摘要:人工智能一个主要开放问题是增量学习系统的开发,随着时间的推移,从数据流中学习越来越多的概念。这里引入一种新的策略iCaRL,以类增量的方式进行学习:开始只有少量的类,逐步添加新的类。iCaRL同时学习强分类器和数据表示。过去的工作受限于固定数据的表示,因此与深度学习架构不兼容。
一、介绍
视觉系统本质是递增的:新的视觉信息不断合并,现有的知识被保留下来。例如一个参观动物园的孩子了解新的动物但不会忘记家里的宠物。相比之下,大多人工识别系统智能在批量设置中训练,所有类已知,所有类的训练数据在同一时间读取,随机顺序访问。
随着视觉领域向人工智能发展,需要更灵活的策略处理真实世界的分类的大规模和动态性。至少有可用新类训练数据时,分类系统可用增量的学习到新类,将这种场景称为类增量学习。类增量算法有如下三个性质:1、可以训练不同时间出现不同类的数据流;2、为观察到的类提供一个有竞争力的多类分类器;3、对计算和内存的需求是有限的,或增长的非常慢。前两个是类增量学习的本质,第三个删除了一些算法,比如存储所有的训练样本,有新数据就重新训练。
目前还没有令人满意的类增量学习算法,现有技术违反了1和2,只能处理固定数量的类或需要同时提供所有培训数据。人们尝试从类增量的数据流中训练分类器,例如通过随机梯度下降优化。但这会导致分类的准确率迅速恶化,这种效应被称为灾难性遗忘或灾难性干扰。
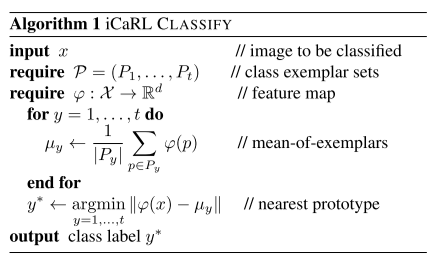
现有技术局限于固定数据,不同同时学习分类器和特征表示的深度框架中,在分类准确率方面缺乏竞争力。在这里介绍ICARL,在类增量的设定中同时学习分类器和特征表示。为了满足上述标准,引入三个组件:1、根据最接近样本均值的规则进行分类;2、群体中优先范例选择;3、使用知识蒸馏和原型演练进行特征学习。
第2部分详述步骤,第3部分将方法放入先前的工作环境中,第4部分在CIFAR和ImageNet数据集上实验,第5部分讨论仍存在的限制和未来工作。
二、方法
2.1 算法流程