提升树是以回归树为基本分类器的提升方法。以决策树为基函数的提升方法称为提升树(boosting tree)。对分类问题决策树是分类树,对回归问题决策树为回归树。首先定义决策树用公式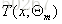
提升树算法:
1.首先确定初始提升树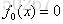
2.第二个提升树
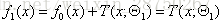
第三个提升树
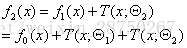
……推出:
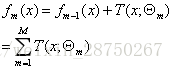
3.回忆一下CART回归树,它是采用平方误差损失函数最小来决定最佳分类点,

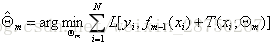
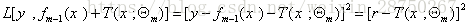
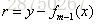
4.更新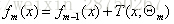
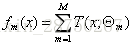
如果不理解,可以看下面例子:
这个例子与CART回归树用的是同一个例子,可以帮助理解对比。(例子来源李航:统计学习方法)。
| X |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| Y |
5.56 |
5.7 |
5.91 |
6.4 |
6.8 |
7.05 |
8.9 |
8.7 |
9 |
9.05 |
步骤一: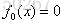
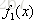
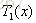
通过以下优化问题找到最初分割点s: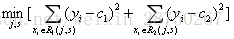
取s=1.5,此时 R1={1},R2={2,3,4,5,6,7,8,9,10},这两个区域的输出值分别为:c1=5.56,c2=1/9(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)=7.50。
取s=2.5,c1=5.63,s2=7.73,等等,计算m(1.5)=0+15.72=15.72等等,得到下表:
| s |
1.5 |
2.5 |
3.5 |
4.5 |
5.5 |
6.5 |
7.5 |
8.5 |
9.5 |
| m(s) |
15.72 |
12.07 |
8.36 |
5.78 |
3.91 |
1.93 |
8.01 |
11.73 |
15.74 |
显然s=6.5时,m(s)最小。因此,第一个划分变量s=6.5
对这个选定划分后的两个区域为R1={1,2,3,4,5,6},R2={7,8,9,10}输出值c1=6.24,c2=8.91。
所以回归树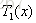
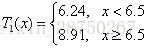
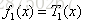
到此为止与CART回归树算法一样,CART接下来就是在分完的子树中继续利用平方损失函数分类,但提升树算法如下:
用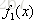

| 1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
| -0.68 |
-0.54 |
-0.33 |
0.16 |
0.56 |
0.81 |
-0.01 |
-0.21 |
0.09 |
0.14 |
用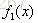
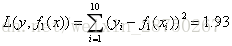
步骤二:求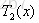
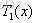
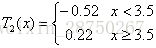
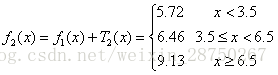
用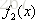
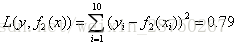
继续求得: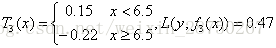
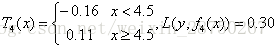

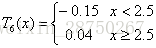
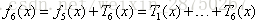

用
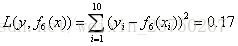
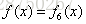
梯度提升树(GBDT)
Gradient Boosting(提升树):每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少(当然也可以变向理解成每个新建的模型都给予上一模型的误差给了更多的关注),与传统Boost对正确、错误的样本进行直接加权还是有区别的。
所以,有的文章把上一节介绍的基于残差的提升树方法叫做GBDT(梯度提升树),他们认为GBDT分为两个版本,一个就是这个残差的提升树,另一个版本就是即将介绍的基于负梯度的提升树;具体读者怎么分类,各自保留意见,只要自己不蒙圈就行。
首先我们先把李航描述的GBDT算法写出来,再做分析:
提升树的损失函数是平方损失,每一步优化是简单,但对一般损失函数而言,往往每一步优化并不简单,梯度提升就是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值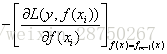
梯度提升算法:
(1) 初始化:
(2) 对m=1,2,……M
a 对i=1,2,……N计算
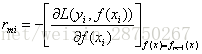
b 对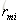
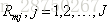
c 对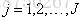
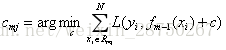
d 更新

(3) 得到回归树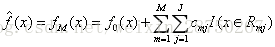
第1步:初始化,估计使损失函数最小化的常数值,它是只有一个根节点的树;
第2(a)步:计算损失函数的负梯度在当前模型的值,将它作为残差的估计。对于平方损失函数,它就是通常所说的残差;对于一般损失函数,它就是残差的近似值;
第2(b)步:估计回归树叶节点区域,以拟合残差的近似值;
第2(c)步:利用线性搜索估计叶节点区域的值,使损失函数极小化;
第2(d)步:更新回归树;
第3步:得到输出的最终模型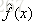
GBDT常用的损失函数:
对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种:
a) 如果是指数损失函数,则损失函数表达式为

其负梯度计算和叶子节点的最佳残差拟合参见Adaboost原理篇。
b) 如果是对数损失函数,分为二元分类和多元分类两种,
二元GBDT:
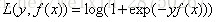
多元GBDT:
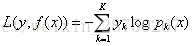
对于回归算法,常用损失函数有如下4种:
a)均方差,这个是最常见的回归损失函数了

b)绝对损失,这个损失函数也很常见
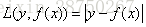
对应负梯度误差为:
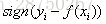
c)Huber损失,它是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。这个界限一般用分位数点度量。损失函数如下:
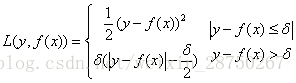
对应的负梯度误差为:
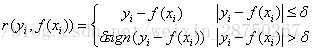
d) 分位数损失。它对应的是分位数回归的损失函数,表达式为
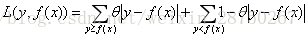
其中θ为分位数,需要我们在回归前指定。对应的负梯度误差为:

对于Huber损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
先说回归算法,我们依然采用简单的平方损失函数。是的,跟提升树采用的损失函数一样,但是算法不一样!那么第m轮的第i个样本的损失函数的负梯度为: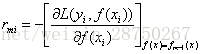

举个栗子(来自博客https://blog.csdn.net/zpalyq110/article/details/79527653):
如下表所示:一组数据,特征为年龄、体重,身高为标签值。共有5条数据,前四条为训练样本,最后一条为要预测的样本。
| 编号 |
年龄 |
体重(kg) |
身高(m) |
| 1 |
5 |
20 |
1.1 |
| 2 |
7 |
30 |
1.3 |
| 3 |
21 |
70 |
1.7 |
| 4 |
30 |
60 |
1.8 |
| 5(要预测的) |
25 |
65 |
? |
步骤一:初始化弱学习器,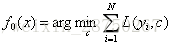
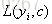
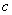
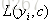
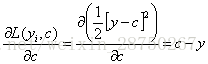


所以初始化时,
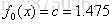
步骤二:迭代第一轮m=1:
计算负梯度,当采用损失函数是平方损失函数时负梯度就是残差: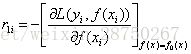
| 编号 |
真实值 |
残差 |
|
| 1 |
1.1 |
1.475 |
-0.375 |
| 2 |
1.3 |
1.475 |
-0.175 |
| 3 |
1.7 |
1.475 |
0.225 |
| 4 |
1.8 |
1.475 |
0.325 |
把上表算出的残差作为样本标签,训练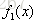
| 编号 |
年龄 |
体重(kg) |
身高(m) |
| 1 |
5 |
20 |
-0.375 |
| 2 |
7 |
30 |
-0.175 |
| 3 |
21 |
70 |
0.225 |
| 4 |
30 |
60 |
0.325 |
然后找最佳划分点,提升树时使用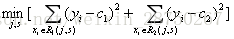
采用年龄划分:
| 划分点 |
小于划分点的样本 |
大于划分点的样本 |
总方差 |
| 5岁 |
/ |
1,2,3,4 |
0.082 |
| 7岁 |
1 |
2,3,4 |
0.047 |
| 21岁 |
1,2 |
3,4 |
0.0125 |
| 30岁 |
1,2,3 |
4 |
0.062 |
采用体重划分:
| 划分点 |
小于划分点的样本 |
大于划分点的样本 |
总方差 |
| 20kg |
/ |
1,2,3,4 |
0.082 |
| 30kg |
1 |
2,3,4 |
0.047 |
| 60kg |
1,2 |
3,4 |
0.0125 |
| 70kg |
1,2,4 |
3 |
0.0867 |
遍历所有样本点后,发现方差最小0.0125的划分:年龄21岁或者体重60kg,采用哪种划分都行,我们采用年龄21岁划分。
在算法2(c)步,接着给这两个叶子节点计算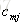


