最近闲来无事 学习python爬虫,爬取豆瓣电影
一、分析网页
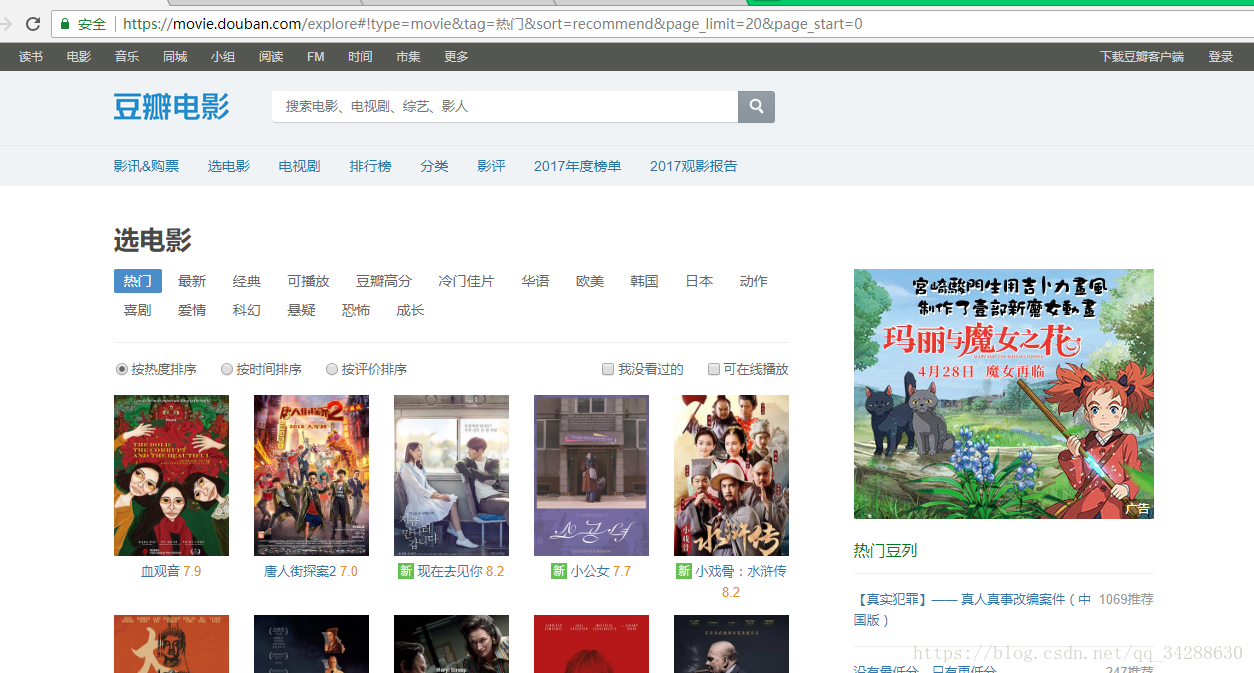
打开豆瓣电影 按F12 ,刷新豆瓣网页,会发现Network的XHR中有链接
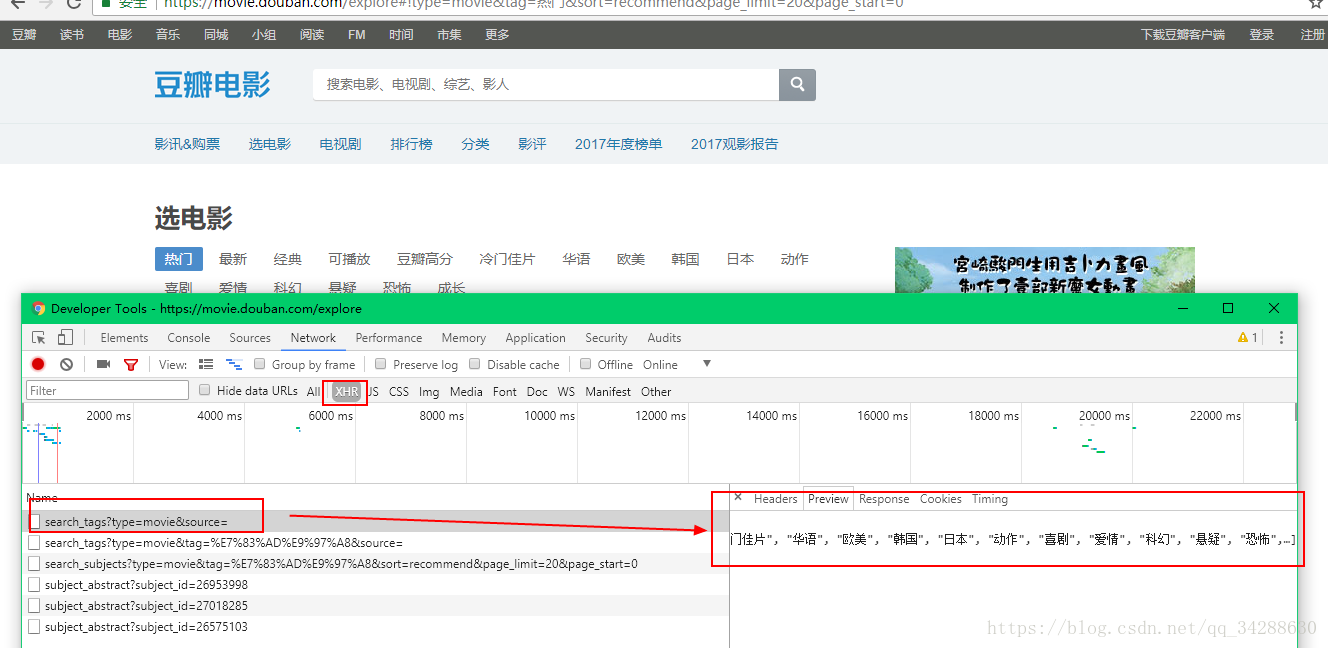
粘贴出链接 https://movie.douban.com/j/search_tags?type=movie&source=
会出现如下json:
{"tags":["热门","最新","经典","可播放","豆瓣高分","冷门佳片","华语","欧美","韩国","日本","动作","喜剧","爱情","科幻","悬疑","恐怖","动画"]}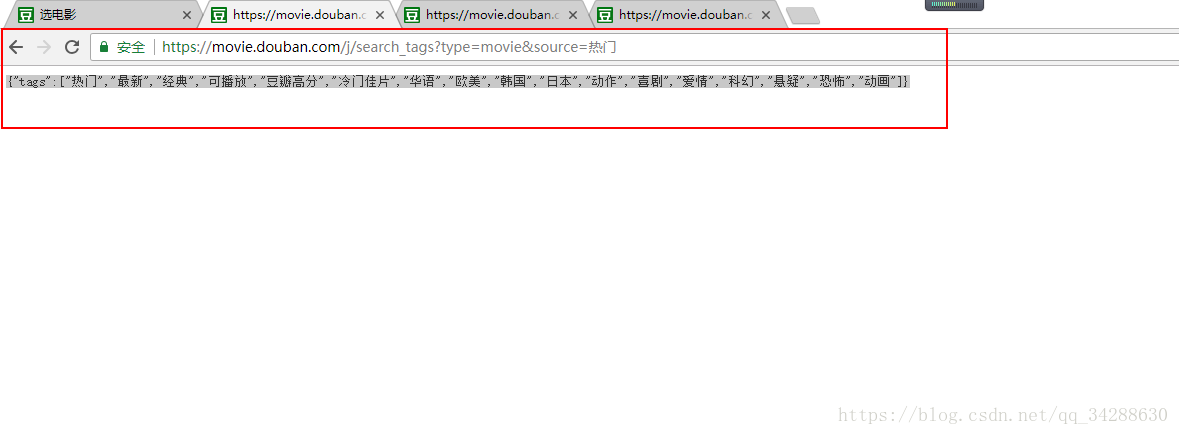
说明这个是每个分类电影的标签,是一个get请求的API,如果在python中加载成字典,则包含以恶个tags,对应的值是一个列表,里面的每一项都是一个电影标签。
