学习向量量化算法(以下简称LVQ)和k均值算法(k-means)都属于原型聚类的典型算法,它跟k均值算法最大的不同是,LVQ的样本带有类别标记,利用这些标记辅助聚类,属于监督学习范畴。
LVQ的目标是学得一组n维(样本维数)原型向量{P1,P2,...,Pq},每个原型向量代表一个聚类簇。算法描述如下:

第6-10行表示,当距离最近的原型向量与所选样本标记相同,则该原型向量向样本方向靠拢;当距离最近的原型向量与所选样本标记不同,则向远离该样本的方向移动:
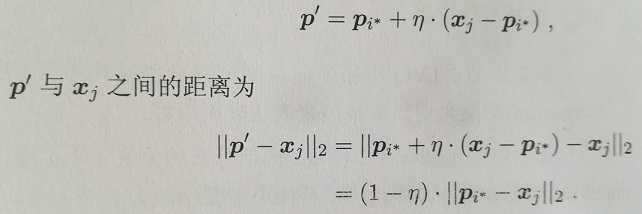
样本将被划入与其距离最近的原型向量所代表的簇中。
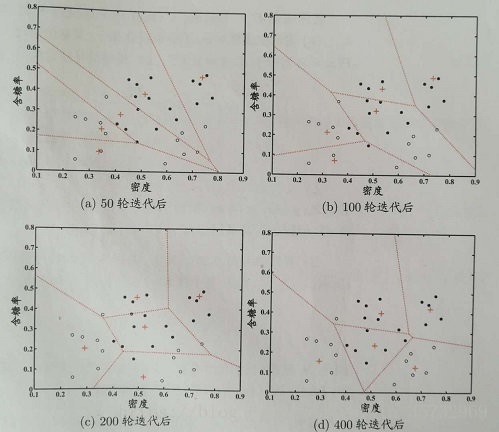
注意:原型向量的个数跟类别标记的种类数不一定要相等。例如,某数据集类别标记有两种c1和c2,学习目标可以是找到5个原型向量p1,p2,p3,p4,p5,并假定它们对应的类别标记分别为c1,c2,c2,c1,c1。最终的学习结果会产生类似如下的簇划分(圆点表示不同类别标记的样本点,加号表示原型向量):
python代码实现LVQ:
#迭代轮数
for i in range(loops):
#随机产生样本
index = np.random.randint(0,30)
min_dist = sum((q[0] - x[index])**2)
q_index = 0
#搜索里样本最近原型向量
for j in range(1,len(q)):
dist = sum((q[j] - x[index])**2)
if dist < min_dist:
min_dist = dist
q_index = j
if q_label[q_index] == y[index]:
#样本标记和原型向量标记相同,该原型向量向样本方向移动
#eta为学习率
q[q_index] += eta*(x[index]-q[q_index])
else:
#样本标记和原型向量标记相同,该原型向量远离样本方向
q[q_index] -= eta*(x[index]-q[q_index])
#画图
for i in range(len(x)):
if y[i] == 0:
plt.plot(x[i,0],x[i,1],'or')
else:
plt.plot(x[i,0],x[i,1],'o',color='black')
for i in range(len(q)):
plt.plot(q[i,0],q[i,1],marker='*',color='blue')某次迭代300次的图:
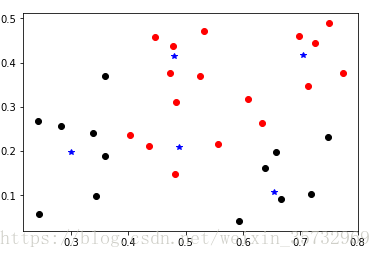
参考资料:周志华《机器学习》
相关博文: