Spark核心 RDD(下)
引言
Spark核心 RDD(下)主要内容包括:一、Spark编程接口(API),二、使用RDD表示的基于数据并行的应用,三、Spark中的RDD关联关系的源码分析
一、Spark编程接口
预备知识:
1、Scala:是一种基于JVM的静态类型、函数式、面向对象的语言。Scala具有简洁(特别适合交互式使用)、有效(因为是静态类型)特点
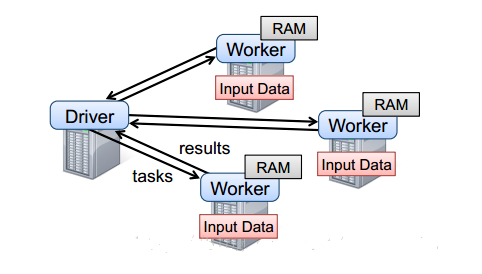
2、Driver定义了一个或多个RDD,并调用RDD上的动作。Worker是长时间运行的进程,将RDD分区以Java对象的形式缓存在内存中
3、闭包:相当于一个只有一个方法的紧凑对象(a compact object)
4、用户执行RDD操作时会提供参数,比如map传递一个闭包(closure,函数式编程中的概念)。Scala将闭包表示为Java对象,如果传递的参数是闭包,则这些对象被序列化,通过网络传输到其他节点上进行装载。
图-1
二、使用RDD表示的基于数据并行的应用
1、机器学习算法:每次迭代时执行一对map和reduce操作:逻辑回归、kmeans;两个不同的map/reduce步骤交替执行:EM;交替最小二乘矩阵分解和协同过滤算法
val points = spark.textFile(...)
.map(parsePoint).persist()
var w = // random initial vector
for (i <- 1 to ITERATIONS) {
val gradient = points.map{ p =>
p.x * (1/(1+exp(-p.y*(w dot p.x)))-1)*p.y
}.reduce((a,b) => a+b)
w -= gradient
}
注:定义一个名为points的缓存RDD,这是在文本文件上执行map转换之后得到的,即将每个文本行解析为一个Point对象;然后在points上反复执行map和reduce操作,每次迭代时通过对当前w的函数进行求和来计算梯度
2、RDD实现集群编程模型(MapReduce、Pregel、Hadoop)
1、MapReduce
data.flatMap(myMap)
.groupByKey()
.map((k, vs) => myReduce(k, vs))
如果任务包含combiner,则相应的代码为:
data.flatMap(myMap)
.reduceByKey(myCombiner)
.map((k, v) => myReduce(k, v))
注:ReduceByKey操作在mapper节点上执行部分聚集,与MapReduce的combiner类似
2、Pregel
3、Hadoop
三、Spark中的RDD关联关系的源码分析
表1 Spark中RDD的内部接口
| 操作 | 含义 |
|---|---|
| partitions() | 返回一组Partition对象,数据集的原子组成部分 |
| preferredLocations(p) | 根据数据存放的位置,返回分区p在哪些节点访问更快 |
| dependencies() | 返回一组依赖,描述了RDD的Lineage |
| iterator(p, parentIters) | 按照父分区的迭代器,逐个计算分区p的元素 |
| partitioner() | 返回RDD是否hash/range分区的元数据信息 |
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
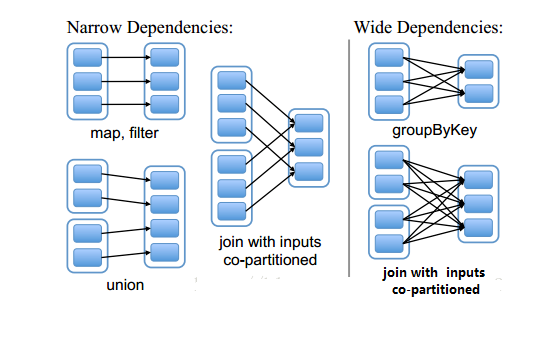
注:Dependency有两个子类,一个子类为窄依赖:NarrowDependency;一个为宽依赖ShuffleDependency
2、抽象类NarrowDependency:
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
注:NarrowDependency实现了getParents 重写了 rdd 函数。NarrowDependency有两个子类,一个是 OneToOneDependency,一个是 RangeDependency
NarrowDependency允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区
NarrowDependency能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区
2.1、OneToOneDependency:
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
注:getParents实现很简单,就是传进一个partitionId: Int,再把partitionId放在List里面传出去,即去parent RDD 中取与该RDD 相同 partitionID的数据
2.2、RangeDependency
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
注:某个parent RDD 从 inStart 开始的partition,逐个生成了 child RDD 从outStart 开始的partition,则计算方式为: partitionId - outStart + inStart ***
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
//获取shuffleID
val shuffleId: Int = _rdd.context.newShuffleId()
//向注册shuffleManager注册Shuffle信息
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
注:ShuffleDependency需要首先计算好所有父分区数据,然后在节点之间进行Shuffle
ShuffleDependency的Lineage链较长,采用检查点机制,将ShuffleDependency的RDD数据存到物理存储中可以实现优化,单个节点失效可以从物理存储中获取RDD数据,但是一般cpu的计算的速度比读取磁盘的速度快,这得看实际情况权衡。
1、writePartitionToCheckpointFile:把RDD一个Partition文件里面的数据写到一个Checkpoint文件里面:
def writePartitionToCheckpointFile[T: ClassTag](
path: String,
broadcastedConf: Broadcast[SerializableConfiguration],
blockSize: Int = -1)(ctx: TaskContext, iterator: Iterator[T]) {
