rdd1 = rdd.repartition(4)
>>> rdd1.getNumPartitions()
4
>>> rdd1.repartition(2).getNumPartitions()
2
>>> flatMapValues
flatMapValues:和groupByKey相反,我们看个栗子就清楚了。
>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 2), ("a", 3), ("b", 2)])
>>> rdd1 = rdd.groupByKey().map(lambda x: (x[0], list(x[1])))
>>> rdd1.collect()
[('b', [1, 2]), ('a', [1, 2, 3])]
>>> # 所以它个groupByKey是相反的,这里面一般写lambda x: x
>>> rdd1.flatMapValues(lambda x: x).collect()
[('b', 1), ('b', 2), ('a', 1), ('a', 2), ('a', 3)]groupBy
groupBy:之前的groupByKey默认是按照相同的key进行聚合,这里则可以单独指定,并且里面序列里面的元素可以不再是元组,普通的整型也是可以的。
>>> rdd = sc.parallelize([12, "a", "ab", "1", 23, "xx"])
>>> # 将里面的元素变成str之后,长度大于1的分为一组,小于等于1的分为一组
>>> rdd.groupBy(lambda x: len(str(x))>1).collect()
[(False, <pyspark.resultiterable.ResultIterable object at 0x7f4c4f40f5c0>), (True, <pyspark.resultiterable.ResultIterable object at 0x7f4c4f40f048>)]
>>>
>>> rdd.groupBy(lambda x: len(str(x))>1).map(lambda x: (x[0], list(x[1]))).collect()
[(False, ['a', '1']), (True, [12, 'ab', 23, 'xx'])]keyBy
keyBy:看例子就能理解,其实很多方法我们完全可以用已经存在的来替代。
>>> rdd = sc.parallelize([1, 2, 3])
>>> rdd.keyBy(lambda x: f"hello_{x}").collect()
[('hello_1', 1), ('hello_2', 2), ('hello_3', 3)]
>>>
>>> rdd.map(lambda x: (f"hello_{x}", x)).collect()
[('hello_1', 1), ('hello_2', 2), ('hello_3', 3)]可以看到keyBy就是将函数返回的元素和原来的元素组合成一个二元tuple,这个我们完全可以使用map来替代,或许keyBy简单了那么一点点,但是说实话我个人还是习惯用map。其实一些api如果没有什么不可替代性、或者无法在很大程度上简化工作量的话,我觉得记太多反而是个负担。
keys和values
keys:获取所有的key。values:获取所有的value。我们这里的key和value都指的是二元tuple里面的两个元素。其实RDD对应的数据类型无非两种,一种是对应的列表里面都是整型或者字符串的RDD,另一种是里面都是二元tuple(或者list)的RDD,我们基本上使用这两种RDD。我们上面出现的所有的key指的都是二元tuple里面的第一个元素,把这个tuple的两个元素想象成字典的key和value即可。
>>> rdd = sc.parallelize([("a", 1), ("b", "a"), ("c", "c")])
>>> rdd.keys().collect()
['a', 'b', 'c']
>>> rdd.values().collect()
[1, 'a', 'c']
glom
glom:将每一个分区变成一个单独的列表
>>> rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
>>> rdd.glom().collect()
[[1, 2], [3, 4], [5, 6]]
>>>
pipe
pipe:将RDD里面的每一个元素都执行相同的linux命令
>>> rdd = sc.parallelize(["hello", "hello1", "hello2"], 3)
>>> rdd.pipe("cat").collect()
['hello', 'hello1', 'hello2']
>>> # 1 1 6表示1行、1个单词、6个字符
>>> rdd.pipe("wc").collect()
[' 1 1 6', ' 1 1 7', ' 1 1 7']
>>> randomSplit
randomSplit:将RDD里面的元素随机分隔
>>> rdd = sc.parallelize(range(10))
>>> rdd1 = rdd.randomSplit([1, 4])
>>> rdd1
[PythonRDD[203] at RDD at PythonRDD.scala:53, PythonRDD[204] at RDD at PythonRDD.scala:53]
>>> [_.collect() for _ in rdd1]
[[5, 7, 9], [0, 1, 2, 3, 4, 6, 8]]
>>> sample
sample:随机取样
>>> rdd = sc.parallelize(range(10))
