1.学习总结
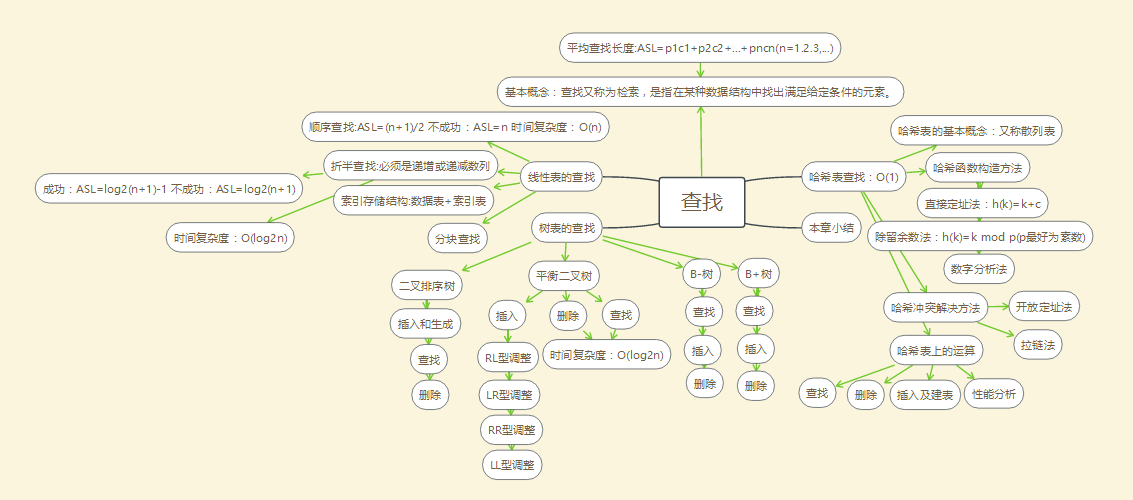
1.1查找的思维导图
1.2.查找学体会
(1)理解查找的基本概念,包括静态查找表和动态查找表、内查找和外查找之间的差异以及平均查找长度等。
(2)重点掌握线性表上各种查找算法,包括顺序查找、折半查找和分块查找的基本思路、算法实现和查找效率等。
(3)掌握各种树表的查找算法,包括二叉排序树、AVL树、B-树和B+树的基本思路、算法实现和查找效率等。
(4)掌握哈希表查找技术以及哈希表与其他存储方式的本质区别。
(5)灵活运用各种查找方法解决一些综合应用问题。
2.PTA实验作业
2.1.1题目1:是否二叉搜索树
2.1.2设计思路
对于任意结点,所有左边的结点必须小于当前结点,所有右边结点必须大于当前结点,因此可从根结点开始判断,所有结点的值都应该落在一个区间内,自上而下传递区间的最小值和最大值。进入左子树时,更新最大值,进入右子树,更新最小值。
2.1.3代码截图

2.1.4PTA提交列表说明
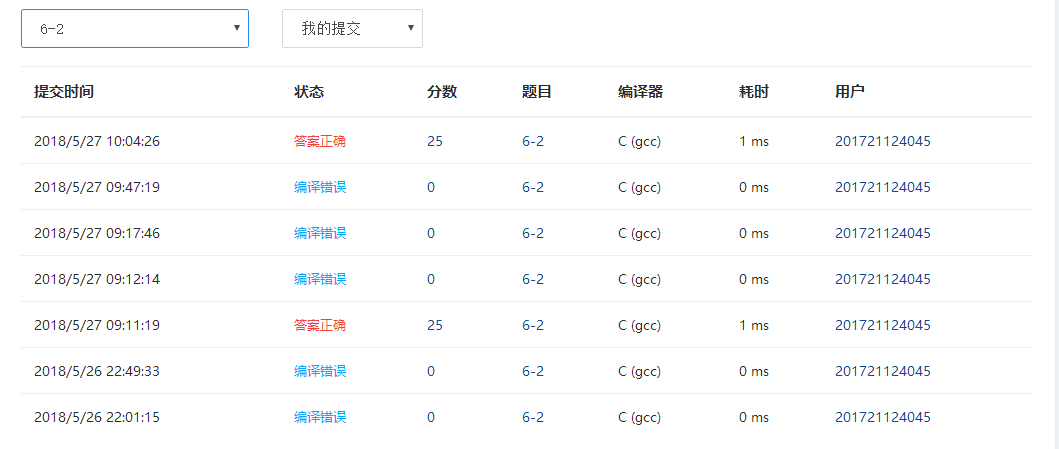
一开始是编译错误,归根结底在于没处理好细节上的问题,如字母的大小写问题,和对应题目代码要求的格式问题。成功一次之后想要加以修改后又出现了编译错误,经过反复查证,发现问题出在了对二叉搜索树性质的淡忘上。搜索二叉树非空左子树所有键值小于根结点的值,非空右子树的所有键值都大于跟结点的值,比较所有左子树的键值而不是单纯的比较左右子结点与根结点的值。
2.2.1题目2:二叉搜索树中的最近公共祖先
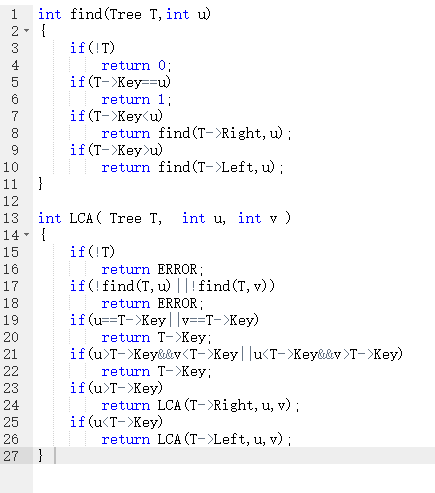
2.2.2设计思路
必须考虑完所有情况:
u,v不在树中
u,v在树中:(1)u,v都在左子树上
(2)u,v都在右子树上
(3)u,v一个在左一个在右
(4)u,v有一个在跟上
2.2.3代码截图
2.2.4PTA提交列表说明
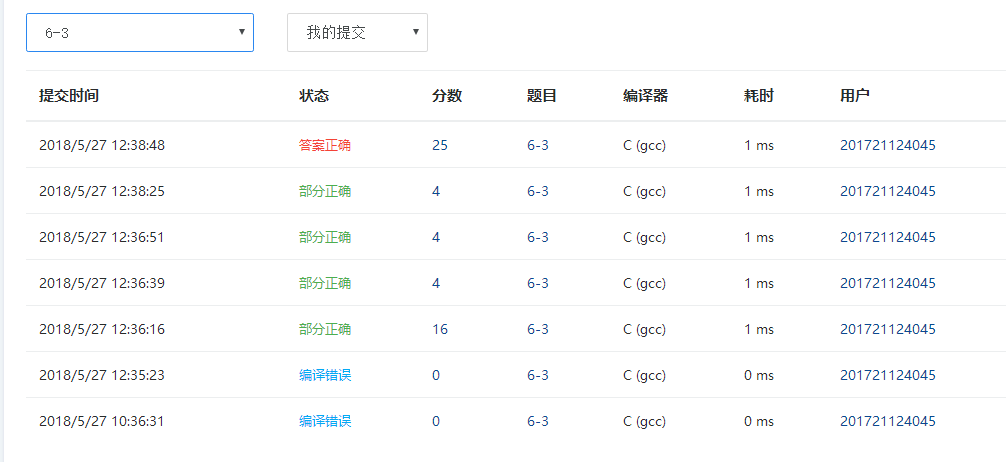
一开始的编译错误问题在于英文分号打成了中文分号,经过两次错误后观察纠正。后面的部分正确的所在问题在于没有考虑完整所有情况的出现,经过一步步完善各种情况后才有了最终的结果。
2.3.1题目3:航空公司VIP客户查询
2.3.2设计思路
该题使用的是二叉树结构存储数据。身份证号码映射出去,随机度最高的也就最后一位校验位。
2.3.3代码截图
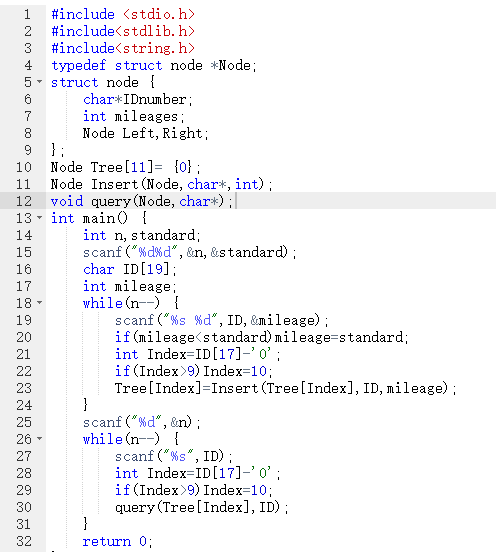