样本1,2为左叶子节点,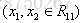
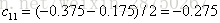
样本3,4为右叶子节点,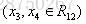
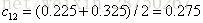
算法2(d)更新强学习器,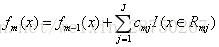
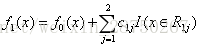
步骤三:继续m次迭代,重复以上算法,m可以认为控制,生成m颗树;
假设我们只迭代1次,那么得到最终的强学习器,最终的树为:
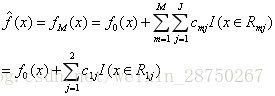
GBDT树:
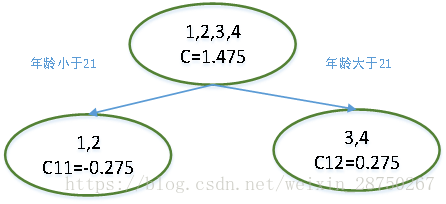
步骤四:预测,对原始数据有个样本5,年龄为25岁,预测其身高,根据最终强分类器,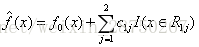
用于分类的GBDT(参考博客:https://www.cnblogs.com/pinard/p/6140514.html):
GBDT 无论用于分类还是回归一直都是使用的CART 回归树,GBDT的分类算法从思想上和GBDT的回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。
为了解决这个问题,主要有两个方法,一个是用指数损失函数,此时GBDT退化为Adaboost算法。另一种方法是用类似于逻辑回归的对数似然损失函数的方法。也就是说,我们用的是类别的预测概率值和真实概率值的差来拟合损失。本文仅讨论用对数似然损失函数的GBDT分类。而对于对数似然损失函数,我们又有二元分类和多元分类的区别。
二元GBDT分类算法:
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数为:
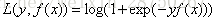
其中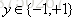

对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
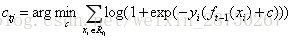
由于上式比较难优化,我们一般使用近似值代替
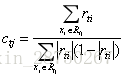
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,二元GBDT分类和GBDT回归算法过程相同。
多元GBDT分类算法:
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假设类别数为K,则此时我们的对数似然损失函数为:

其中如果样本输出类别为k,则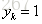
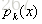

集合上两式,我们可以计算出第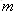
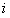

观察上式可以看出,其实这里的误差就是样本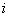

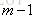
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
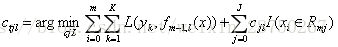
由于上式比较难优化,我们一般使用近似值代替
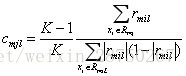
除了负梯度计算和叶子节点的最佳残差拟合的线性搜索,多元GBDT分类和二元GBDT分类以及GBDT回归算法过程相同。
先介绍一下算法流程:
样本总共有K个分类,新来一个样本求这个样本属于哪一类;
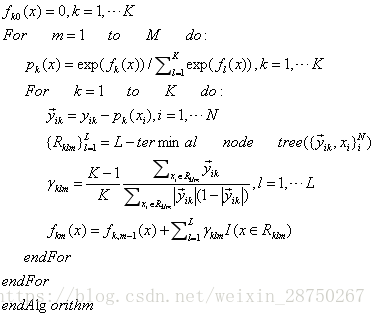
反正我是看不懂,这都是啥,由例子来解析算法吧
(参考博客https://blog.csdn.net/qq_22238533/article/details/79199605):
一组简单的数据,也就是只有一个特征值:
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
A |
A |
A |
A |
A |
B |
B |
B |
B |
B |
C |
C |
C |
C |

由于我们要转化为3个二分类问题,所以需要先one-hot:
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
A |
A |
A |
A |
A |
B |
B |
B |
B |
B |
C |
C |
C |
C |
| |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
| |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
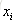
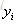