我们还顺便发现另一个get请求的API:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0
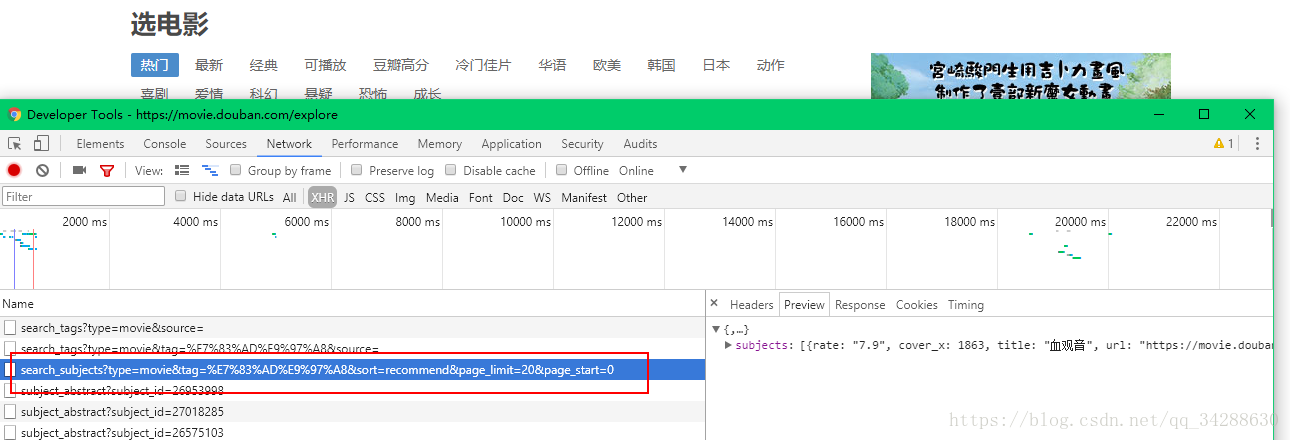
可以根据提供的标签,排序方法,每一页数量,每页开始编号等参数返回相应的电影数据,在浏览器访问此链接返回的也是一个json格式字符串,同样转换python字典在处理,如果单击记载更多按钮,会发现这个网页继续请求这个API,不同的是page_start不断增加,通过改变开始编号即可请求新的数据。所以思路是得到每一个标签,循环遍历每一个标签下面的电影。
二、代码实现
# coding=utf-8
import urllib
import urllib2
import json
# 获取所有标签
url = 'https://movie.douban.com/j/search_tags?type=movie&source='
request = urllib2.Request(url=url)
response = urllib2.urlopen(request,timeout=20)