2.3.4PTA提交列表说明
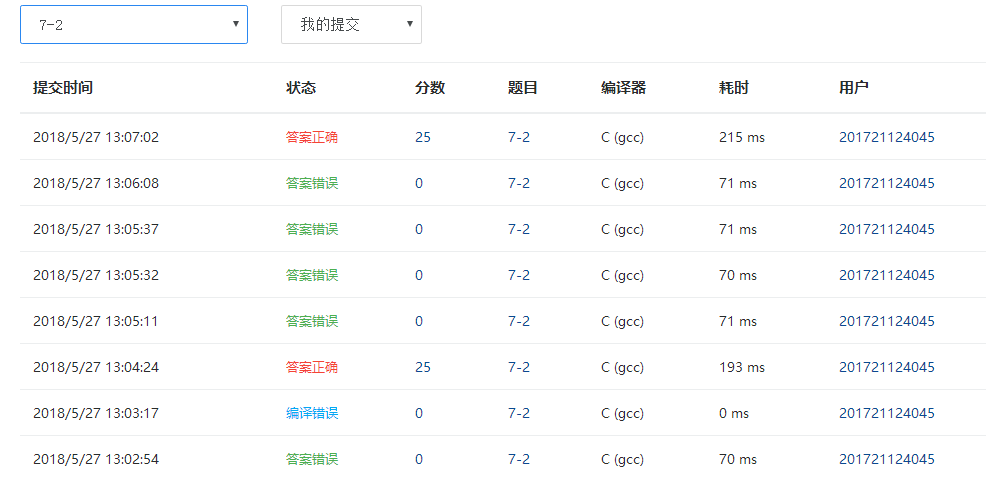
在有了思路后出现答案错误是因为没有严格按照题目的输出格式要求去写,以及对题目所有要求的考虑不全,经过一步步改善纠正,才有分数。
3.截图本周题目集的PTA最后排名

4.阅读代码
哈希表实现查找代码:
#include<iostream>
using namespace std;
typedef int Keytype; //每次都是取质数最接近的质数
struct Hash { Keytype * elem; //记录哈希表中的元素
bool * isfull; //记录哈希表是否有元素了
int count; //哈希表中元素的个数
int sizeindex; };
bool searchHash(Hash t, Keytype k, int & p, int &c,int * hashsize);
bool insertHash(Hash & t, Keytype k, int * hashsize);
bool DeleteHash(Hash & t, Keytype k, int * hashsize);
void print(Hash t, int * hashsize);
#include"linear.h" //查找对应的关键字
bool searchHash(Hash t, Keytype k, int & p,int &c,int * hashsize) {
p = k%hashsize[t.sizeindex];
while (t.isfull[p] && t.elem[p] != k && c < hashsize[t.sizeindex]-1) {
++c; //继续往下寻找下一个散列结点
p=(k+c) % hashsize[t.sizeindex];
}
if (t.elem[p] == k) {
return true;
}
return false;
}
bool insertHash(Hash & t, Keytype k, int * hashsize) {
int p; int c = 0;
if (searchHash(t, k, p,c,hashsize)) {
return false;
}
else if (c==hashsize[t.sizeindex]-1) {//此时哈希表已经满,得重新分配了
//首先是把之前的内容保存起来
int temp; temp=hashsize[t.sizeindex];
Keytype * elem = new Keytype[hashsize[t.sizeindex]];
bool * isfull=new bool[hashsize[t.sizeindex]];
for (int i = 0; i < hashsize[t.sizeindex]; ++i) {
elem[i] = t.elem[i];
isfull[i] = t.isfull[i];
}
delete t.elem;
delete t.isfull;
++t.sizeindex; //重新分配空间
t.elem= new Keytype[hashsize[t.sizeindex]];
t.isfull=new bool[hashsize[t.sizeindex]];
int i;
for (i = 0; i < temp; ++i) {
t.elem[i]=elem[i];
t.isfull[i] = isfull[i];
}
for (i=0; i < hashsize[t.sizeindex]; ++i) {
t.isfull[i] = false;
}
}
else {
//cout << p << endl;
//直接插入对应的位置
t.elem[p] = k;
++t.count;
t.isfull[p] = true;
}
}
bool DeleteHash(Hash & t, Keytype k, int * hashsize) {
int p;
int c = 0;
if (!searchHash(t, k, p, c,hashsize)) { //没找到要删除的元素
return false;
}
else {
t.isfull[p] = false;
--t.count;
}
}
void print(Hash t, int * hashsize) {
cout << "当前的表的长度:" << hashsize[t.sizeindex] << endl;
cout << "Hash表的元素个数为:" << t.count << endl;
cout << "打印整个表:" << endl;
for (int i = 0; i < hashsize[t.sizeindex]; ++i) {
if(t.isfull[i]) cout << t.elem[i] << " ";
else { cout << "^" << " ";
}
}
cout << endl;
}