>>> # 参数一:是否有放回。参数二:抽样比例。参数三:随机种子
>>> rdd.sample(True, 0.2, 123).collect()
[0, 9]
foldByKey
foldByKey:针对于key: value形式的RDD,进行聚合
>>> rdd = sc.parallelize([("a", (1, 2, 3, 4)), ("b", (11, 22, 33, 44))])
>>> rdd1 = rdd.flatMapValues(lambda x: x)
>>> rdd1.collect()
[('a', 1), ('a', 2), ('a', 3), ('a', 4), ('b', 11), ('b', 22), ('b', 33), ('b', 44)]
>>> # 参数一:起始值,参数二:操作函数
>>> rdd1.foldByKey(0, lambda x, y: x + y).collect()
[('b', 110), ('a', 10)]
>>> # 起始值指定20,那么会把20也当成一个元素、也就是初始元素,扔到函数里面去
>>> rdd1.foldByKey(20, lambda x, y: x + y).collect()
[('b', 130), ('a', 30)]
>>> # 我们看到0确实在里面
>>> rdd1.foldByKey(0, lambda x, y: f"{x}->{y}").collect()
[('b', '0->11->22->33->44'), ('a', '0->1->2->3->4')]
>>> 以上就是一些transformation算子,有一些算子比较简单我就没介绍,比如mapValues之类的,我们完全可以使用map来替代,也很简单,没必要记这么多。如果有一些没有介绍到的,可以自己通过pycharm查看RDD这个类源码,看看它都支持哪些方法。源码是很详细的,都有大量的注释。
那么下面我们来看一下action方法,action方法估计我们最一开始就见过了,没错就是collect,把RDD里面的内容以列表的形式返回,那么除了collect还有哪些action算子呢?我们来看一下。
reduce
reduce:这个应该也早就见过了,将里面的内容相加。
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> rdd.reduce(lambda x, y: x + y)
10count
count:计算元素的个数。
>>> rdd = sc.parallelize([1, 2, 3, [4, 5]])
>>> rdd.count()
4take、first
take、first:获取指定个数的元素、获取第一个元素。
>>> rdd = sc.parallelize([1, 2, [3, 4, 5], 6, 7, 8])
>>> # 如果指定的个数超过了元素的总个数也不会报错,而是返回所有元素,即便RDD为空也可以。
>>> rdd.take(3)
[1, 2, [3, 4, 5]]
>>> # 注意:对于first来说,空的rdd调用的话会报错
>>> rdd.first()
1max、min、mean、sum
max、min、mean、sum:获取元素最大值、最小值、平均值、总和。
>>> rdd = sc.parallelize([11, 22, 33, 22])
>>> rdd.max()
33
>>> rdd.min()
11
>>> rdd.mean()
22.0
>>> rdd.sum()
88
当然还有其它的数学函数,比如:stdev,求标准差、variance,求方差等等。遇到相应的需求,可以去查找。并且对于上面的数学操作,还分别对应另一个函数,比如:count -> countApprox,sum -> sumApprox等等,这些函数的特点是可以传入一个timeout,单位为毫秒,要是在指定的时间内没有计算完毕的话,那么就直接返回当前的计算结果。可以自己尝试一下。
foreach
foreach:类似于map,对序列里面的每一个元素都执行相同的操作。
>>> rdd = sc.parallelize([11, 22, 33, 22])
>>> # 但是foreach不会有任何的反应,不会跟map一样返回新的RDD
>>> rdd.foreach(lambda x: x + 1)
>>> # 我们可以执行打印操作
>>> rdd.foreach(lambda x: print(x, x+123))
11 134
22 145
33 156
22 145
>>>foreachPartition
foreachPartition:会对每一个分区都执行相同的操作。
>>> rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
>>> rdd.foreachPartition(lambda x: print(x))
<itertools.chain object at 0x7f9c90ca0978>
<itertools.chain object at 0x7f9c90ca0978>
<itertools.chain object at 0x7f9c90ca0978>
>>> rdd.foreachPartition(lambda x: print(list(x)))
[1, 2]
[3, 4]
[5, 6]
>>>
aggregate
aggregate:这个稍微有点复杂,里面接收三个参数。
参数一:起始值,这个起始值是作用在每个分区上的参数二:每个分区进行的操作参数三:每个分区操作完之后的这些返回的结果进行的操作
>>> rdd = sc.parallelize([1, 2, 3, 1, 2, 3], 3)
