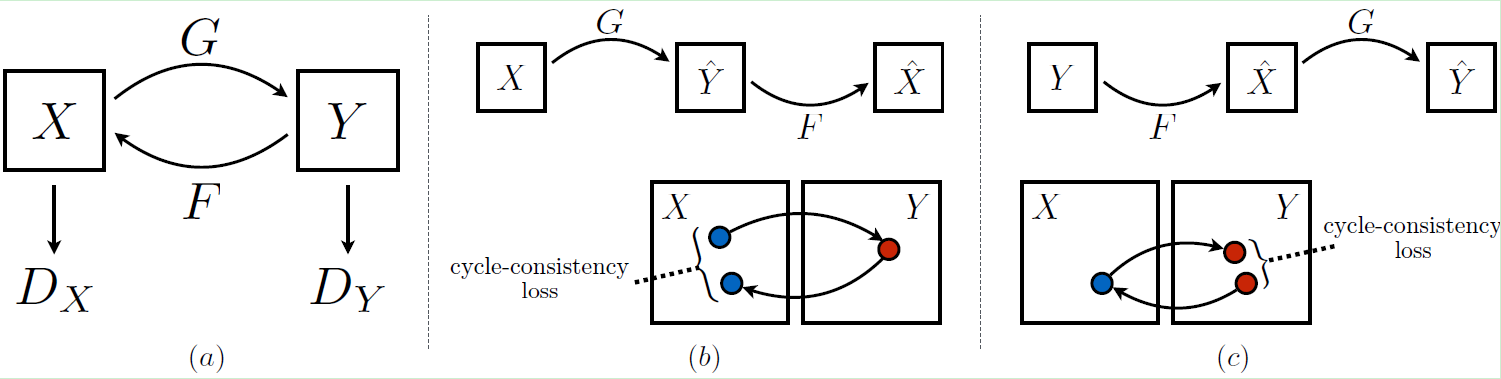
- DCGAN
DCGAN全称为Deep convolutional generative adversarial networks,即将深度学习中的卷积神经网络应用到了对抗神经网络中。
生成器,可以看做图片分类的逆过程,图片生成器输入随机向量,输出一个图片。随机向量不含像素级的位置信息。
而最初卷积网络,引入感受野,捕捉邻近区域的特征,越靠近输入端的信息,包含位置信息越明显,随着层层深入,感受野涵盖的区域的扩大,过于细节的位置信息丢失,留下高级语义信息,反映图片的类别。传统卷积神经网络只是捕捉或识别位置信息,不负责产生位置信息,位置源于图片,会在逐层计算中丢弃掉。
因此,如果使用卷积网络,从随机向量生成图片,生成过程符合两点原则
- 保证信息在逐层计算中增多
- 不损失位置信息,并且不断产生更多的位置信息
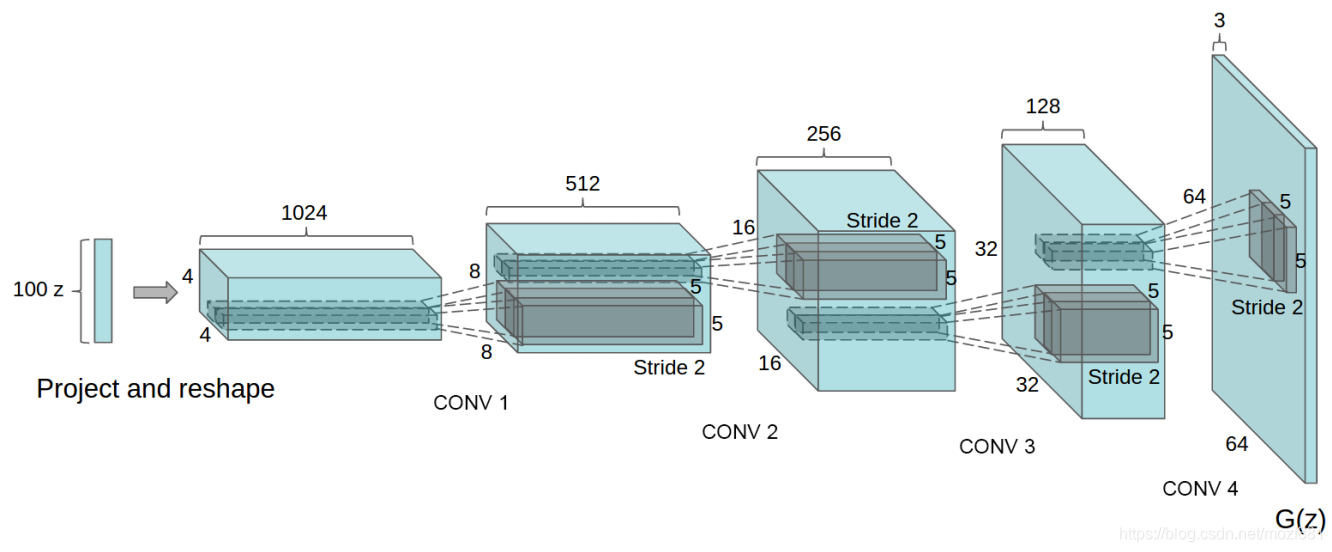
DCGAN的生成器网络结构如上图所示,相较原始的GAN,DCGAN几乎完全使用了卷积层代替全链接层,判别器几乎是和生成器对称的,从上图中我们可以看到,整个网络没有pooling层和上采样层的存在,实际上是使用了带步长(fractional-strided)的卷积代替了上采样,以增加训练的稳定性。
DCGAN能改进GAN训练稳定的原因主要有:
◆ 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层。
◆ 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。(生成器的最后一层和判别器的第一层不加batchnorm)
◆ 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh
◆ 使用adam优化器训练,并且学习率最好是0.0002,(我也试过其他学习率,不得不说0.0002是表现最好的了)
-
CGAN
使用GAN生成全新的样本,但是有个问题,不能确切控制新样本的类型。如果控制生成的结果,cGan可以解决问题。
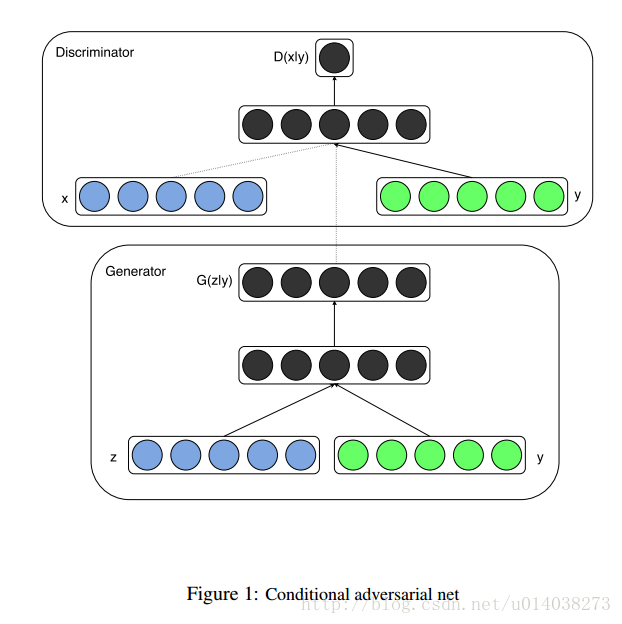
cGAN的全称为Conditional Generative Adversarial Networks, 即条件对抗生成网络,它为生成器、判别器都额外加入了一个条件y, 这个条件实际是希望生成的标签。生成器G必须要生成和条件y匹配的样本,判别器不仅要判别图像是否真实,还要判别图像和条件y是否匹配。cGAN的输入输为:
生成器G,输入一个噪声z,一个条件y,输出符合该条件的图像G(z|y)。
判别器D,输入一张图像x,一个条件y,输出该图像在该条件下的真实概率D(x|y) 。
-
WGAN
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,WGAN对GAN的改进主要有:
◆ 判别器最后一层去掉sigmoid
◆ 生成器和判别器的loss不取log
◆ 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的lipschitz连续性条件。
总的来说,GAN中交叉熵(JS散度)不适合衡量生成数据分布和真实数据分布的距离,如果通过优化JS散度训练GAN会导致找不到正确的优化目标,所以,WGAN提出使用wassertein距离作为优化方式训练GAN,但是数学上和真正代码实现上还是有区别的,使用Wasserteion距离需要满足很强的连续性条件—lipschitz连续性,为了满足这个条件,作者使用了将权重限制到一个范围的方式强制满足lipschitz连续性,但是这也造成了隐患,接下来会详细说。另外说实话,虽然理论证明很漂亮,但是实际上训练起来,以及生成结果并没有期待的那么好。 -
SeqGAN-生成文本序列
GAN在之前发的文章里已经说过了,不了解的同学点我,虽然现在GAN的变种越来越多,用途广泛,但是它们的对抗思想都是没有变化的。简单来说,就是在生成的过程中加入一个可以鉴别真实数据和生成数据的鉴别器,使生成器G和鉴别器D相互对抗,D的作用是努力地分辨真实数据和生成数据,G的作用是努力改进自己从而生成可以迷惑D的数据。当D无法再分别出真假数据,则认为此时的G已经达到了一个很优的效果。
它的诸多优点是它如今可以这么火爆的原因:
- 可以生成更好的样本
- 模型只用到了反向传播,而不需要马尔科夫链
- 训练时不需要对隐变量做推断
- G的参数更新不是直接来自数据样本,而是使用来自D的反向传播
- 理论上,只要是可微分函数都可以用于构建D和G,因为能够与深度神经网络结合做深度生成式模型
它的最后一条优点也恰恰就是它的局限,之前我发过的文章中也有涉及到,在NLP中,数据不像图片处理时是连续的,可以微分,我们在优化生成器的过程中不能找到“中国 + 0.1”这样的东西代表什么,因此对于离散的数据,普通的GAN是无法work的。
使用RL来解决这个问题
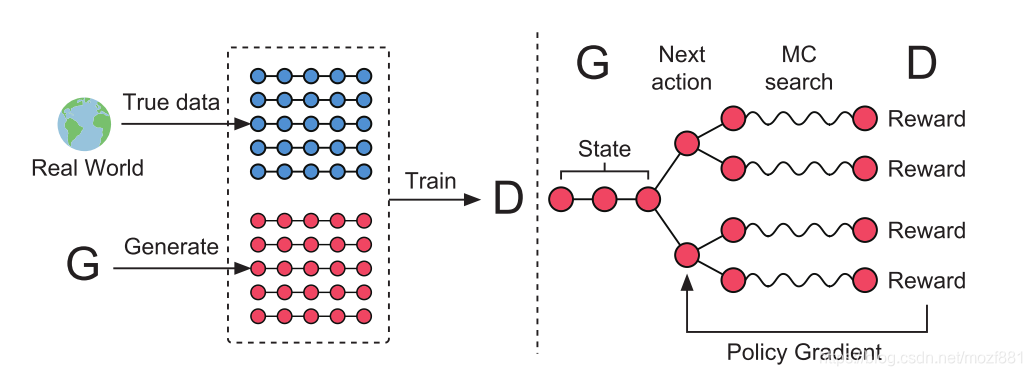
