以下是在牛客网学习专项练习中有关数据结构和算法的内容,我把这些我觉得自己薄弱的地方摘抄整理在一起,方便自己以后的复习回顾,数据结构是衡量一个程序员好坏的标准,对于我这个非科班出身的人来说更是一道向前发展的拦路虎,需要尽早的学习和掌握,我相信一点点的做笔记一定可以将其攻克。

解析:二分查找需满足两个条件:数据有序、顺序存储。
折半查找通过比较序列中间元素的值,决定下一次查找的子区间。折半查找是减半分治法,因此它要求:
序列有序
能够快速获取中间元素的值,并将序列划分为左、右两个子序列
因为普通的有序链表获取中间元素非常低效(复杂度为O(n)),这使得分解问题的代价达到线性级,而不是顺序有序表的常数级。因此用有序链表达不到要求。
但是,普通的有序链表如果变化一下,也是可以实现折半查找的——具体用跳表skiplist 。基本思想就像为地铁增加快线。
这里的跳表没听说过,需要再开一个博客好好学学,在此先记下来。。
这题首先看看什么是二元查找树?它首先要是一棵二元树,在这基础上它或者是一棵空树;或者是具有下列性质的二元树: (1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值; (2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值; (3)左、右子树也分别为二元查找树
说到底它就是二叉查找树或者又叫二叉搜索树(Binary Search Tree)或者二叉排序树(Binary Sort Tree)或者简称BST

再复习一下什么是平衡二叉树(AVL)
父节点的左子树和右子树的高度之差不能大于1,也就是说不能高过1层,否则该树就失衡了,此时就要旋转节点,在编码时,我们可以记录当前节点的高度,比如空节点是-1,叶子节点是0,非叶子节点的height往根节点递增,比如在下图中我们认为树的高度为h=2。
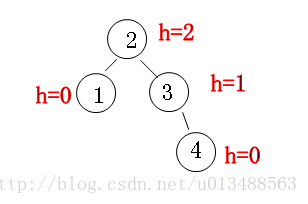
平衡二叉树涉及到“树节点”的旋转的知识,这个需要以后专门再学习。
说到这再复习一下什么是满二叉树?完全二叉树?什么又是堆?
