- Boosting
迭代提升,串行。基于弱分类器分错的样本,改变样本的概率分布构成新训练集,训练一个更强的学习器。迭代得到的一系列弱分类器,根据合并弱的学习模型来创造一个强大的学习模型。但是,只有当各模型之间没有相关性的时候组合起来后才比较强大。
(1)adaboost
不改变训练数据,迭代时提升错分样本权重,减少正确分类样本权重,最后通过加权线性组合M个弱分类器得到最终的分类器f(x)=sum(am*Gm(x))。根据分类错误率计算加权系数am,正确率越高的弱分类器的投票权数越高。
(2)gbdt
都是回归树,按照损失函数的梯度(损失函数对预测值的求导)近似的拟合残差,在残差减少的梯度方向上建立一个新的模型,串行产生树,多棵树累加和决定结果。
梯度提升决策树相对于提升树来说,“梯度”体现在利用损失函数对预测值的导数的负值(一阶导数)拟合残差(引用:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树)。
调整后可用于分类。
(3)xgboost(eXtreme Gradient Boosting极端梯度提升)
基学习器可以是回归树CART,也可以是线性分类树
在gbdt基础上做三点改进:
1、对损失函数进行泰勒展开,取得二阶导数形式,比采用一阶导数的GBDT更快。使用泰勒展开可以在不选定损失函数具体形式的情况下用于算法优化分析.本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了xgboost的适用性。
2、对结构进行正则化,抑制过拟合,正则化与叶子节点数量和叶节点值有关
3、节点分裂方式gbdt采用gini系数,xgboost进行了列采样,选择所有属性中的子集来选择最优分裂属性,降低过拟合
xgboost其他特点:
1、考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,可以自动学习出它的分裂方向
2、可在节点分裂属性选择上做并行计算(多线程进行),特征列排序后以块block的形式存储在内存中(特征列方式存储),在迭代中可以重复使用。
3、支持不放回子采样,训练模型时可从样本集合中取出一部分子样本建立模型,防止过拟合。
xgboost寻找分割点的标准是最大化Lsplit:
其中,一阶导数gi、二阶导数hi
xgboost最优特征选择:
列采样,并行计算,通过Gini指数等选择特征,通过Lsplit选择分割点,不放回子采样迭代建树。
xgboost如何评估特征:
通过特征被选中次数评分(在所有树中出现的次数之和)。
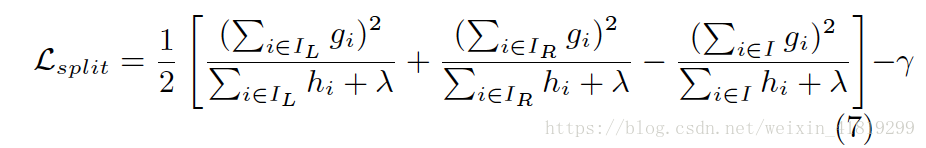
- Bagging
有放回booststrap采样,获得M个样本集合
(1)RF
bagging采样+节点属性列采样
可以是分类树或回归树,树可并行产生
补缺失值:
1、na.roughfix 同一类下的数据连续型变量补中值,分类变量补众数
2、先用na.roughfix补值,构建森林计算相似度矩阵,连续型变量,加权平均补均值;分类变量用没有缺失的观测实例的proximity(两个样本落在树的同一个叶子节点的次数)中的权重进行投票。迭代4-6次。
RF特征选择:GINI指数、信息增益、信息增益比、均方误差、方差
RF特征评估:
1、对OOB数据进行j列特征的上下置换,评估重新洗牌后测试误差的变化,对N棵树取平均。
2、对每棵树特征排序,整个森林取平均。
- Stacking
改进预测

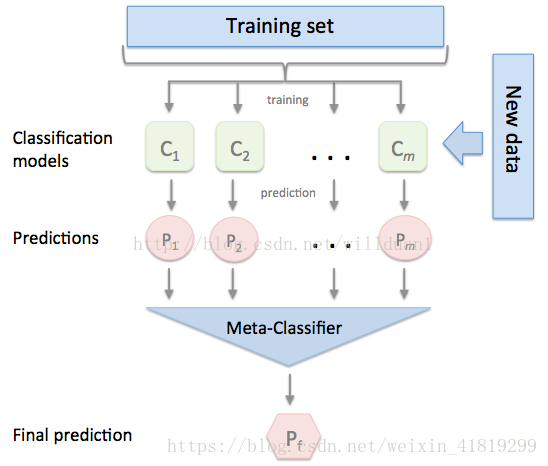
第一步:训练基分类器.在整个训练集上训练分类器Ci(基模型),共m个。通常由不同算法组成,是异构的。
第二步:对样本通过基分类器Ci,得到预测值Pi,将Pi(作为特征)和样本的分类标签组合成新的训练集。
第三步:基于新的训练集得到元分类器Meta-classifier
测试时,将基模型的预测输出作为新的测试集,对测试集进行预测。
- 区别
boosting:靠低偏差(在上一轮基础上更拟合)提高精度,基分类器需降低方差,决策树需浅
bagging: 靠低方差(并行训练多个基分类器)提高精度,基分类器需降低偏差,决策树需深
GBDT:回归树 、树串行、对异常值敏感、 减小偏差、特征归一化 、易过拟合、
未见说明 、精度高
RF :回归树/分类树、可并行、对异常值不敏感、减少方差、不需归一化(哪怕是回归问题)、不易过拟合、
大样本数据、精度低、适合决策边界的是矩阵,不适合对角线型
不归一化:决策树、RF(不关心变量的值,而是关心变量的分布和变量之间的条件概率)
归一化:adaboost、gbdt、xgboost、svm、lr、KNN、KMeans
推荐资料:
https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/