上一篇爬取到了5000多部电影的信息 ,并把电影数据保存到了movies中,其中每一项都是一个字典,包含评分rate,电影标题title,详情页URL,封面图片链接,豆瓣电影编号id等,此时我需要进一步爬取各个电影的对应的详情页,其中各个信息。导演,简介,语言,片长等
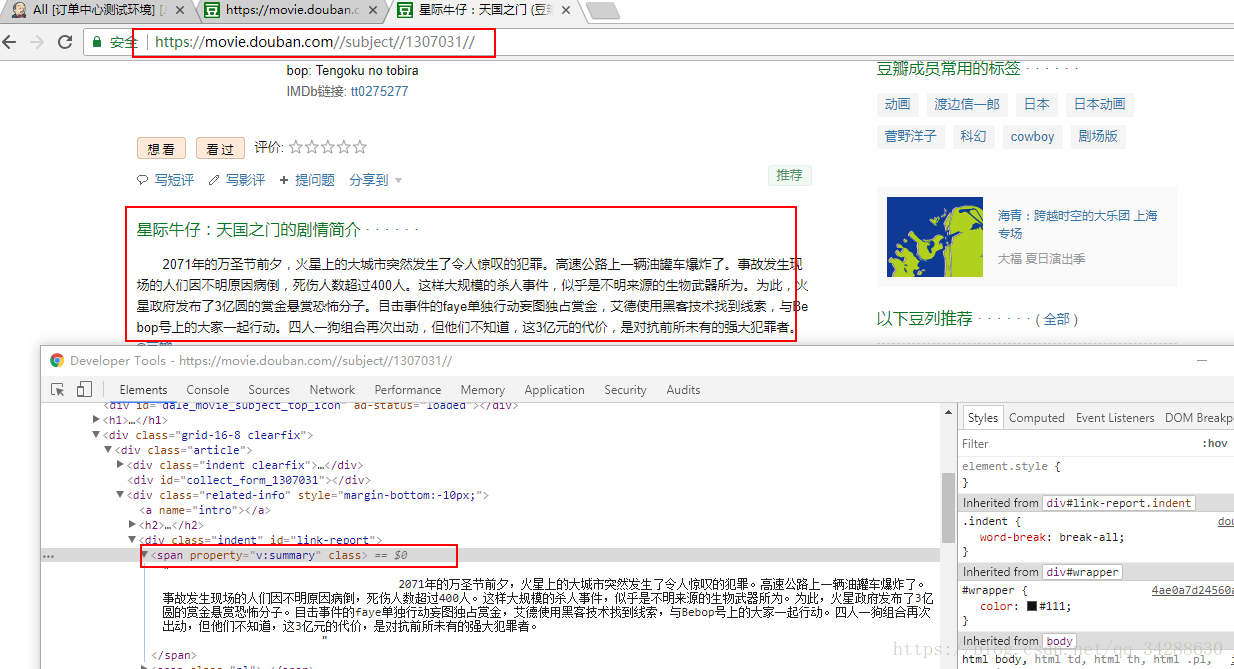
首先遍历movies中的每一个url,请求url进入每部电影的详情页,分别获取其简介
看代码:
# coding=utf-8
import urllib
import urllib2
import json
import sys
import time
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
# 获取所有标签
url = 'https://movie.douban.com/j/search_tags?type=movie&source='
request = urllib2.Request(url=url)
response = urllib2.urlopen(request,timeout=20)
result = response.read()
# 加载json为字典
result = json.loads(result)
tags = result['tags']
# 定义一个列表存储电影的基本信息
movies = []
# 处理每一个tag
for tag in tags:
start = 0
# 不断请求每一页,直到返回结果为空 空 说明遍历的此tag下的电影已经没了
while True:
# 此时遍历每一个标签每个标签的请求参数需要拼接, 包括标签和开始编号
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag='+tag+'&sort=recommend&page_limit=20&page_start='+str(start)
print url
request = urllib2.Request(url=url)
response = urllib2.urlopen(request,timeout=20)
result =response.read()
result = json.loads(result)
# 先在浏览器中请求上面的API,观察json的结构
# 然后在python中取出自己想要的数据
result = result['subjects']
# 返回结果为空的话,说明已经没有数据了
# 完成一个标签的处理退出循环
if len(result) ==0:
break
# 将每一条数据加入movies中
for item in result:
movies.append(item)
# 使用的循环条件得修改条件
#这里需要修改start
start += 20
# 看看一共获得了多少电影
print len(movies)
# 将获取每部电影的详情页
# 请求每部电影的详情页
for x in xrange(0,len(movies)):
url = movies[x]['url']
request = urllib2.Request(url=url)
response = urllib2.urlopen(request,timeout=20)
result = response.read()
# 使用BeautifulSoup解析HTML
html = BeautifulSoup(result)
# 提取电影简介
# 捕捉异常,有的电影详情页中并没有电影简介
try:
description = html.find_all("span",attrs={"property":"v:summary"})[0].get_text()
except Exception,e :
# 没有提取到简介,则简介为空
movies[x]['description'] = ''
else:
movies[x]['description'] = description
finally:
pass
# 适当休息,避免请求频发被禁止,报403 Forbidden错误
time.sleep(0.5)
以上代码可以获取详情页面的每一步电影简介。