https://www.bilibili.com/video/av9770302/?p=16
从之前讲的basic gan延伸到unified framework,到WGAN
再到通过WGAN进行Generation和Transformation

复习一下GAN,
首先我们有一个目标,target分布,Pdata,
蓝色部分表示Pdata高,即从这部分取出的x都是符合预期的,比如这里的头像图片
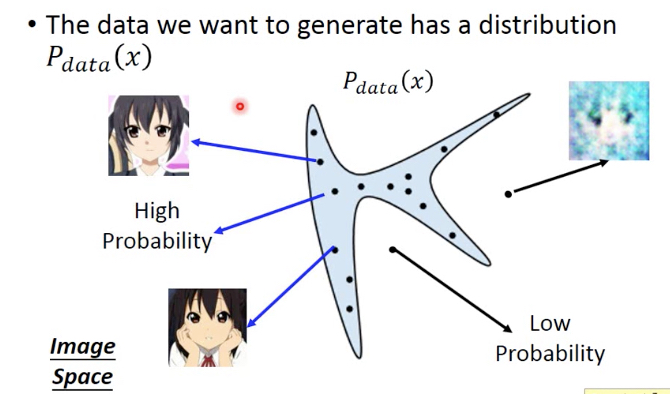
GAN的目的就是训练一个generator nn,让它的输出尽量接近Pdata分布
generator的输入一般都是normal distribution,输出接近Pdata,那么就意味着generator输出的x,高概率会落在蓝色区域,即我们想看到的图片
但这里的问题是,PG是算不出来的,其实这里Pdata我们也是不知道的,我们只有一些训练集,比如一批头像的图片
所以只有用sample的方式来训练
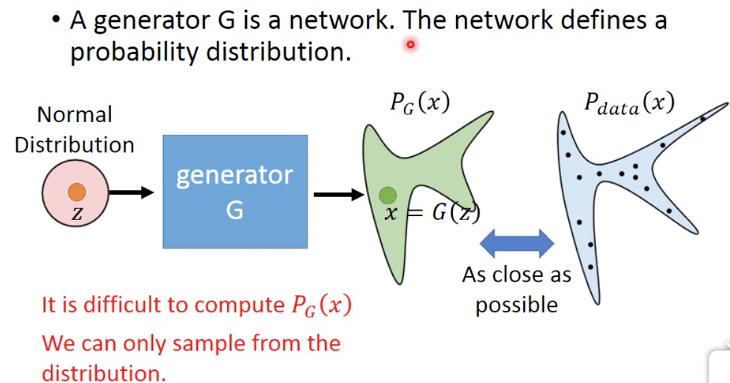
下面给出如何通过sample来训练,
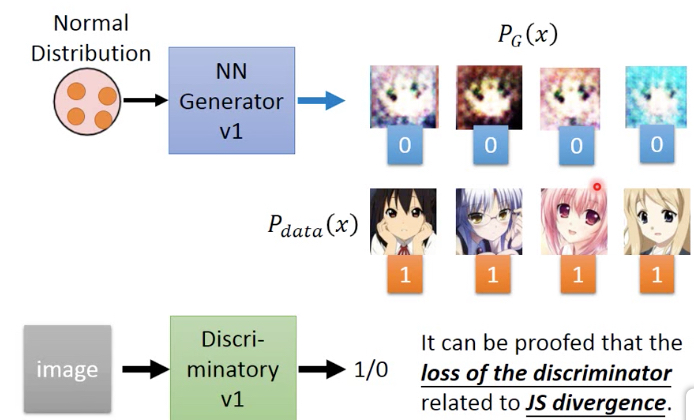
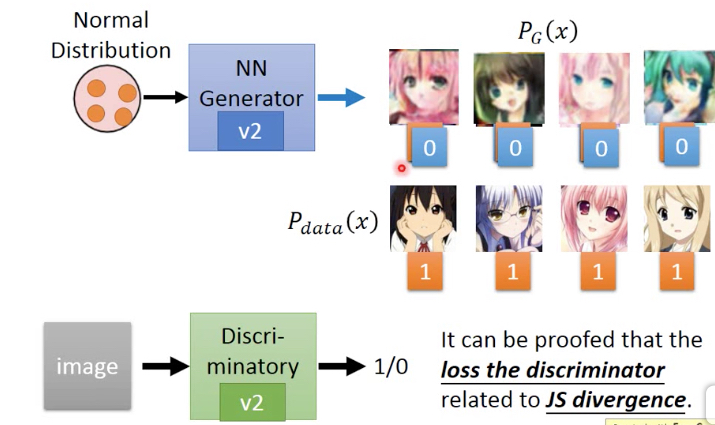
先随机从v1 generator中sample 4张图片作为false,从训练集中取4个作为true,来训练v1 discriminator