result = response.read()
# 加载json为字典
result = json.loads(result)
tags = result['tags']
# 定义一个列表存储电影的基本信息
movies = []
# 处理每一个tag
for tag in tags:
start = 0
# 不断请求每一页,直到返回结果为空 空 说明遍历的此tag下的电影已经没了
while True:
# 此时遍历每一个标签每个标签的请求参数需要拼接, 包括标签和开始编号
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag='+tag+'&sort=recommend&page_limit=20&page_start='+str(start)
print url
request = urllib2.Request(url=url)
response = urllib2.urlopen(request,timeout=20)
result =response.read()
result = json.loads(result)
# 先在浏览器中请求上面的API,观察json的结构
# 然后在python中取出自己想要的数据
result = result['subjects']
# 返回结果为空的话,说明已经没有数据了
# 完成一个标签的处理退出循环
if len(result) ==0:
break
# 将每一条数据加入movies中
for item in result:
movies.append(item)
# 使用的循环条件得修改条件
#这里需要修改start
start += 20
# 看看一共获得了多少电影
print len(movies)
1、遇到问题,运行此代码
报错:UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 38-39: ordinal not in range(128)
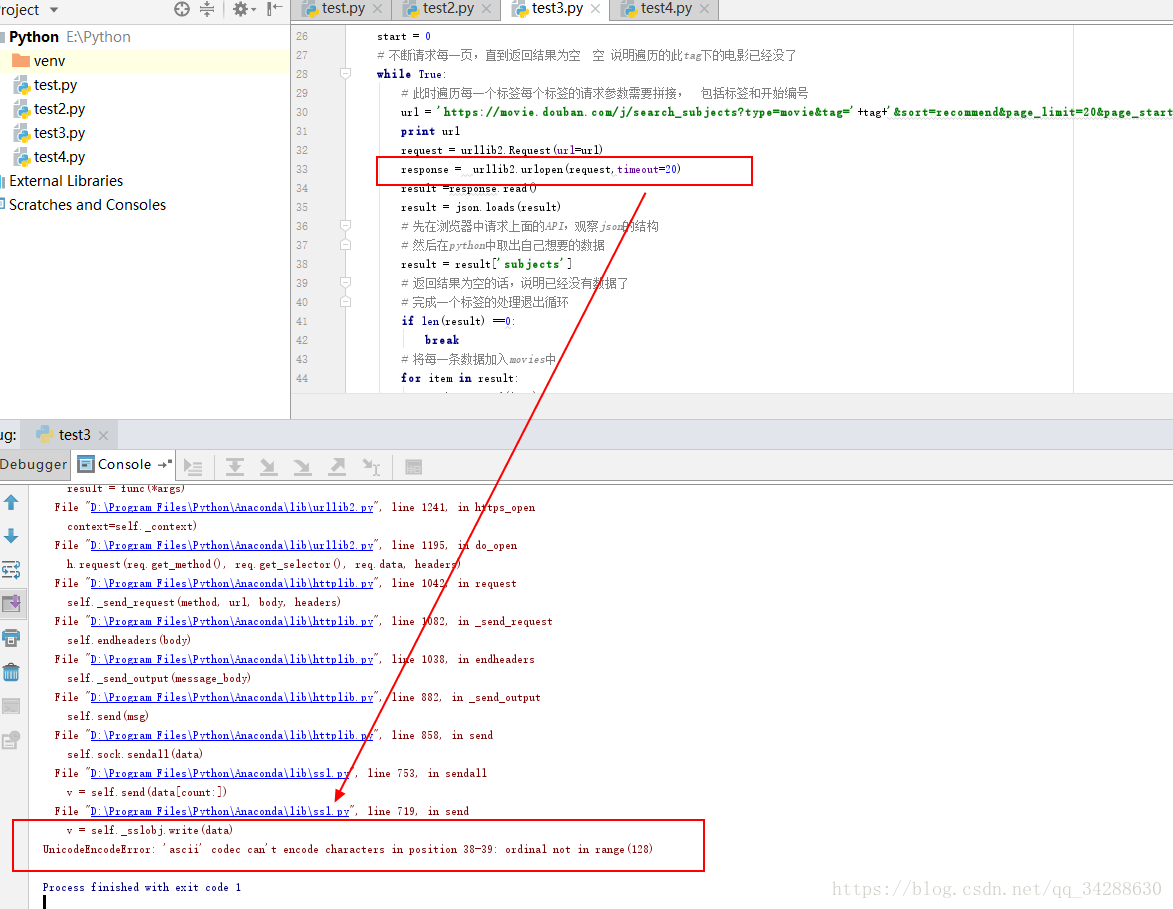
百度该问题查到了解决办法
