一个单词或者一个字,要被计算机理解,那就要使其变成一个对应的值,这个值可以是vector。
要在程序中运用,一个想法就是构造词汇表,然后对照词汇表,对某个单词或字构造出一个向量。例如,假设有一张10000维度的词汇表,第1个单词是a,第2个是...直到第10000个单词是zelu,那么单词a对应的vector是(1,0,0,...,0)^T,只有第一个位置是1,其余位置都是0的1000维度的向量表示。这种表示方法称为One-Hot Representation。但是,这样构造的向量并不是很好。首先,可以看出它是非常稀疏的,是一个10000维度的向量,所以在计算方面也会非常耗时;其次,这样的表示方法与我们的认知不符,它仅仅表示了该单词,却没有展示出与其它类似单词的关联性。例如,假设单词“orange”是第6527个单词,单词“apple”是第53个单词,但是我们都知道“orange”和“apple”是相似的,所以,这样的向量构造并不是很好。
我们希望为每个单词构造出一个向量,既能表示出该单词且维度较低,又能体现单词间的联系性。我们就需要另一种表示方法,称为Distributed Representation。
Word Embedding(该文图片来源于网易公开课)
我们可以通过这样的方式构造单词向量,例如,我们需要构造“Man”,“Woman”,“King”,“Queen”,“Apple”,“Orange”
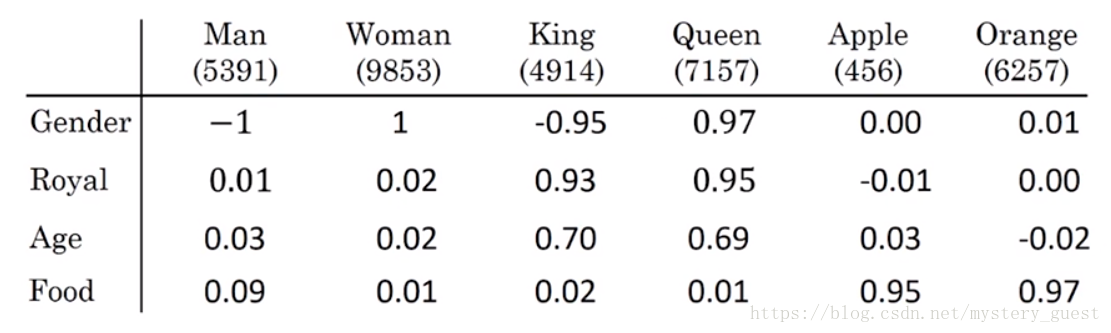
