


比如我们今天的案例,豆瓣电影分类页面。根本没有什么翻页,需要点击“加载更多”新的电影信息,前面的黑科技瞬间被秒……

又比如知乎关注的人列表页面:
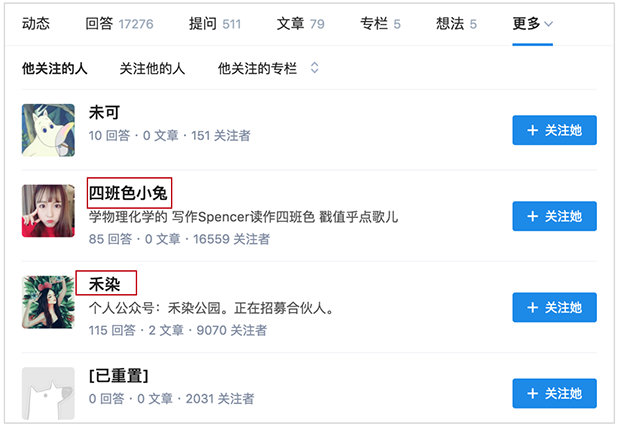
我复制了其中两个人昵称的 xpath:
//*[@id="Popover-35130-11238-toggle"]/a
//*[@id="Popover-35130-42416-toggle"]/a
竟然需要 ID 这种恶心的东西,规律失效。


我们以豆瓣励志分类下的电影为例,链接在这里:
https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=%E5%8A%B1%E5%BF%97


上面的标记应该是“分类”,而不是“排行榜”,更正一下。
首先要告诉你的是,这种动态加载的页面,一般数据会在Network的 JS或者 XHR 类目里。
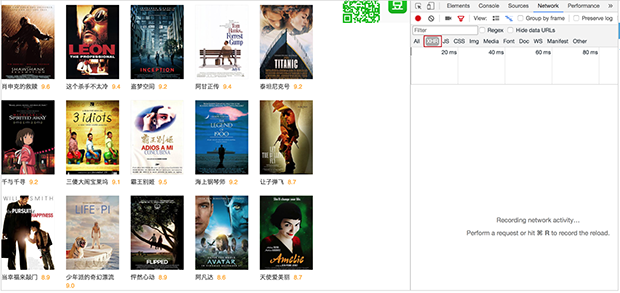
我们打开开发者工具,看这一页的 XHR里没有任何文件,然后点击加载更多按钮,看它给我们返回什么信息。

咦?返回了一个新的文件,出于好奇,我们有必要看看究竟
右键点击 >> Open in new tab
有的网站 返回的 JS、XHR 信息比较多,需要你去尝试和筛选。

这个 json 页面看起来就很亲切了,包含电影名称、导演、评分、演员、链接等数据。最关键的是,我仔细看了一遍页面后发现,这一页的电影信息,正好是新加载出来的所有电影的信息。
你的网页看 json 很乱?不要着急,那是你的chrome没有安装jsonview这个插件。证号为你准备好了,子按下方的云盘下载、安装就好:
链接:http://pan.baidu.com/s/1nvefj0t 密码:13pm

好了,又加载了两次,不出意料地又加载出了两页 XHR 信息,于是,满怀期待地分别打开它们。新加载的两个页面,和网页显示的电影信息完全相同。
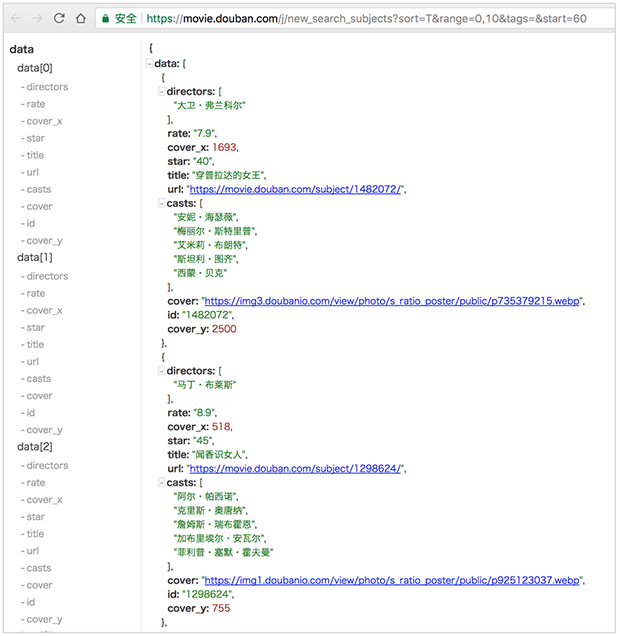
我们再来看看 XHR 加载的这几个页面的 url:
#第二页
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start=20
#第三页
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start=40
#第四页
https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start=60
比较后就可以轻松发现,这些页面的 url 是有规律的:只有最后 start= 后面的数字在变化,而且是以20为步长递增的,20正好对应每次加载出来的电影数量。
于是我们可以轻松地写出页面循环来爬取:
for a in range(3):
url='https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start={}'.format(a*20)
# 用 a*20 表示每个页面按 20 的步长递增,只示例3个页面,你可以按需求增加。
按照前面的套路写出代码,并得到结果:
import requests
import json
import time
for a in range(3):
url_visit = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=&start={}'.format(a*20)
file = requests.get(url_visit).json() #这里跟之前的不一样,因为返回的是 json 文件
time.sleep(2)
for i in range(20):
dict=file['data'][i] #取出字典中 'data' 下第 [i] 部电影的信息
urlname=dict['url']
title=dict['title']
rate=dict['rate']
cast=dict['casts']
print('{} {} {} {}\n'.format(title,rate,' '.join(cast),urlname))
爬取的数据如下:

解释一下代码中的一些细节:
file = requests.get(url).json()
之前我们用的 .text 是需要网页返回文本的信息,而这里返回的是 json文件所以用 .json()
dict=file['data'][i]
urlname=dict['url']
取出字典中的值,需要在方括号中指明值对应的键
' '.join(cast)
因为有多名演员,这里用了 join() 函数,在字符串中间加入空格分隔。
当然,你也可以把爬下来的信息存到本地:

对电影评分进行排序,不久得到了所有的高分电影吗?


 最后,推荐大家加下我的Python学习交流群:663033228 无论你是大牛还是小白,是想转行还是想入行都可以来了解一起进步一起学习!裙内有开发工具,很多干货和技术资料分享!
最后,推荐大家加下我的Python学习交流群:663033228 无论你是大牛还是小白,是想转行还是想入行都可以来了解一起进步一起学习!裙内有开发工具,很多干货和技术资料分享!