一、重点单词理解
confine 限制
hinders 阻碍
popularisation 普及
Simultaneous 同时
simulation 模拟
prone 容易
generalised 广义; 全面; 普遍化
recept 接受
compact 紧凑的
successive 连续的
feedback 反馈
discarded 丢弃
complement 补充
incorporate 包含
viable 可行的
二.《DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks》
本文作者通过提出了一种使用深度循环卷积神经网络(RCNNs)的端到端的单目视距的框架。现有的DL架构和预先训练的模型基本上都是为了解决识别和分类问题而设计的,但VO工作有限并且与3D问题有关,VO算法严重依赖于几何特征而不是外观特征,同时作者指出VO算法应该通过检查图像序列上的变化,而不是处理单个图像来对运动动力学建模,由于CNN不能对连续信息建模,以前的工作也没有考虑图像序列或视频用于顺序学习,因此在这项工作中,作者通过利用RNN来解决这个问题。总体而言,基于RCNN的架构的优点是允许通过CNN和RNN的组合同时提取和顺序建模VO。
该文的主要贡献有三点:①作者最先证明了可以基于DL以端到端的方式解决单目VO问题,直接从原始RGB图像估计姿势。②提出了一种RCNN体系结构,通过使用CNN学习的几何特征表示,可以将基于DL的VO算法推广到全新的环境。③对VO来说,对图像序列的顺序依赖性和复杂的运动动力学很重要,它们是隐式封装的并且是自动的,因此不能被轻松建模。

(1)RCNN的总体结构
作者提出的RCNN考虑了一下这两个要求。①之前简单地采用当前流行的DNN架构来解决VO问题不现实,而学习几何特征表示的框架对于解决VO和其他几何问题很关键。②同时,由于VO系统随时间演变,并对运动期间获得的图像序列进行操作,还必须导出连续图像帧之间的连接。
所提出的端到端VO系统的架构如图2所示。首先,它采用剪辑的视频或单目图像序列作为输入。在每个时间步,通过减去训练集的平均RGB值并对RGB图像帧进行预处理,并可以选择将其调整为64倍数的新大小。将两个连续的图像堆叠在一起以形成一个tensor,学习如何提取动态信息和姿势估计。
具体而言,将图像张量先输入CNN中以产生单目VO的有效特征,然后将其通过RNN进行顺序学习。每个图像对在通过网络的每个时间步上都会产生一个姿势估计。VO系统会随着时间的发展而发展,并会在捕获图像时估计新的姿势。

(2)基于CNN的特征提取
为了能提取VO问题的有效特征,作者使两个连续的单目RGB图像进行级联,然后执行特征提取。这个 VO 系统会随时间的推移而发展,并接受新图像时估计新的姿态。表1概述了CNN的配置,其中它具有9个卷积层,每个层之后的激励层使用的激活函数为Relu函数,即共有17层。
CNN采用原始的RGB图像而不是经过预处理的对应图像作为输入,因为网络进行学习有效特征表示的训练,并且减少VO维数。可以将高纬的RGB图像压缩成紧凑的描述,同时还增强了连续的顺序训练过程,最后的卷积层提取的特征被传递到RNN以进行顺序建模。

(3)基于RNN的顺序建模
RNN不适合直接从高维原始数据(例如图像)学习顺序表示。因此,所提出的系统采用吸引人的RCNN架构,其中CNN特征作为RNN的输入。为了能够发现和利用在长轨迹上拍摄的图像之间的相关性,作者引入了LSTM网络。折叠的LSTM及其随时间变化的展开形式以及LSTM单元的内部结构如图4所示。在作者的情况下,Deep RNN是通过堆叠两个LSTM层(其中一个LSTM的隐藏状态是另一层的输入)来构造的。结合图3公式可以很直观的理解,其中 , , , 和 分别对应k时刻图中的输入们, 遗忘门,输入调制门, 记忆单元 和输出门。
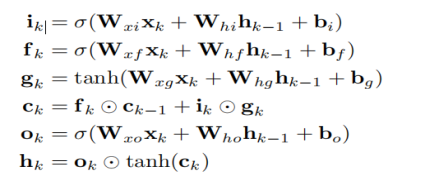

(3)损失函数
基于RCNN的VO系统计算姿势的条件概率:
p ( Y t , X t ) = p ( y 1 , . . . . , y t ∣ x 1 , . . . , x t ) (公式1) p(Y_t,X_t)=p(y_1,....,y_t|x_1,...,x_t) \tag{公式1} p(Yt,Xt)=p(y1,....,yt∣x1,...,xt)(公式1)
其中,是连续的单目 RGB 图像序列,是任意时刻的姿态值。
为了使得上述公式(1)条件概率最大化,引入一个参数:
θ ∗ = a r g θ m a x p ( Y t ∣ X t ; θ ) (公式2) \theta ^*=arg_\theta maxp(Y_t|X_t;\theta) \tag{公式2} θ∗=argθmaxp(Yt∣Xt;θ)(公式2)
为了学习DNN的超参数θ在时间k处的真实姿态与其估计的姿态之间的欧式距离最小,均方误差(MSE)由所有位置的p和方向φ的函数组成:
θ ∗ = a r g θ m i n 1 N ∑ i = 1 N ∑ k = 1 t ∣ ∣ p ^ k − p k ∣ ∣ 2 2 + κ ∣ ∣ φ ^ k − φ k ∣ ∣ 2 2 (公式3) \theta ^*=arg_\theta min \frac{1}{N}\sum_{i=1}^N\sum_{k=1}^t||\hat p_k-p_k||^2_2+\kappa|| \hat \varphi_k-\varphi_k||^2_2 \tag{公式3} θ∗=argθminN1i=1∑Nk=1∑t∣∣p^k−pk∣∣22+κ∣∣φ^k−φk∣∣22(公式3)
其中 ∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||^2_2 ∣∣⋅∣∣22是 2范数,是平衡位置和方向权重的比例因子,N是样本数。方位φ由欧拉角。作者还发现在实践中使用四元数会在一定程度上降低方向估计的精确性。
(4)总结
本文提出了一种基于深度学习的端到端单眼VO算法。Deep RCNN能够通过将CNN与RNN相结合,实现单目眼VO的同时表示学习和顺序建模。并且由于它不依赖于传统VO算法中的任何模块来进行姿态估计,因此不需要仔细调整VO系统的参数。RCNN这是对经典基于几何方法的补充,将几何结构与DNN所学习的表示,知识和模型相结合,以进一步提高VO的准确性和鲁棒性。