val env = SparkEnv.get
//获取Checkpoint文件输出路径
val outputDir = new Path(path)
val fs = outputDir.getFileSystem(broadcastedConf.value.value)
//根据partitionId 生成 checkpointFileName
val finalOutputName = ReliableCheckpointRDD.checkpointFileName(ctx.partitionId())
//拼接路径与文件名
val finalOutputPath = new Path(outputDir, finalOutputName)
//生成临时输出路径
val tempOutputPath =
new Path(outputDir, s".$finalOutputName-attempt-${ctx.attemptNumber()}")
if (fs.exists(tempOutputPath)) {
throw new IOException(s"Checkpoint failed: temporary path $tempOutputPath already exists")
}
//得到块大小,默认为64MB
val bufferSize = env.conf.getInt("spark.buffer.size", 65536)
//得到文件输出流
val fileOutputStream = if (blockSize < 0) {
fs.create(tempOutputPath, false, bufferSize)
} else {
// This is mainly for testing purpose
fs.create(tempOutputPath, false, bufferSize,
fs.getDefaultReplication(fs.getWorkingDirectory), blockSize)
}
//序列化文件输出流
val serializer = env.serializer.newInstance()
val serializeStream = serializer.serializeStream(fileOutputStream)
Utils.tryWithSafeFinally {
//写数据
serializeStream.writeAll(iterator)
} {
serializeStream.close()
}
if (!fs.rename(tempOutputPath, finalOutputPath)) {
if (!fs.exists(finalOutputPath)) {
logInfo(s"Deleting tempOutputPath $tempOutputPath")
fs.delete(tempOutputPath, false)
throw new IOException("Checkpoint failed: failed to save output of task: " +
s"${ctx.attemptNumber()} and final output path does not exist: $finalOutputPath")
} else {
// Some other copy of this task must've finished before us and renamed it
logInfo(s"Final output path $finalOutputPath already exists; not overwriting it")
if (!fs.delete(tempOutputPath, false)) {
logWarning(s"Error deleting ${tempOutputPath}")
}
}
}
}
2、writeRDDToCheckpointDirectoryWrite,将一个RDD写入到多个checkpoint文件,并返回一个ReliableCheckpointRDD来代表这个RDD
def writeRDDToCheckpointDirectory[T: ClassTag](
originalRDD: RDD[T],
checkpointDir: String,
blockSize: Int = -1): ReliableCheckpointRDD[T] = {
val sc = originalRDD.sparkContext
// 生成 checkpoint文件 的输出路径
val checkpointDirPath = new Path(checkpointDir)
val fs = checkpointDirPath.getFileSystem(sc.hadoopConfiguration)
if (!fs.mkdirs(checkpointDirPath)) {
throw new SparkException(s"Failed to create checkpoint path $checkpointDirPath")
}
// 保存文件,并重新加载它作为一个RDD
val broadcastedConf = sc.broadcast(
new SerializableConfiguration(sc.hadoopConfiguration))
sc.runJob(originalRDD,
writePartitionToCheckpointFile[T](checkpointDirPath.toString, broadcastedConf) _)
if (originalRDD.partitioner.nonEmpty) {
writePartitionerToCheckpointDir(sc, originalRDD.partitioner.get, checkpointDirPath)
}
val newRDD = new ReliableCheckpointRDD[T](
sc, checkpointDirPath.toString, originalRDD.partitioner)
if (newRDD.partitions.length != originalRDD.partitions.length) {
throw new SparkException(
s"Checkpoint RDD $newRDD(${newRDD.partitions.length}) has different " +
s"number of partitions from original RDD $originalRDD(${originalRDD.partitions.length})")
}
newRDD
}