然后固定V1 discriminator,来训练出V2 generator
然后固定V1 discriminator,来训练出V2 generator,它产生的x,v1 discriminator都会判true
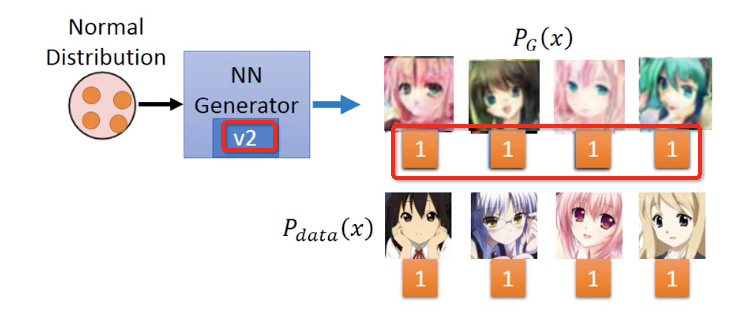
再训练产生V2 discriminator,让V2 generator生成的x,都被判false
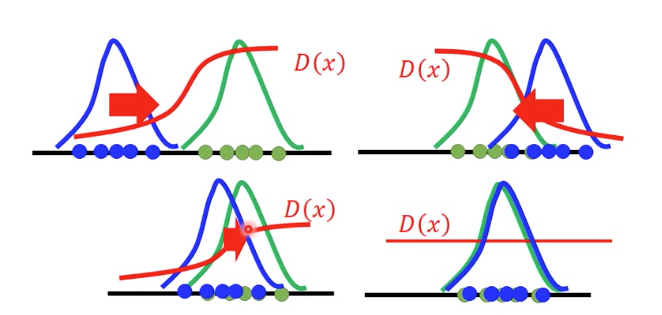
下面的图更形象的表示这一过程,
需要注意的是PG为蓝色曲线,调整generator nn的参数让它close Pdata,这个过程不是渐进的过程,而是一个反复的过程
nn的参数很难调的刚合适,往往或调过了,所以真实的过程是一个反复震荡close的过程
直到两者重合,discriminator就完全无法区分
简单的列出算法,
discriminator训练多次来max V,intuitive的理解V,让D(x)尽量大,即让训练集数据被判true,让D(x~)尽量小,即让generator生成的数据被判false
generator仅仅训练一次来min V,前面一项和generator无关所以不用考虑,min V,就要max D(G(z)),即让generator生成的数据尽量被判true