我们可以用多个特征来表示每个单词(图中Gender性别,Royal高贵等等...还有很多特征,一般取几百维左右),使得每个单词对于每个每个特征都有一个值,可以看出,当对这样的词向量进行训练时,相似的词训练结果也是类似的。这样的矩阵称为嵌入矩阵。第i列向量即对第i个单词的vector,被称为Distributed Representation方法。
例如:I want a glass of orange ______,我们想知道,这个单词是什么,一种做法是,取前几个单词,送入神经网络中,经过softmax,得出概率向量,概率最大即是输出。
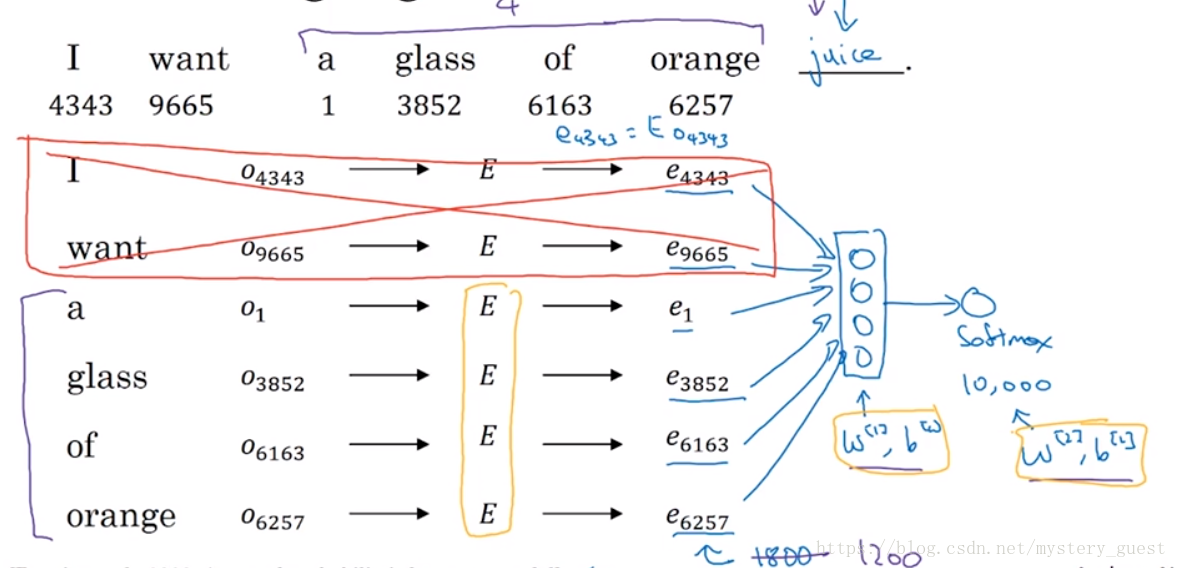
例如图中就是取前4个词来进行预测,O向量表示One-Hot vector,E表示嵌入矩阵,e即代表每个单词经过Distributed Representation的vector。这也是Skip-Gram模型的思想。
Word2Vec之Skip-Gram模型
可以看出,上面的过程是一个无监督学习的过程,我们不知道所预测的单词是什么,我们借用上面的思想,当给定一个句子
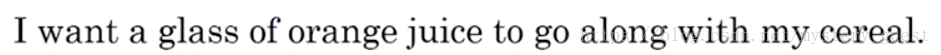
那么我们就可以构造出一个监督学习,例如,我们想要以orange为context,以它附近10的词距内的随机词target,作为预测结果。那么训练集就可以为
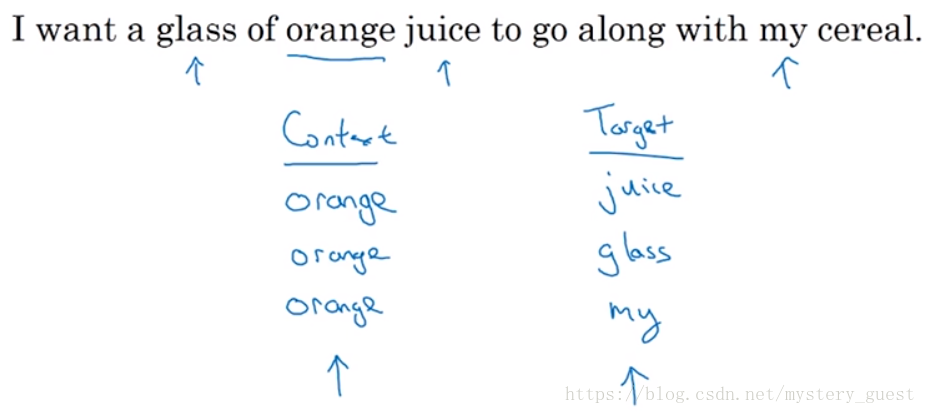
