1、Representation Learning
表示学习:Feature Engineering,学习更好的表示特征向量的方式
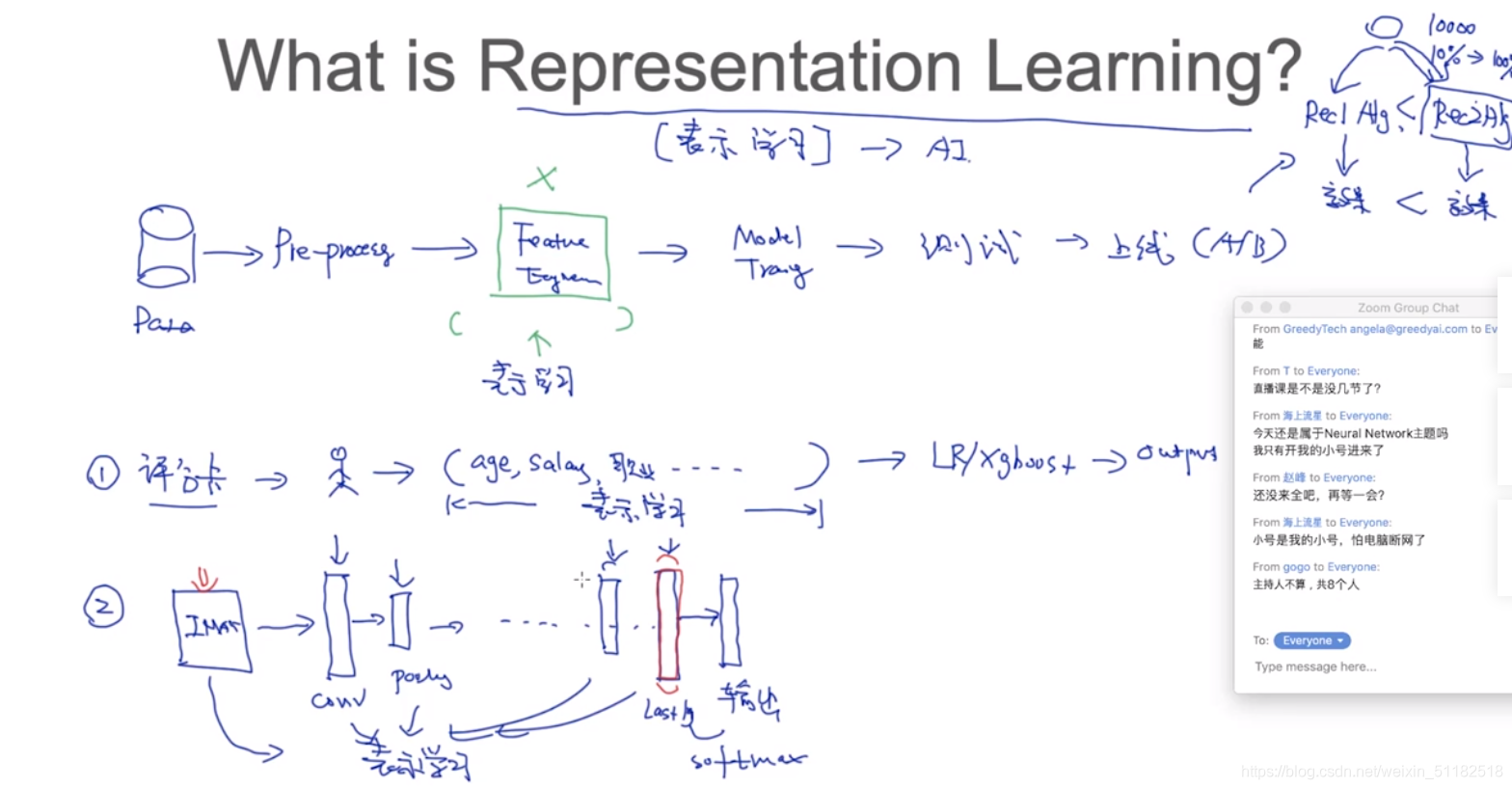
如何去评估一个表示优于一个表示?