>>> # 指定了三个分区,那么结果每个分区对应的值应该是这样: [1, 2] [3, 1] [2, 3]
>>> # 每个分区按照第二个参数指定的操作进行计算,别忘记初始值,这个是作用在每个分区上面的
>>> # 结果就是:2 * 1 * 2, 2 * 3 * 1, 2 * 2 * 3 --> 4, 6, 12
>>> # 然后每个分区返回的结果执行第三个参数指定的操作,加在一起,所以是24
>>> rdd.aggregate(2, lambda x, y:x*y, lambda x, y: x+y)
24aggregateByKey
aggregateByKey:这个是一个transformation方法,不是action,之所以放进来是为了和aggregate进行对比便于理解。这个是把相同的key分成一组,说不好说,直接看例子吧
>>> rdd = sc.parallelize([("a", 1), ("a", 2), ("b", 3), ("c", 1), ("c", 2), ("c", 3)], 3)
>>> # 相同的分为一组,但是注意分区,倒数第三个("c", 1)是和("b", 3)在一个分区里面的
>>> # [("a", [1, 2])] [("b", [3]), ("c", [1])] [("c", [2, 3])]
>>> # 初始元素和里面元素依次相乘--> [("a", 4)] [("b", 6), ("c", 2)] [("c", 12)]
>>> # 然后对分区里面相同key再次进行参数三指定的操作--> [("a", 4)] [("b", 6)] [("c", 14)]
>>> # 上面的每一个列表看成是一个分区即可,为了清晰展示,我把每一个分区单独写成了一个列表
>>> rdd.aggregateByKey(2, lambda x,y:x*y, lambda x,y:x+y).collect()
[('b', 6), ('a', 4), ('c', 14)]另外,对于很多的transformation操作,我们都是可以通过参数:numPartitions指定生成的新的RDD的分区的,不过一般情况下我们不指定这个参数,会和初始的RDD的分区数保持一致。当然如果初始的RDD的分区数设置的不合理,那么是可以在transformation操作的时候进行更改的。
fold
fold:类似于aggregateByKey,但它是action方法,而且调用的不是key、value形式的RDD、并且只需要指定一个函数,会对每个分区、以及每个分区返回的结果都执行相同的操作
>>> rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
>>> # [1, 2] [3, 4] [5, 6] -> 2 * 1 * 2, 2 * 3 * 4, 2 * 5 * 6
>>> # 4 * 24 * 60 * 2 = 11520,并且每一个分区计算之后的结果还要乘上指定的初始值,这一点需要注意
>>> rdd.fold(2, lambda x,y: x*y)
11520
>>>collectAsMap
collectAsMap:对于内部是二元tuple的RDD,我们可以转化为字典。
>>> rdd = sc.parallelize([("a", 1), ("a", 2), ("b", 3), ("c", 1), ("c", 2), ("c", 3)], 3)
>>> # key相同的,value就会被替换掉
>>> rdd.collectAsMap()
{'a': 2, 'b': 3, 'c': 3}
>>> id
id:返回RDD的id值,每个RDD的id值是唯一的
>>> rdd1 = sc.parallelize([])
>>> rdd2 = sc.parallelize([])
>>> rdd3 = sc.parallelize([])
>>>
>>> rdd1.id(), rdd2.id(), rdd3.id()
(326, 327, 328)
>>> histogram
histogram:返回一个直方图数据,看栗子
>>> rdd = sc.parallelize(range(10))
>>> # 返回0-5以及5-8中间的元素个数,当然会连同区间一起返回。注意区间是左闭右开的
>>> rdd.histogram([0, 5, 8])
([0, 5, 8], [5, 4])
>>> # 如果不指定列表,而是指定整型的话
>>> # 会自动为我们将[min, max]等分4个区间,那么第一个列表就有5个元素
>>> rdd = sc.parallelize([0, 11, 33, 22, 44, 55, 66, 33, 100])
>>> rdd.histogram(4)
([0, 25, 50, 75, 100], [3, 3, 2, 1])
>>> isEmpty
isEmpty:检测一个RDD是否为空
>>> rdd1 = sc.parallelize([])
>>> rdd2 = sc.parallelize([1])
>>>
>>> rdd1.isEmpty(), rdd2.isEmpty()
(True, False)
lookup
lookup:查找指定key对应的value,那么显然操作的RDD要是key: value形式的
>>> rdd = sc.parallelize([("a", 1), ("a", 2), ("b", "a")])
>>> rdd.lookup("a")
[1, 2]
>>> rdd.lookup("b")
['a']
>>>
总结
以上就是RDD的一些操作,当然我们这里没有全部介绍完,但是也介绍挺多了,如果工作中不够用的话,那么只能看源码了。当然这么多一次性肯定是无法全部背下来的,需要用的时候再去查即可,当然还是要多动手敲,孰能生巧。