Unified Framework
下面来学习unifed framework,分成3部分
f-divergence
这篇论文称为f-Gan,Gan中Discriminator和JS-Divergence相关,其实可以任何f-divergence相关

f-divergence就可以用来衡量两个分布的相似度
这个定义对于函数f有两个约束,
其中f(1)=0,当p和q分布相同时,divergence就会取到0
f是convex,可以证明D的最小值就是0,下面通过jensen不等式,很容易证明

举几个f-divergence的例子,

Fenchel Conjugate(共轭)
对于每个convex函数,都存在一个对应的conjugate函数f*
定义是给定一个t,需要调整x,使得后面的式子最大,其中x需要在f的定义域中
这里假设先固定x,这样蓝框中的部分就变成线性函数,对不同的x就是不同的直线,现在对于某个给定t,只是找出最大的那个交点
从图上可以看出,f*也是convex的
右边举个例子,对于xlogx,他的f*就是exponential,从图上也能intuitive的看出


计算过程如下,maximizing就是求微分=0
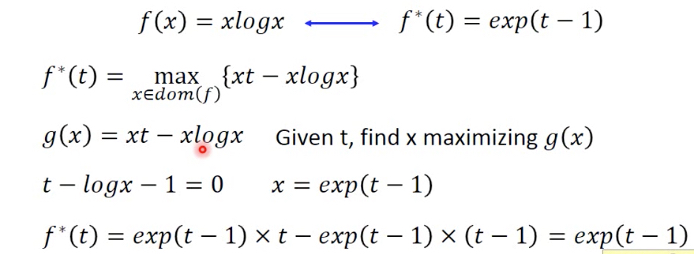
这里有个重要的特性,就是f** = f,即

代入f-divergence的公式,得到
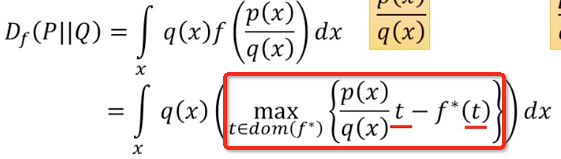
这个红框中的式子,给定x,找到一个t可以使得它取到最大值,那这个式子可以有个lowbound
如果随便给一个t,那么得到值一定是小于等于这个最大值
假设有个函数D,输入这个x,输出t,就有,因为对于任意一个D,从x算出的t,不一定是可以取到最大值的t
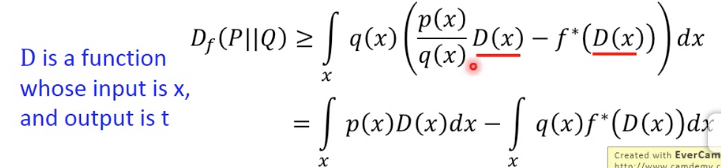
任意D代表下届,那么我们只要调整D,使得让其max,就可以逼近真实值
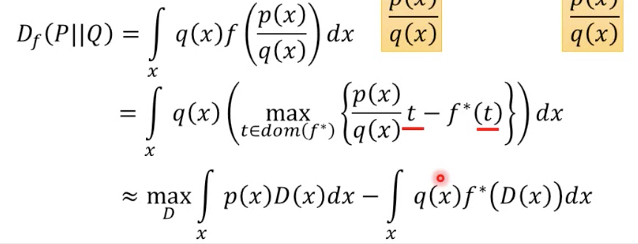
把上面的式子中,代入Pdata和PG,就得到Pdata和Pg的f-divergence的定义
如果我们要找一个PG,和Pdata尽量相似,也就是要找一个G,使得Df最小,于是得到G*
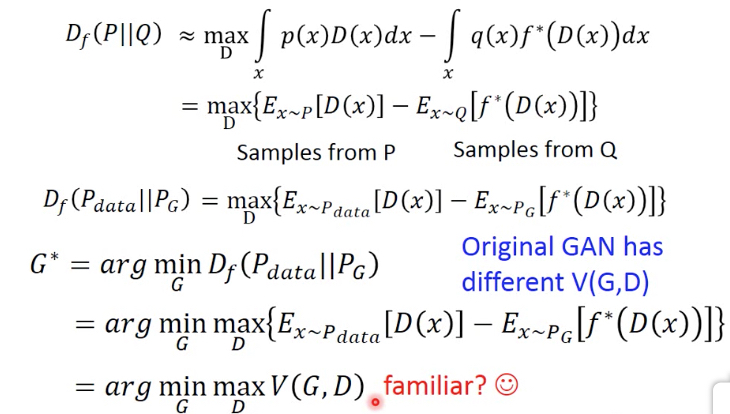
推导到这里就可以看出,之前GAN的V是怎么来的,这里用不同的f-divergence,即f不同,就可以得到不同的V
之前的GAN只是一种特殊形式罢了
所以这里就得到一种GAN的unified framework,这里列出各种不同的f-divergence

WGAN
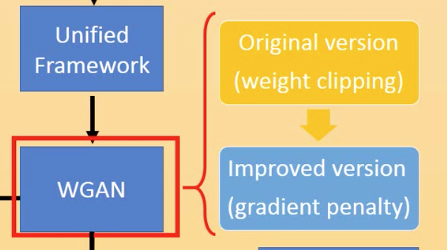
WGAN的论文,简单说,就是用earth mover's distance,或者wasserstein distance来衡量分布之间的差异