PCA:学习在低维空间中更好地方法
The better representation lies in lower dimensional manifold
2、What makes a good representation
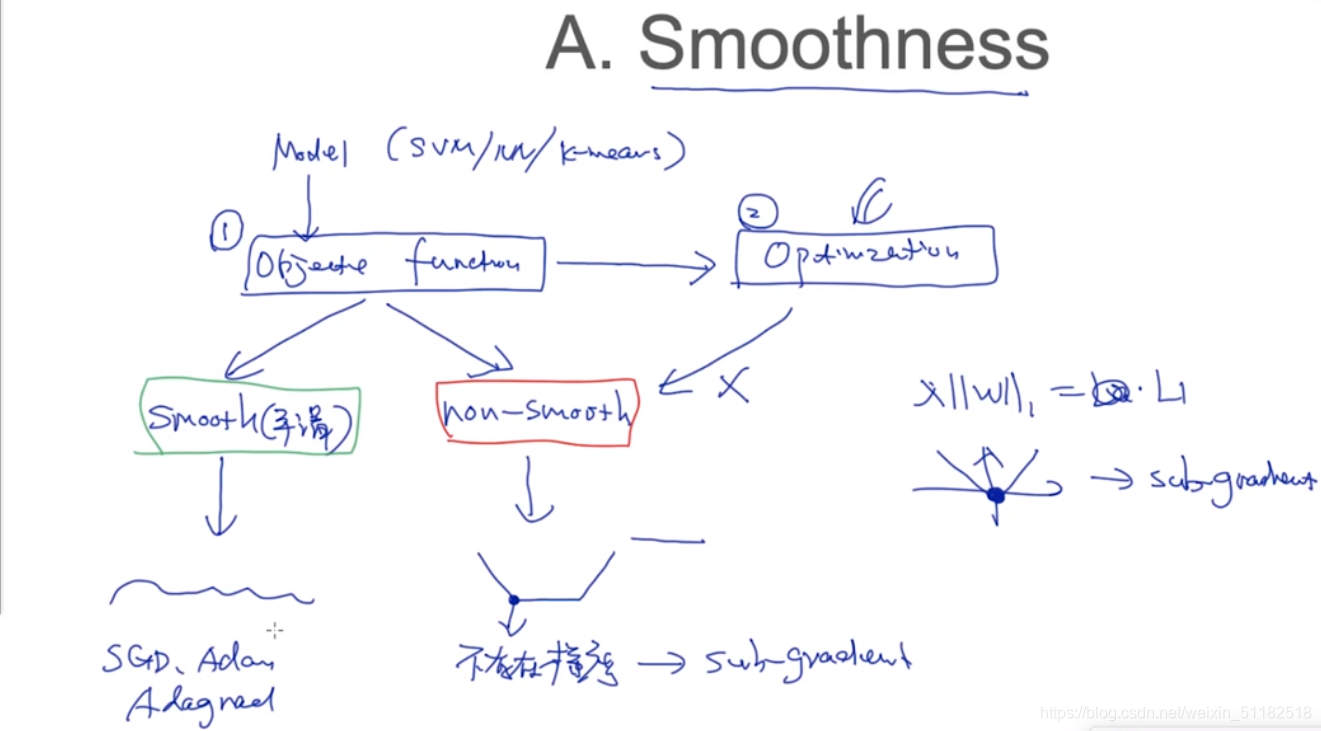
2.1 Smoothness
不平滑的函数很难使用梯度下降去找到最优解
2.2 Multiple Explanatory Factors
目的:抽取出不相干的信息
合理的表达出样本的各项特性
对于一个人的照片:背景,人,亮度,角度
经过特征工程后,对于一个100维的vector,好的representation可以用前25维表示人的特征,再用25维表示背景特征,再用25维表示亮度特征,最后25维表示角度特征
可解释性强
如何去度量该性质,可以度量每个不相关特征的协方差矩阵,理想的协方差矩阵应该是每个特征之和自己有相关性,和其他特征的协方差矩阵的值为0.
如何去判定vector每个值属于哪个特征:单独设计四个不同的网络,对于每个特征都定义一个损失函数,去识别各个特征。
2.3 Hierarchical Representation 层级的结构
需要让NN具备transfer learning的能力
底层的特征是碎片化特征,网络越深,特征表示越具体。
对于底层的碎片化特征,即便更换输入的任务,碎片化特征之间的共性(sharing)是很强的。这种能力使得同样的网络可以用于解决其他的任务,满足transfer learning。
low-level feature ==== > mid-level feature ======= > high-level feature
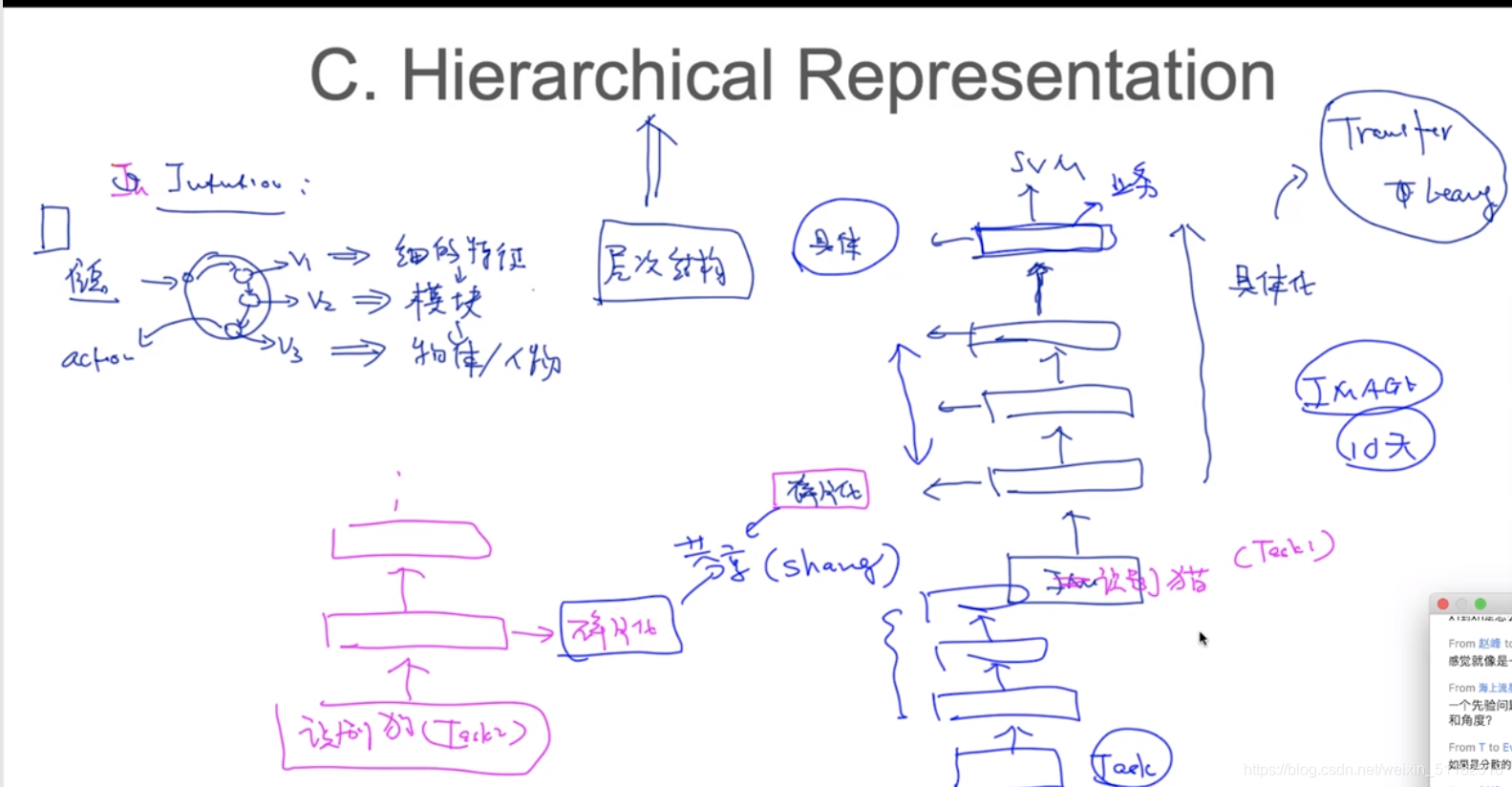
Word2Vec也属于transfer learning的产物。
2.4 Shared Factors Across Tasks
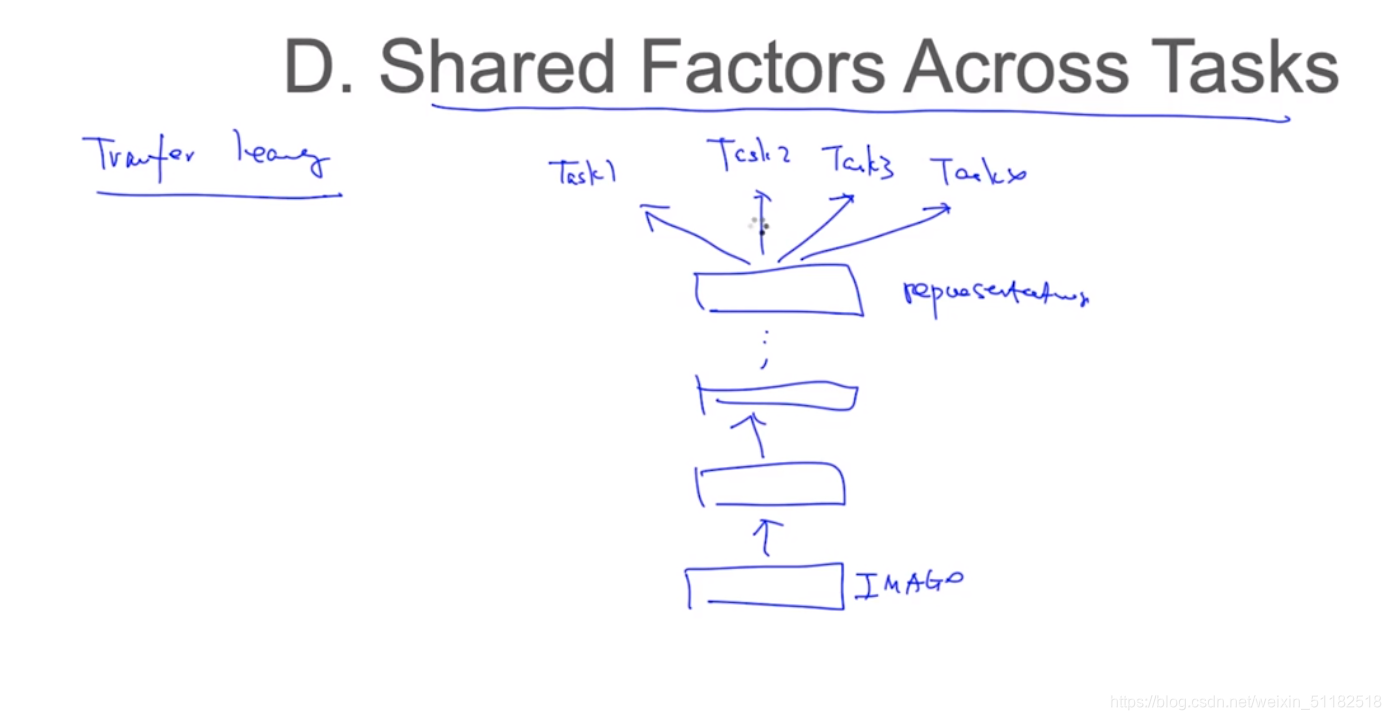
希望好的表示可以运用在不同的任务上
2.5 Low Dimensional Manifold