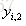
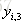
对于K各分类问题,我们即要训练K个数,类别标签为A的树CART Tree1,如果样本属于类别A那么它的类别标签输出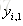
为了方便说明只进行一轮迭代,学习率为1;
首先初始化
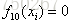
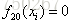
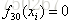
对第一棵树CART Tree1即类别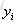
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
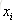
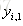
利用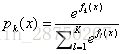
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
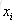
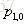

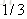

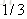
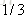
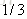
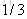
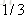
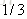
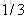
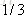

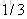
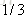
计算负梯度值,比如求
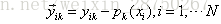

| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
2/3 |
2/3 |
2/3 |
2/3 |
2/3 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
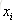
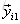
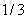
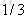
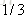
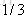
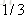
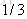
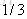


就以上面这个表利用残差找到一个最佳分类点,比如我们选s=31为分类点,则小于31的子树的均值为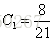
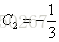
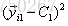
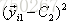
再计算: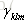
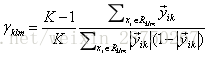


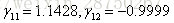
根据公式更新: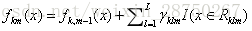
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
1.1428 |
1.1428 |
1.1428 |
1.1428 |
1.1428 |
-0.999 |
-0.999 |
-0.999 |
1.1428 |
1.1428 |
-0.999 |
-0.999 |
-0.999 |
-0.999 |
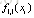
至此,迭代一次的情况下,类别A的第一棵树就拟合完毕,下面拟合类别B的迭代一次的树;
迭代一次,类别B的第一棵树:
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |

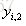
利用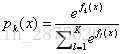
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
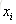
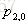
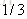
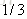
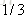
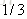
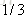
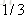
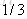
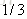
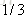
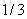
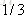
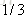
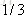
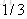
计算负梯度值,比如求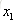

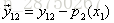
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
- |
- |
- |
- |
- |
|
|
|
|
|
- |
- |
- |
- |
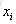
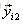
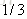
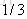
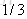
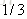
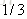

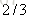
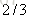
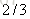

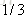
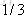
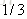
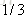
以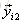

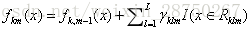
| |
6 |
12 |
14 |
18 |
20 |
65 |
31 |
40 |
1 |
2 |
100 |
101 |
65 |
54 |
| |
-0.2499 |
-0.2499 |
-0.2499 |
-0.2499 |
-0.2499 |
-0.2499 |
-0.999 |
-0.2499 |
2 |
2 |
-0.2499 |
-0.2499 |
-0.2499 |
-0.2499 |
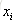

同理,再拟合第一轮中的第三棵树CART Tree3,不再重复,假如说我们只迭代一轮,如果新来一个样本X=50,那么它属于哪个类别呢,根据公式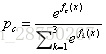
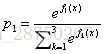

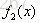
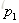
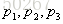
XGBoost算法:
介绍了这么多Boost算法,XGBoost算法也是Boost算法的一种;
提升树算法:
1.首先确定初始提升树
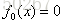
2.第二个提升树
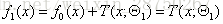
第三个提升树
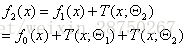
……推出:

XGBoost是GB算法的高效实现,在目标函数中显示的加上了正则化项(有的文章叫树的复杂度),基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
 ,
,
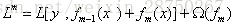
GBDT用了损失函数的负梯度
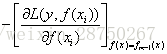
 ,对它进行二阶泰勒展开,得到:
,对它进行二阶泰勒展开,得到:

 ,其中
,其中
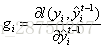
 ;
;

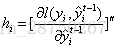
令
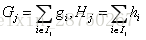
 ,到此,公式推导完成。
,到此,公式推导完成。
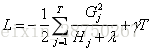
XGBoost算法的步骤和GBDT基本相同,都是首先初始化为一个常数,GBDT是根据一阶导数 ,XGBoost是根据一阶导数
,XGBoost是根据一阶导数 和二阶导数
和二阶导数 ,迭代生成基学习器,相加更新学习器。
,迭代生成基学习器,相加更新学习器。
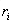

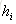
XGBoost与GBDT在实现时还做了许多优化:
l 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,XGBoost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
l XGBoost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
l 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
l 按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
l XGBoost 还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。