如上图(左)所示,仍然是对抗的思想,真实数据加上G的生成数据来训练D。但是从前边背景章节所述的内容中,我们可以知道G的离散输出,让D很难回传一个梯度用来更新G,因此需要做一些改变,看上图(右),paper中将policy network当做G,已经存在的红色圆点称为现在的状态(state),要生成的下一个红色圆点称作动作(action),因为D需要对一个完整的序列评分,所以就是用MCTS(蒙特卡洛树搜索)将每一个动作的各种可能性补全,D对这些完整的序列产生reward,回传给G,通过增强学习更新G。这样就是用Reinforcement learning的方式,训练出一个可以产生下一个最优的action的生成网络。
-
CycleGAN-自动将某一类图片转换成另外一类图片
CycleGAN的原理可以概述为:将一类图片转换成另一类图片。也就是说,现在有两个样本空间,X和Y,我们希望把X空间中的样本转换成Y空间中的样本。比如如何把女人变成男人,男人变成女人,猫狗之间的互相转换,如何去除图片中的马赛克。
CycleGAN是一个环形的结构,主要由两个生成器及两个判别器组成,如上图所示。X表示X域的图像,Y表示Y域的图像。X域的图像通过生成器G生成Y域的图像,再通过生成器F重构回X域输入的原图像;Y域的图像通过生成器F生成X域图像,再通过生成器G重构回Y域输入的原图像。判别器Dx和Dy起到判别作用,确保图像的风格迁移。
-
LAPGAN
江湖人称拉普拉斯对抗生成网络,主要致力于生成更加清晰,更加锐利的数据。LAPGAN事实上受启发与CGAN,同样在训练生成模型的时候加入了conditional variable,这也是本案例成功的一大重要原因。 -
SimGAN
Apple出品的SimGAN本质地利用了GAN可以产生和训练数据质量一样的生成数据这个特性,通过GAN生成大量的和训练数据一样真实的数据,从而解决当前大规模的精确标注数据难以获取,人工标注成本过高等一系列问题。 -
InfoGAN
InfoGAN是一种能够学习disentangled representation的GAN,比如人脸数据集中有各种不同的属性特点,如脸部表情、是否带眼镜、头发的风格眼珠的颜色等等,这些很明显的相关表示, InfoGAN能够在完全无监督信息(是否带眼镜等等)下能够学习出这些disentangled representation,而相对于传统的GAN,只需修改loss来最大化GAN的input的noise和最终输出之间的互信息。 -
AC-GAN
AC-GAN即auxiliary classifier GAN。 -
IRGAN
生成离散样本