好的表示一定会落在更低维度的空间里
Word2vec也是个降维的操作,从|V|到100,200,300维度
2.6 Temporal/Spacial Coherence ——时间/空间一致性
Temporal
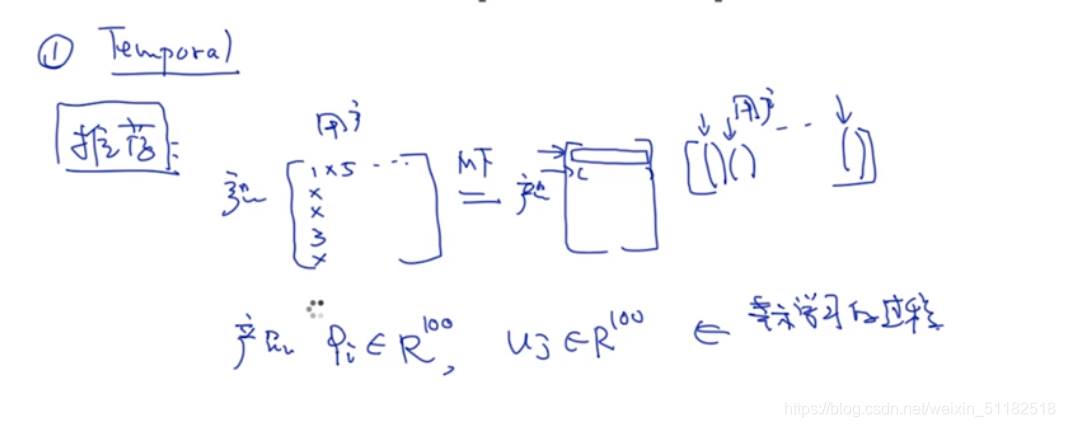

在时间维度上,短时间内的output不会差别太大
方式:使用正则
Spacial coherence
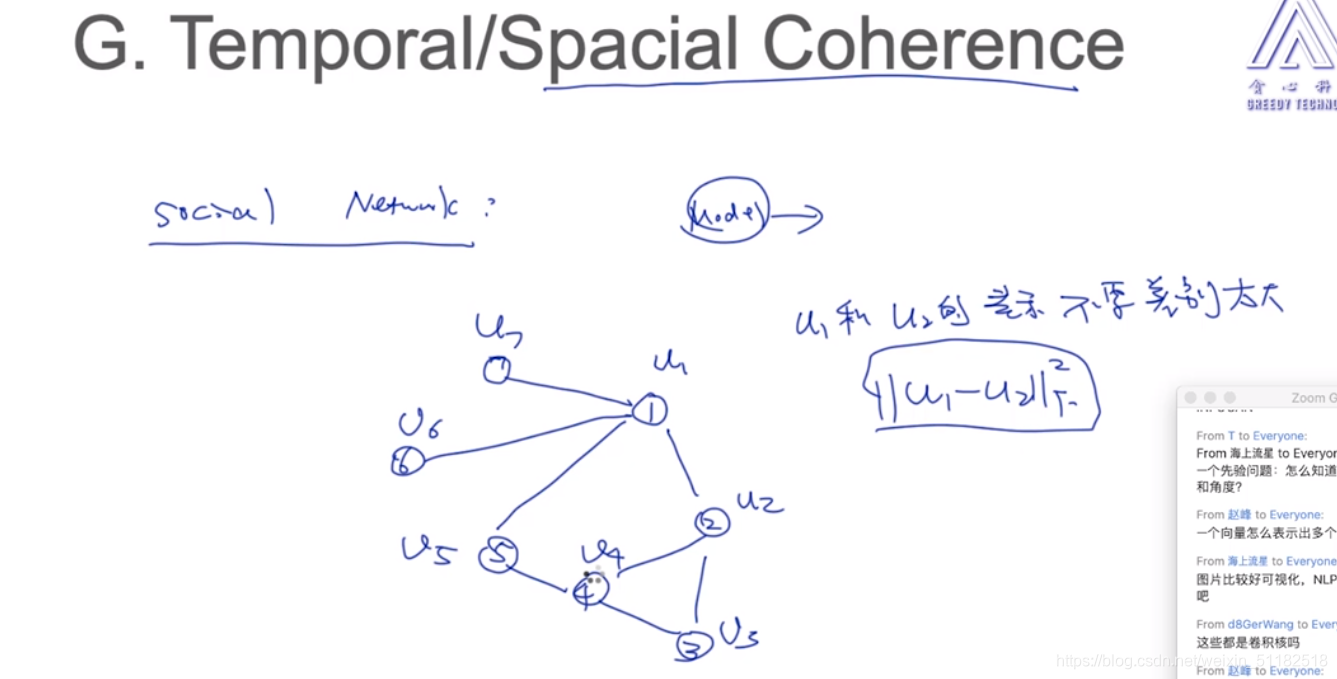
相邻的几个特征点不要差别太大