当然,我们并不是想要解决这个学习问题本身,而是想通过这个监督学习,来获得一个word embedding模型。假设context为“orange”,target为“juice”,那么训练的模型如下图:
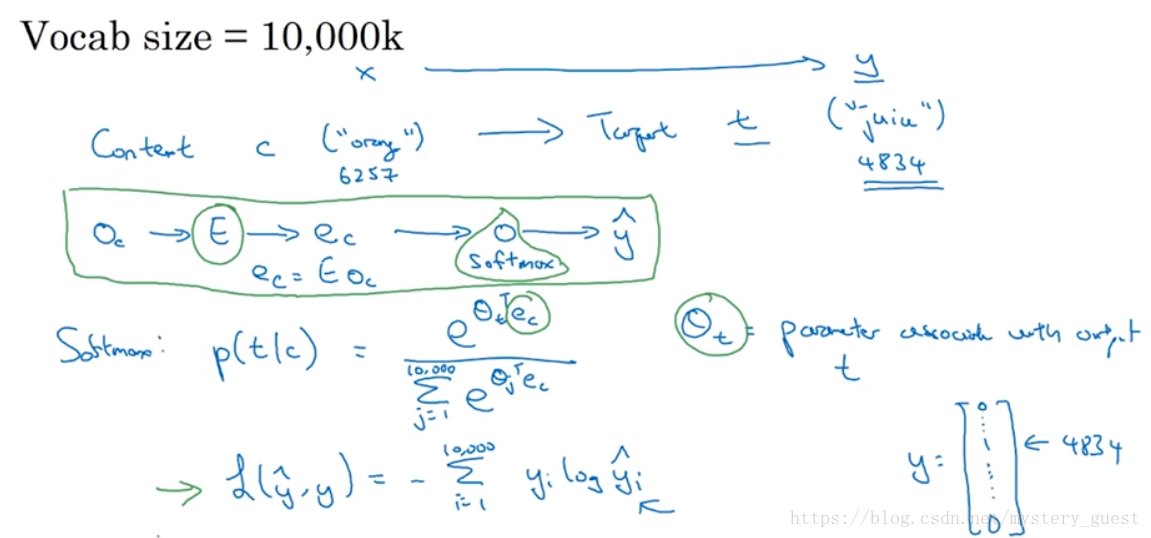
其中E为需要训练的嵌入矩阵参数,θt为softmax的参数,target的y为One-Hot vector,
负采样
对于上述的情况,我们可以通过负采样的方法来提高效率。我们在对每一个context的训练中,不需要对所有10000个单词进行softmax,而是通过对词汇表中的词汇进行随机采样,并将target值设为0。例如cotext为orange,word为juice,采样的单词为king,book,the,of。此时采样数值k=4。一般大样本k取值为2~5,小样本k取值为5~20.

因此,我们每次训练的时候,对于某个context单词,会有一个正样本,然后随机采样k个负样本,因此,我们只需要k+1个样本来进行训练,概率p是通过sigmoid来计算。
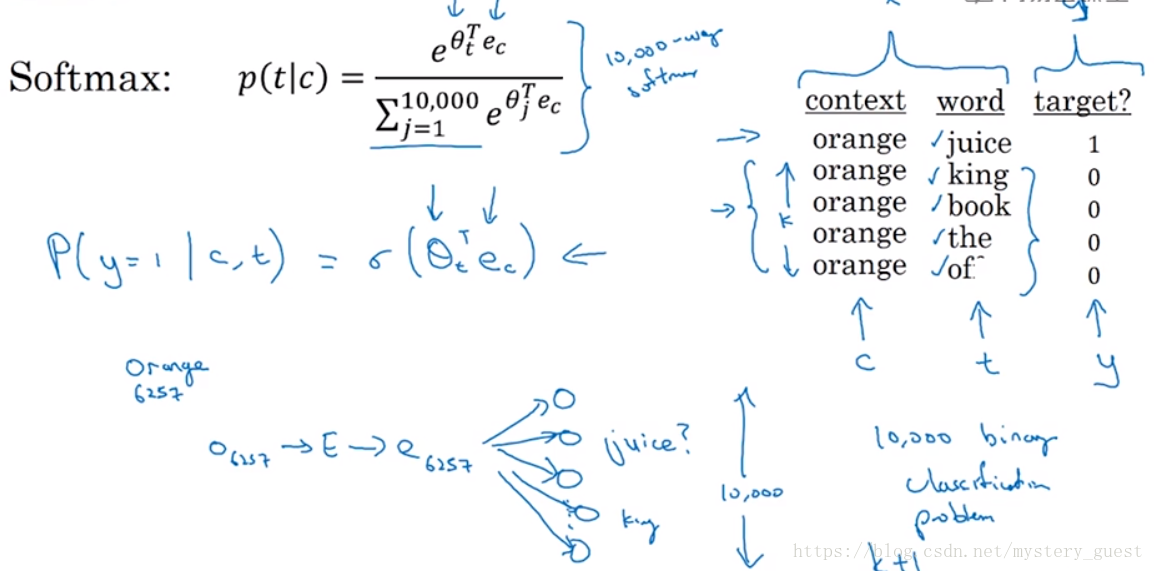
然而,这种方法有个关键的细节,在于,对于每次训练如何随机采样。经验表明
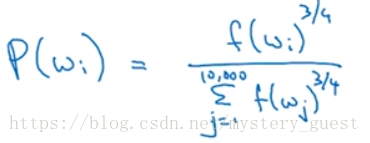
采样概率p通过这样的方法计算效果最好。其中f(wi)^3/4,表示第i个单词的频数的3/4次方。