解决方式:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')即在代码文件开始先导入sys包,然后在代码里调用修改默认编码方式的方法setdefaultencoding
下面解释原因:这个问题是由于Unicode编码与ASCII编码不兼容造成的。
首先在不添加以上代码的前提下先查看python调用的默认编码:
import sys
print sys.getdefaultencoding()通常都是ASCII,由于python自然调用ASCII编码解码程序去处理字符流,当字符流不属于ASCII范围内,就会抛出异常(ordinal not in range(128))。所以解决方法就是修改默认编码,需要注意的是需要先调用reload方法。
reload(sys)
sys.setdefaultencoding('utf-8')解决上面这个问题,运行代码
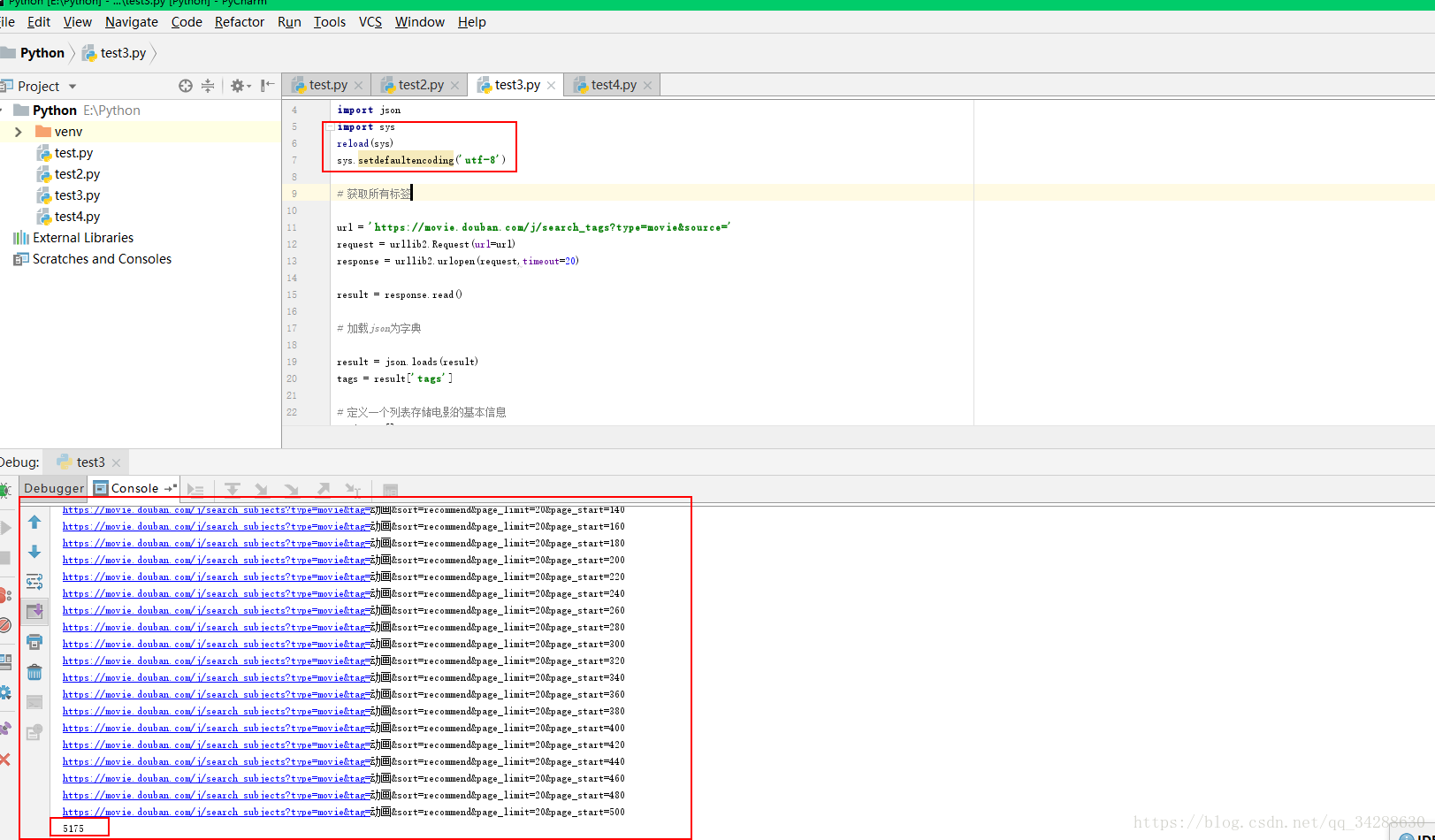
成功爬取到了5175部电影的信息。