2.7 Sparsity
好的模型都具有一定的稀疏性:可解释性强

降维(PCA降维)
- 丢失信息
- 去掉 noise
3、About Deep learning
3.1 Why Deep?
Deep learning 是一个框架,framework

A deep architecture represent certain functions more compact
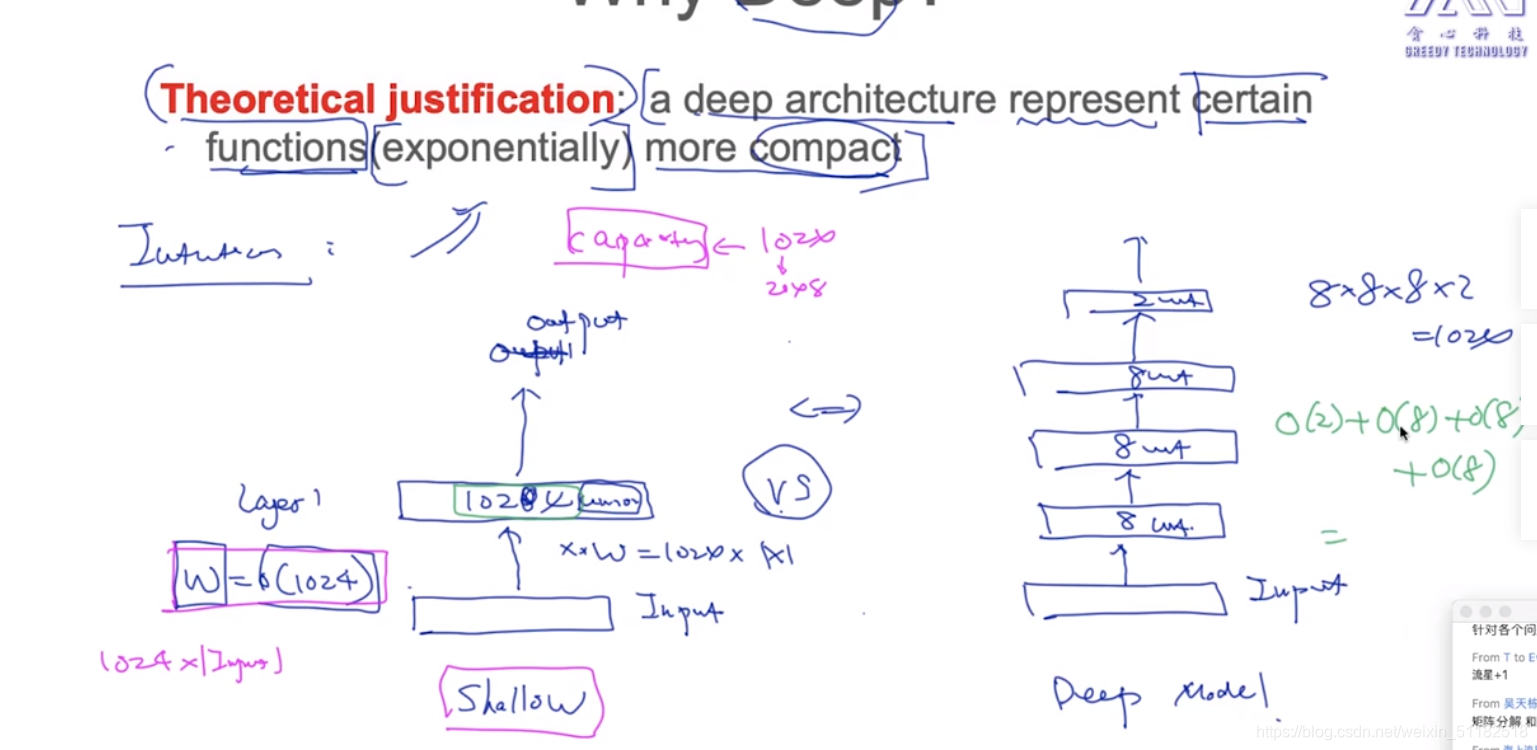