满二叉树:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点(最后一层上的无子结点的结点为叶子结点)。也可以这样理解,除叶子结点外的所有结点均有两个子结点。节点数达到最大值。所有叶子结点必须在同一层上.
完全二叉树:若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。
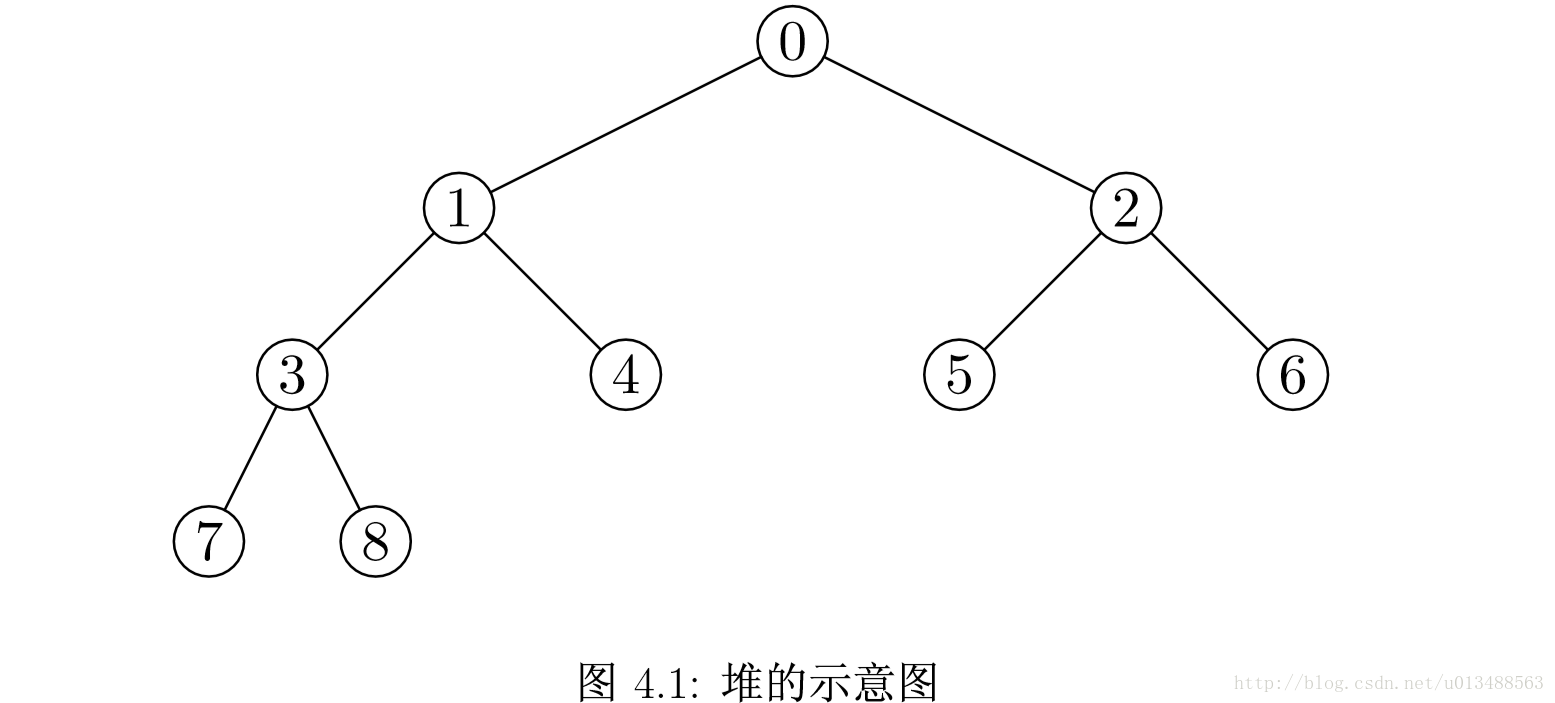
上图是一个小顶堆。堆数据结构本质是一个完全二叉树。堆又分为最大堆和最小堆。如果是最大堆,对于每个结点,都有结点的值大于两个孩子结点的值。如果是最小堆,那么对于每个结点,都有结点的值小于孩子结点的值。由此,可以得到一个推论,那就是,最大堆的根结点,必然是堆中的最大值,同理,最小堆的根结点,也必然是堆中的最小值。给定某一个结点,假设它的下标为i,那么它的左孩子结点的下标就是2i + 1,右孩子结点的下标就是2i + 2,它的父结点为(i−1)/2。
有关树节点个数,树的深度以及叶子节点个数的计算这里暂且不复习,之后再开一个博客专门复习一下。
再来回到题目中,针对折半查找或者二分查找最坏的情况就是log(n+1)向上取整,也即在时间性能最坏情况下,为目标结点位于最后一层叶子节点的情况,此时的查找时间为树的深度,即为log(n+1)向上取整(以2为底)。二分查找在查找失败时所需比较的关键字个数不超过判定树的深度,在最坏的情况下查找成功的比较次数也不超过判定树的深度
针对二叉排序树(BST)或二元查找树时间性能最坏的情况是退化成只有左子树或者右子树情况下也即即树退化为一条链,线性查找,失去了树的优点,此时,最长查找时间为目标结点位于叶子节点,即为n。而二叉排序树的时间复杂度log(n)(以2为底)

其推导过程可以学习下:
二分查找因为每次都是从中间点开始查找,所以最坏情况是目标元素存在于最边缘的情况。
比如1~9,最坏情况就是1或者9,当然4,6这种也算是边缘(中心的边缘)。
因为二分查找每次排除掉一半的不适合值,所以对于n个元素的情况:
一次二分剩下:n/2
两次二分剩下:n/2/2 = n/4
m次二分剩下:n/(2^m)
在最坏情况下是在排除到只剩下最后一个值之后得到结果,所以为
n/(2^m)=1;
2^m=n;
所以时间复杂度为:log(n)
找了一张关于比较全的关于各种数据结构的时间复杂度,不过有待再去理解,这里先贴上来
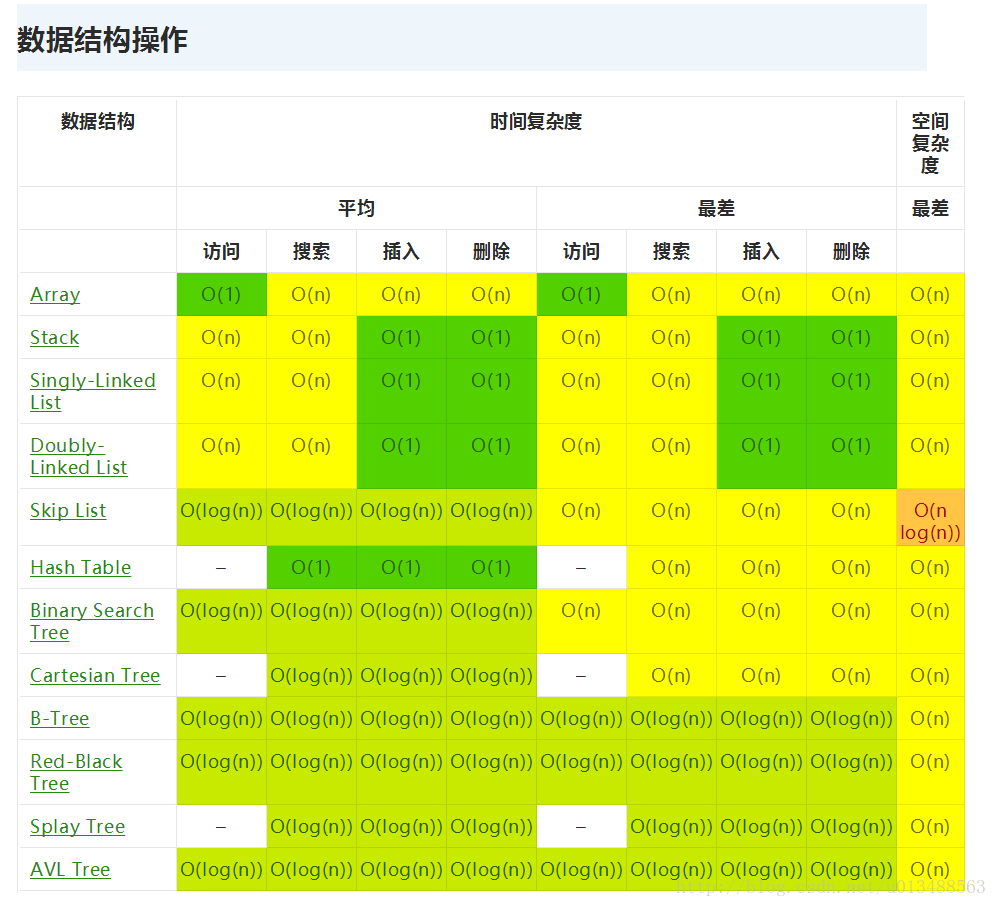
常用的排序、查找算法的时间复杂度和空间复杂度,通过此链接也可以查看学习。(但是中间可能有误,还需要甄别)
先对该题进行分析:分块查找是折半查找和顺序查找的一种改进方法,折半查找虽然具有很好的性能,但其前提条件时线性表顺序存储而且按照关键码排序,这一前提条件在结点树很大且表元素动态变化时是难以满足的。而顺序查找可以解决表元素动态变化的要求,但查找效率很低。如果既要保持对线性表的查找具有较快的速度,又要能够满足表元素动态变化的要求,则可采用分块查找的方法。
分块查找的速度虽然不如折半查找算法,但比顺序查找算法快得多,同时又不需要对全部节点进行排序。当节点很多且块数很大时,对索引表可以采用折半查找,这样能够进一步提高查找的速度。
分块查找由于只要求索引表是有序的,对块内节点没有排序要求,因此特别适合于节点动态变化的情况。当增加或减少节以及节点的关键码改变时,只需将该节点调整到所在的块即可。在空间复杂性上,分块查找的主要代价是增加了一个辅助数组。
再复习一下“分块查找”:又称为索引查找,提到索引很容易地联想到数据库中的索引,建立了索引,可以大大提高数据库的查询速度。分块查找,是一种介于顺序查找和二分查找之间的一种查找方法。
分块查找的基本思想是:
首先查找索引表,可用二分查找或顺序查找(因为块间是有序的,可以用二分查找),然后根据块首指针找到相应的块,并在确定的块中进行顺序查找。
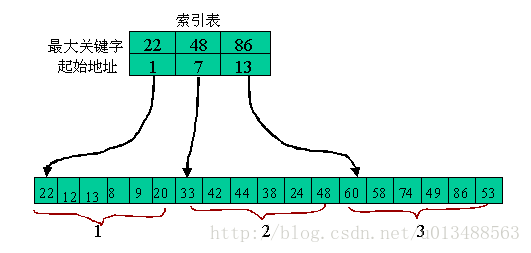
分块查找的过程分两步:
(1)先确定块,确定块的查找可用顺序查找或折半查找(因为索引表中的关键字项是有序的)。
(2)再在块中查找,块内的查找只能用顺序查找(块内的关键字是无序的)。