exponentially compact: 越深的网络,可以用越少的参数表达出更多的变量
3.2 Why deep learning hard to train?
Gradient Vanishing,层数越多,梯度会变得很小,很难更新。
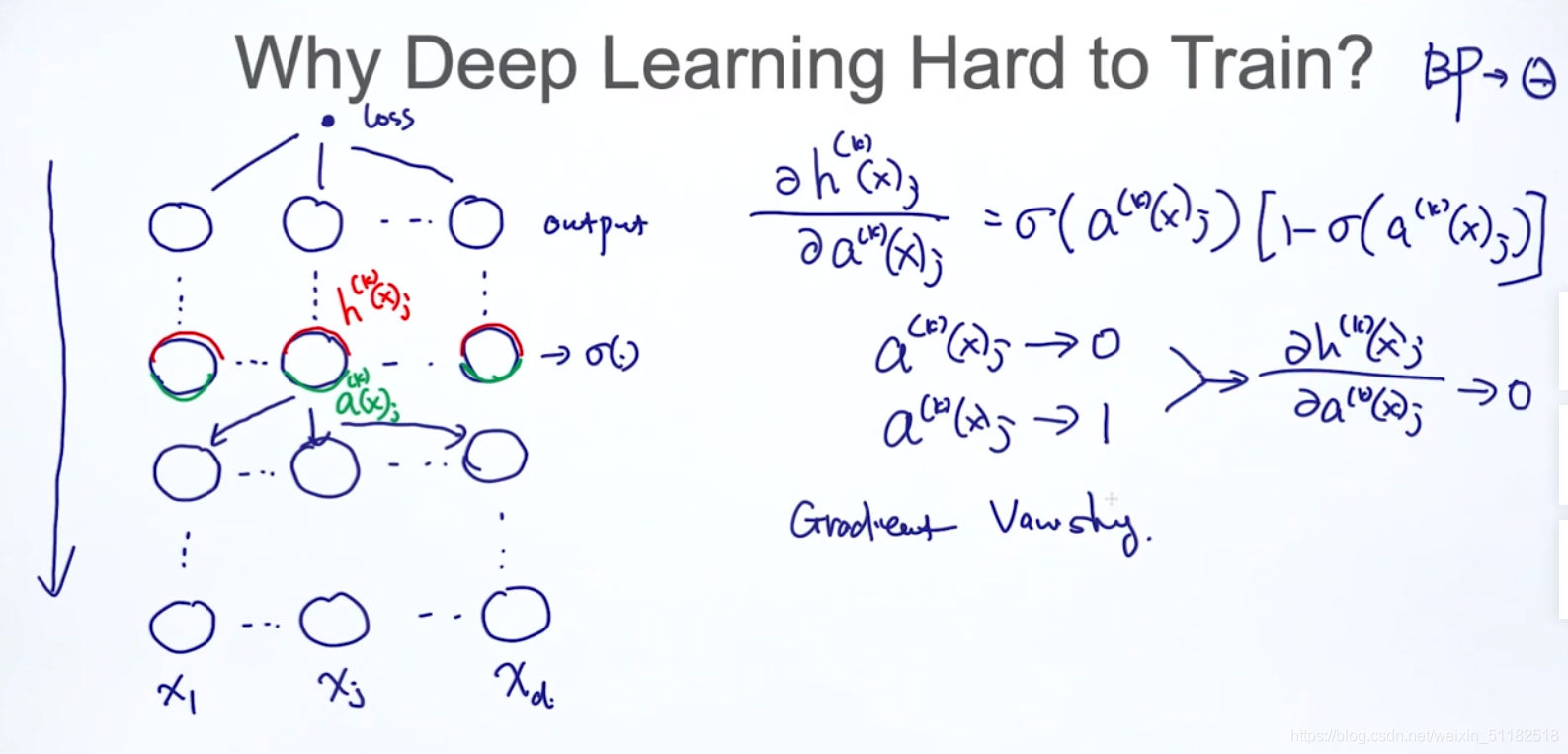
3.3 Ways to solve Training
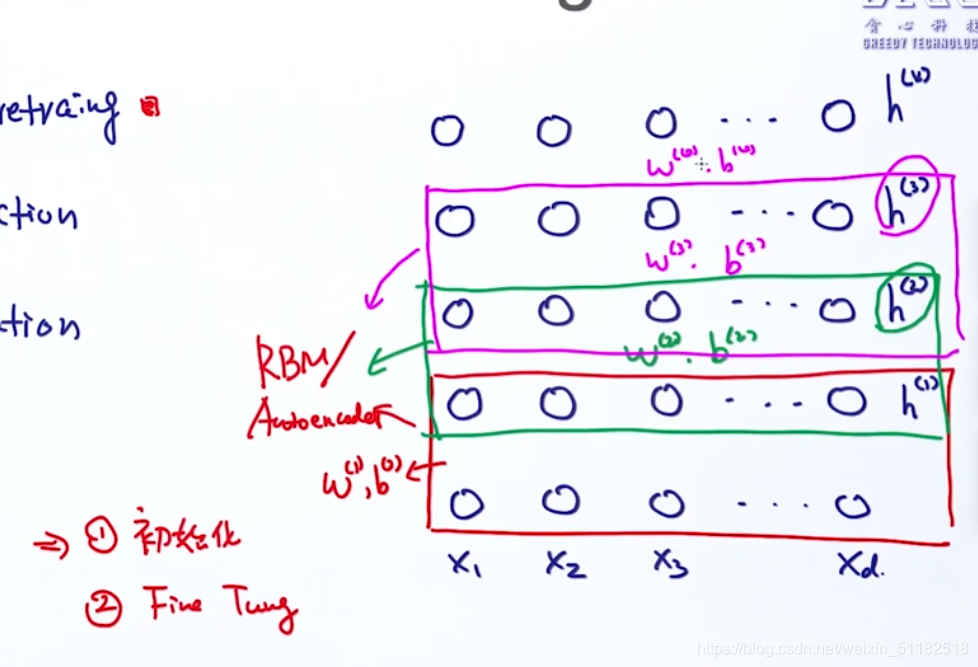
- 1、Layer-wise pre-training:一层一层的训练模型
- 2、Activation function:ReLU
- 3、Better optimization: Adagrad, Adam,LSTM
- 4、Larger data:样本数量足够多,梯度可能会没有那么小。
Layer-wise pre training
- 初始化
- fine tune:一些监督学习的样本
- 给定x输入,通过无监督学习训练第一层网络,note:可以使用auto encoder,学习到第一层网络的参数
- 把第一层的输出当作第二层的输入,继续训练
- 直到把每一层都学习完